







 本文介绍了降维的目的,如数据压缩、加快算法运行速度和数据可视化,并详细阐述了主成分分析(PCA)算法,包括PCA如何找到最小化投射误差的方向向量,以及PCA的计算步骤。同时,讨论了如何选择主成分的数量,以达到平衡降维效果和保留信息的目标。
本文介绍了降维的目的,如数据压缩、加快算法运行速度和数据可视化,并详细阐述了主成分分析(PCA)算法,包括PCA如何找到最小化投射误差的方向向量,以及PCA的计算步骤。同时,讨论了如何选择主成分的数量,以达到平衡降维效果和保留信息的目标。
1降维的目的
降维是第二种机器学习算法。降维可以进行数据压缩,因而使用较少的计算机内存或磁盘空间。可以是让我们的机器学习算法运行速度变快。什么是降维?就是将数据降低维度,2维的变为1维,机器学习中有些数据集的数据的特征数量为1000多个,那么可以使用降维将数据的特征数目降低,从而使机器学习算法运行速度加快。举个例子我们收集的数据集,有很多特征

假设有两个位置额特征: 为长度单位为厘米,
用英寸表示为同一物体的长度。这两个特征是二维的,我们可以使用降维降成一维,如下所示

将数据从三维降为二维:那么就是将三维空间的点降至一个二维的特征向量。过程与上面是类似的,将三维向量投射到二维的平面上,使得所有数据都在一个平面上。如下所示

这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,例如将1000维的特征降至100维。
此外,降维可以使数据可视化。在数据集中往往有很多数据,并且大多数数据都有很多的特征值,很难可视化,可视化可以帮我们更好的寻找一个解决方案。例如一个数据集每个实例都有50个特征,那么将该数据集可视化是不可能的,但是我们可以使用降维的方法使其降至二维。这样就可以进行可视化了。
2主成分分析算法
主成分分析(PCA)是最常见的降维算法。在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。如下所示
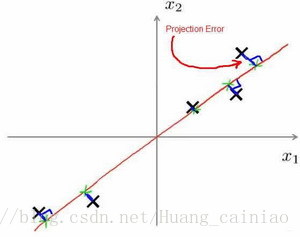
降维主要是将n维数据降至 维,目标是找到向量
使得总的投射误差最小。主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投射误差(Projected Error),而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。
PCA技术最主要的目的就是对数据进行降维的处理。我们可以根据新求出的数据的重要性进行排序,根据需要取前面最重要的部分,将后面的维数取消。这样就可以达到降维的效果。同时最大程度的保持了原有数据的信息。PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
3主成分分析算法
PCA减少 维到
维:第一步是均值归一化。我们要计算出所有特征的均值,然后令
。如果特征实在不同的数量级上,我们还需要将其除以标准差
。第二步是计算协方差矩阵(covariance matrix)
第三步是计算协方差矩阵的特征向量(eigenvectors): 在 Octave 里我们可以利用奇异值分解(singular value decomposition)来求解,
[U, S, V]= svd(sigma)。步骤如下所示


对于一个维度的矩阵,上式中的
是一个具有与数据之间最小投射误差的方向构成的矩阵。如果我们希望将数据从
维降至
维,我们只需要从
中选取前
个向量,获得一个
维度的矩阵,我们就可以用
表示,然后通过如下计算获得要求的新特征向量
。
为
维的,因此结果为
维度。
4选择主成分的数量
训练集的方差为: 。可能使用降维后的特征向量的维度还是很大,我们希望在平均均分误差与训练集方差的比例尽可能小的情况下去选择尽可能小的
值。k就是上面所述降维后的维度。具体步骤为我们可以先令
,然后进行主要成分分析,获得
和
,然后计算比例是否小于1%。如果不是的话再令
,如此类推,直到找到可以使得比例小于1%的最小
值(原因是各个特征之间通常情况存在某种相关性)。
还有一些更好的方式来选择 ,当我们在Octave中调用“svd”函数的时候,我们获得三个参数:
[U, S, V] = svd(sigma)。
获取的矩阵S如下所示

其中是一个
的矩阵,只有对角线上有值,而其他单元都为0,可以使用这个矩阵来计算平均均分误差与训练集方差的比例
也就是
如果要根据获取原来的特征数据则采用下面的方式:

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









