








使用双模单高斯模型检测运动摄像头中的运动目标
来源:2013CVPR
github链接
摘要
这篇文章提出了一种针对于运动摄像头的检测运动目标的实时检测方法,在PC上检测速度只需要5.8ms。
主要提出的创新点有:
- 使用带年龄的双模单高斯模型在运动摄像头下检测运动目标,优点是可以防止背景像素影响前景,同时让模型能够适应背景的变化
- 通过混合相邻模型来减少由于相机移动所带来的误差,并通过不断更新的age参数减少前面误差对后续的影响。
- 应用一个双模单高斯模型到多个像素,在保证效果的同时提高运行速度。
1.Introduction
运动目标检测是计算机视觉中的一个重要问题,是很多视觉任务的基础,比如人机交互、机器人视觉、智能监控系统。现阶段针对静止相机提出了很多运动目标检测的方法,但这些方法在运动相机上表现很差,因为由于相机的运动,对计算量的需求变得巨大。
现在已有的方法针对非静止相机效果很差,主要原因有:
- 计算量太大,有些方法甚至需要30-60秒处理一帧,完全达不到实时性的要求。
- 由于计算量太大,对设备要求较高,无法应用于智能手机或嵌入式系统。
- 在设计模型时没有考虑到针对非静止相机模型应用所需要的计算量,比如由于运动补偿所额外增加的计算量。比如,当Barnich和Droogenbroeck提出的背景差分法应用于非静止相机时,运动补偿程序所消耗的计算量会随着一个像素所需的样本数成比例的增加,这会显著降低算法的运算速度,甚至,运动补偿消耗的计算量会比检测还要高。
- 当对场景建模时,只考虑了静止镜头引起的噪声和误差,没有考虑非静止镜头中运动补偿所带来的误差。因此,不能简单地应用静止相机中只采用简单的运动补偿程序的背景差分算法。和静止相机针对于每个背景像素建立精确的模型不同,在非静止相机中,不能保证用于评价一个像素的模型与该像素有关。尽管是运动补偿中最小的错误,都有可能导致算法对某些像素应用错误的模型。
- 为了解决问题4所带来的误差,像素的小邻域被考虑在内,然而却增加了计算量,降低了算法的运行速度。
针对以上这些问题,本文提出了一种实时的针对运动相机检测运动目标的方法,该方法不仅能用于PC,还可用于移动设备。本文的背景模型在设计时最大程度的减小了计算量,并且有不错的检测效果。带年龄的双模单高斯模型防止这一简单的模型被前景所干扰。本文提出的模型的运动补偿不需要太多的warping计算,而是试图在模型内部修正补偿误差。结果显示,本文模型在PC上对320*240的图像可以达到5.8ms的检测速度,同时,相比于其他最好的检测模型,检测效果也是可以接受的。该模型同样可在手机上实时检测。
2.Proposed Method
本文提出的方法主要由三个部分组成:图像预处理、背景建模、运动补偿。其中,图像预处理可以减少噪声,采用简单的高斯滤波和中值滤波,背景建模采用带年龄的双模单高斯模型,运动补偿使用特殊调制过的混合模型。
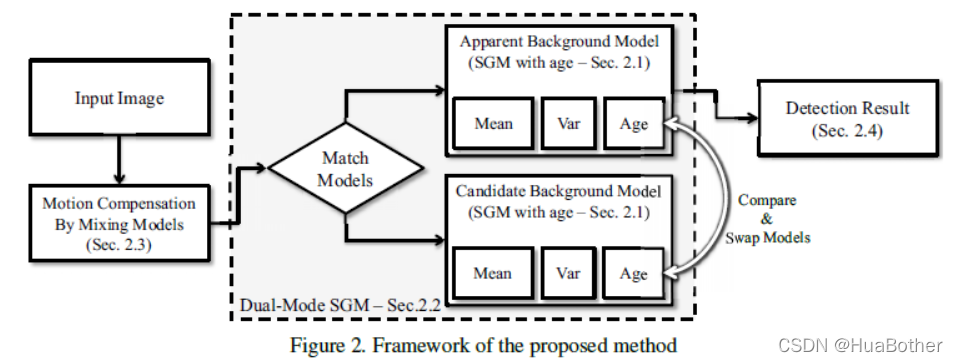
为了减少计算量,同样的模型被应用于多个像素,但这样增加误差,使用双模单高斯模型可以减少这样设置带来的误差。双模单高斯模型可以防止背景模型被前景和噪声污染,同时稳定的学习背景。运动补偿采用传统的KLT模型。但是,本文通过混合前一帧的背景模型来构造当前帧的模型,而不是简单的移动SGM到相应的位置。最终使用训练好的模型获得检测结果。
2.1 SGM model with Age
使用固定的学习率是背景差分统计模型不能用于运动相机的原因。使用固定的学习率意味着对于一个像素而言,第一次观察到的像素值会被认定成无限学习模型中该像素的平均值。在静止相机中该方法没有引起较大问题是因为在静止相机拍摄的视频中,背景像素中某个像素的值不会有太大的变化。然而对于非静止相机,无论补偿多么精确,由于运动补偿所带来的误差总是存在,因此不能假设第一次观察到的像素值接近于该像素点在观察过程中的平均值。因此需要一个变化的学习率。尽管有些人认为这样做学习率的初始化和快速收敛存在问题,但构建具有预期足够统计数据的模型也适用于非静止相机。
在充分统计的基础上,为了仅使用观察到的数据,模型保留了age、均值和方差这三个参数。同时,为了降低计算量,本文把输入图像划分为若干个N*N的网格,每个网格上采用一个SGM模型。
数学定义
G
i
(
t
)
G_{i}^{(t)}
Gi(t)表示t时刻第i个网格的像素组,
∣
G
i
(
t
)
∣
|G_{i}^{(t)}|
∣Gi(t)∣ 表示这个像素组中像素的个数
I
j
(
t
)
I_{j}^{(t)}
Ij(t)表示t时刻像素j的亮度
此时,单高斯模型中的均值、方差、年龄的更新函数为:
μ
i
(
t
)
=
α
~
i
(
t
−
1
)
α
~
i
(
t
−
1
)
+
1
μ
~
i
(
t
−
1
)
+
1
α
~
i
(
t
−
1
)
+
1
M
i
(
t
)
(1)
\tag{1} \mu_i^{(t)} = \frac {{\tilde{\alpha}}_i^{(t-1)}} {{{\tilde{\alpha}}_i^{(t-1)}}+1} {{\tilde{\mu}}_i^{(t-1)}} + \frac 1 {{{\tilde{\alpha}}_i^{(t-1)}}+1} {{M}}_i^{(t)}
μi(t)=α~i(t−1)+1α~i(t−1)μ~i(t−1)+α~i(t−1)+11Mi(t)(1)
σ
i
(
t
)
=
α
~
i
(
t
−
1
)
α
~
i
(
t
−
1
)
+
1
σ
~
i
(
t
−
1
)
+
1
α
~
i
(
t
−
1
)
+
1
V
i
(
t
)
(2)
\tag{2} {\sigma_i^{(t)}} = \frac {{\tilde{\alpha}}_i^{(t-1)}} {{{\tilde{\alpha}}_i^{(t-1)}}+1} {{\tilde{\sigma}}_i^{(t-1)}} + \frac 1 {{{\tilde{\alpha}}_i^{(t-1)}}+1} {{V}}_i^{(t)}
σi(t)=α~i(t−1)+1α~i(t−1)σ~i(t−1)+α~i(t−1)+11Vi(t)(2)
α
i
(
t
)
=
α
~
i
(
t
−
1
)
+
1
(3)
\tag{3} {\alpha_i^{(t)}} = {{\tilde{\alpha}}_i^{(t-1)}}+1
αi(t)=α~i(t−1)+1(3)
其中
M
i
(
t
)
M^{(t)}_i
Mi(t)表示t时刻一个网格内的平均亮度,
V
i
(
t
)
V^{(t)}_i
Vi(t)表示t时刻,一个网格内滑动平均亮度与最亮的像素差值的平方(不理解),表示为::
M
i
(
t
)
=
1
∣
G
i
∣
∑
j
∈
G
i
I
j
(
t
)
(4)
\tag{4} {M^{(t)}_i}=\frac 1 {|{G_i}|} \sum_{j \in {G_i}}I^{(t)}_j
Mi(t)=∣Gi∣1j∈Gi∑Ij(t)(4)
V
i
(
t
)
=
max
j
∈
G
i
(
μ
i
(
t
)
−
I
j
(
t
)
)
2
(5)
\tag{5} {V^{(t)}_i}={\max_{j \in {G_i}}}({\mu_i^{(t)}}-{I_j^{(t)}})^2
Vi(t)=j∈Gimax(μi(t)−Ij(t))2(5)
其中 μ ~ i ( t − 1 ) {\tilde{\mu}}_i^{(t-1)} μ~i(t−1), σ ~ i ( t − 1 ) {\tilde{\sigma}}_i^{(t-1)} σ~i(t−1), α ~ i ( t − 1 ) {\tilde{\alpha}}_i^{(t-1)} α~i(t−1)表示t-1时刻的SGM模型被补偿用于t时刻。
值得注意的是,(5)式替换了传统的
V
i
(
t
)
=
(
μ
i
(
t
)
−
M
i
(
t
)
)
2
(6)
\tag{6} {V^{(t)}_i}=({\mu_i^{(t)}}-{M_i^{(t)}})^2
Vi(t)=(μi(t)−Mi(t))2(6)
传统上,6式应用于网格i看上去更合理。但是,由于本文的模型被应用于多个像素,一个网格内的某些像素可能被认为是6式的异常值。因此,本文采用5式防止这种错误的前景。这个SGM模型的优点在于通过使用一个随着模型年龄变化而变化的学习率,模型可以自主降低运动补偿所带来的误差。同时,SGM的数量远小于像素数量,可以很好的降低运算量。
2.2 Dual-Mode SGM
使用一个SGM建模对于简单样本来说是比较轻松的,然而当快速学习率被应用时,背景模型就很容易被前景像素污染。本文提出的方法采用了可变学习率,因此很容易出现快速学习率。例如,初始化时,所有像素的age都是1,这意味着此时在下一帧建模时,学习率为0.5。如下图所示,快速学习率导致背景模型也描述了前景的一部分。当有大物体经过时,这一点非常明显。针对这个问题,简单的解决办法是只是用被认定为背景的像素进行更新,然而,如果这么做,针对某个像素,一个简单的错误分类将会导致模型被永久影响,因为错误的前景将永远不会被学习到为了解决这个缺点,文中使用了另一个SGM作为候选背景模型。如果这个候选模型的age比当前的模型要大,则将候选模型作为当前模型,原先的模型作为候选模型。
这种双模SGM和双模态混合高斯模型不同(GMM,Gaussian mixture models),GMM仍然会使前景污染后景,而本文的方法不会。
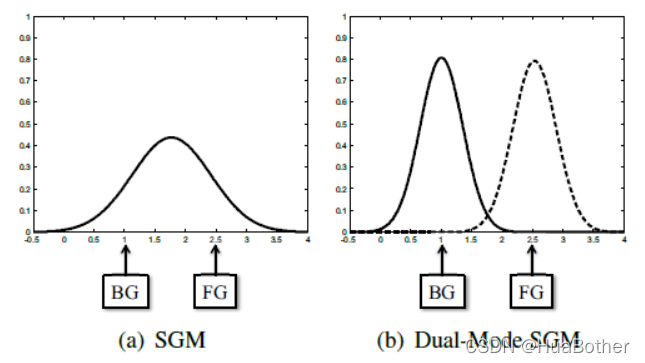
数学定义
如果把t时刻网格i的候选模型和当前模型的参数分别表示为
μ
C
,
i
(
t
)
\mu^{(t)}_{C,i}
μC,i(t),
σ
C
,
i
(
t
)
\sigma^{(t)}_{C,i}
σC,i(t),
α
C
,
i
(
t
)
\alpha^{(t)}_{C,i}
αC,i(t)和
μ
A
,
i
(
t
)
\mu^{(t)}_{A,i}
μA,i(t),
σ
A
,
i
(
t
)
\sigma^{(t)}_{A,i}
σA,i(t),
α
A
,
i
(
t
)
\alpha^{(t)}_{A,i}
αA,i(t)。当观察到的平均值
M
i
(
t
)
M^{(t)}_i
Mi(t)和
μ
A
,
i
(
t
)
\mu^{(t)}_{A,i}
μA,i(t)的平方差小于与
σ
A
,
i
(
t
)
\sigma^{(t)}_{A,i}
σA,i(t)相关的临界值时:
(
M
i
(
t
)
−
μ
A
,
i
(
t
)
)
2
<
θ
s
σ
A
,
i
(
t
)
(7)
\tag{7} (M^{(t)}_i-\mu^{(t)}_{A,i})^2 < \theta_s \sigma^{(t)}_{A,i}
(Mi(t)−μA,i(t))2<θsσA,i(t)(7)
按照式1,2,3更新当前模型的相应参数,其中
θ
s
\theta_s
θs是一个临界参数。如果不满足上述条件,同时观测到的平均值和候选背景模型相匹配,即:
(
M
i
(
t
)
−
μ
C
,
i
(
t
)
)
2
<
θ
s
σ
C
,
i
(
t
)
(8)
\tag{8} (M^{(t)}_i-\mu^{(t)}_{C,i})^2 < \theta_s \sigma^{(t)}_{C,i}
(Mi(t)−μC,i(t))2<θsσC,i(t)(8)
则按照公式1、2、3更新候选背景模型的相应参数。如果上述两个条件都不满足,则使用当前观测到的值初始化候选参考模型。每一次只有一个模型被更新,另一个模型保持原状。
更新完成后,如果满足公式9,则两个模型交换:
α
C
,
i
(
t
)
>
α
A
,
i
(
t
)
(9)
\tag{9} \alpha^{(t)}_{C,i}>\alpha^{(t)}_{A,i}
αC,i(t)>αA,i(t)(9)
候选背景模型在交换后被初始化。最后,在确定前景像素时,只使用当前的背景模型,该背景模型不会受到污染。通过双模SGM,可以防止背景模型被前景数据损坏。如上图所示,前景数据只被候选背景模型学习。此外,不必担心错误前景永远不会学习到模型中,因为如果候选背景模型的age大于当前背景模型时,模型将被交换并使用正确的背景模型。
2.3 Motion Compensation By Mixing Models
对于从非静止相机获得的图像序列,知道t-1时刻的模型都不能直接用于t时刻进行检测,因为没有进行移动补偿。由于只应用一个模型到一个网格内的所有像素,因此不能使用插值策略在背景模型中进行简单的warping运算,否则会带来大量误差。因此,本文通过合并t-1时刻的模型来构建t时刻的运动补偿模型。为了获得背景运动,作者将时间t的输入图像划分为32*24的网格,并使用t-1时刻的图像对网格的每个角执行KLT。根据这些点的追踪结果,作者使用RANSAC获得但单应性矩阵 H t : t − 1 H_{t:t-1} Ht:t−1,该矩阵通过透视变换将t时刻的所有像素扭曲为t-1时刻的像素。作者认为这是背景的运动。
进一步的解释 Further Explanation
xj表示像素j的位置,
x
ˉ
i
(
t
)
\bar{x}^{(t)}_i
xˉi(t)表示
G
i
(
t
)
G^{(t)}_i
Gi(t)的中心位置。
f
P
T
(
x
,
H
t
:
t
−
1
)
f_{PT}(x,H_{t:t-1})
fPT(x,Ht:t−1)表示x根据
H
t
:
t
−
1
H_{t:t-1}
Ht:t−1的透明变换
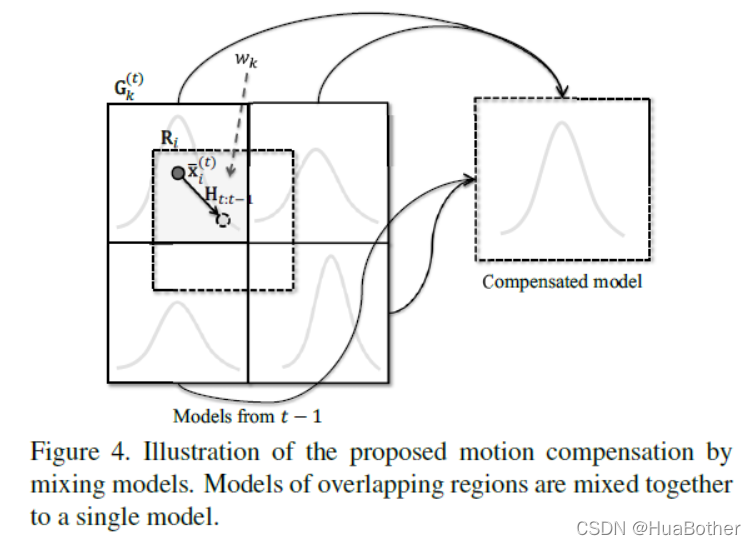
如图4所示,对于每一个网格gird i,认为
x
ˉ
i
(
t
)
\bar{x}^{(t)}_i
xˉi(t)已经从
f
P
T
(
x
,
H
t
:
t
−
1
)
f_{PT}(x,H_{t:t-1})
fPT(x,Ht:t−1)移动。这样,假设没有明显的尺度变化,如果N*N的区域Ri以
f
P
T
(
x
,
H
t
:
t
−
1
)
f_{PT}(x,H_{t:t-1})
fPT(x,Ht:t−1)为中心,t-1时刻Ri的模型将会是像素集
G
i
(
t
)
G^{(t)}_i
Gi(t)的运动补偿背景模型。Ri区域和很多网格有重叠区域,将t-1时刻这些重叠的网格的单高斯模型混合来得到运动补偿背景模型的
μ
~
i
(
t
−
1
)
{\tilde{\mu}}^{(t-1)}_i
μ~i(t−1)、
σ
~
i
(
t
−
1
)
{\tilde{\sigma}}^{(t-1)}_i
σ~i(t−1)、
α
~
i
(
t
−
1
)
{\tilde{\alpha}}^{(t-1)}_i
α~i(t−1)参数。混合的权重根据重叠的区域成比例地确定。将与Ri重叠的若干网格表示为
O
i
(
t
)
O^{(t)}_i
Oi(t),混合权重表示为
ω
k
\omega_k
ωk,其中
k
∈
O
i
(
t
)
k \in O^{(t)}_i
k∈Oi(t),于是通过简单地混合高斯模型得到背景补偿模型:
μ
~
i
(
t
−
1
)
=
∑
k
∈
O
i
(
t
)
ω
k
μ
k
(
t
−
1
)
(10)
\tag{10} {\tilde{\mu}}^{(t-1)}_i=\sum_{k \in {O^{(t)}_i}}{{\omega}_k}{{\mu}^{(t-1)}_k}
μ~i(t−1)=k∈Oi(t)∑ωkμk(t−1)(10)
σ
~
i
(
t
−
1
)
=
∑
k
∈
O
i
(
t
)
ω
k
[
σ
k
t
−
1
+
{
μ
k
(
t
−
1
)
}
2
−
{
μ
~
k
(
t
−
1
)
}
2
]
(11)
\tag{11} {\tilde{\sigma}}^{(t-1)}_i=\sum_{k \in {O^{(t)}_i}}{{\omega}_k}[\sigma^{t-1}_k+\{\mu^{(t-1)}_k\}^2-\{{\tilde\mu}^{(t-1)}_k\}^2]
σ~i(t−1)=k∈Oi(t)∑ωk[σkt−1+{μk(t−1)}2−{μ~k(t−1)}2](11)
α
~
i
(
t
−
1
)
=
∑
k
∈
O
i
(
t
)
ω
k
α
k
(
t
−
1
)
(12)
\tag{12} {\tilde{\alpha}}^{(t-1)}_i=\sum_{k \in {O^{(t)}_i}}{{\omega}_k}{\alpha^{(t-1)}_k}
α~i(t−1)=k∈Oi(t)∑ωkαk(t−1)(12)
其中,混合权重为:
ω
k
∝
A
r
e
a
{
R
i
∩
G
k
(
t
)
}
(13)
\tag{13} \omega_k \propto Area \{R_i \cap G^{(t)}_k\}
ωk∝Area{Ri∩Gk(t)}(13)
∑
k
ω
k
=
1
(14)
\tag{14} \sum_k{\omega_k}=1
k∑ωk=1(14)
注意,11式中
{
μ
k
(
t
−
1
)
}
2
−
{
μ
~
k
(
t
−
1
)
}
2
\{\mu^{(t-1)}_k\}^2-\{{\tilde\mu}^{(t-1)}_k\}^2
{μk(t−1)}2−{μ~k(t−1)}2的值是存在的,因为当融合多个高斯模型为一个时,与权重
ω
k
\omega_k
ωk融合的是观察平方的期望值,而不是方差。通过混合步骤,附近区域差异很大(例如物体的边缘)的模型在补偿后会有更大的方差。通常情况下,一个SGM不会有太大的方差,如果有,则证明模型没有很好的学习到目标特征。因此,在补偿后,如果方差超过临界值
θ
v
\theta_v
θv即
σ
~
i
(
t
−
1
)
>
θ
v
{\tilde\sigma}^{(t-1)}_i>\theta_v
σ~i(t−1)>θv,则需要减小模型的age:
α
~
i
(
t
−
1
)
←
α
~
i
(
t
−
1
)
e
x
p
{
−
λ
(
σ
~
i
(
t
−
1
)
−
θ
v
)
}
(15)
\tag{15} {\tilde\alpha}^{(t-1)}_i \gets {\tilde\alpha}^{(t-1)}_i exp\{-\lambda({\tilde\sigma}^{(t-1)}_i-\theta_v)\}
α~i(t−1)←α~i(t−1)exp{−λ(σ~i(t−1)−θv)}(15)
其中
λ
\lambda
λ是一个衰败参数。通过对age的衰减,可以阻止模型拥有过大的方差。这可以很好的去除边缘附近的虚假前景。
2.4 Detection of Foreground Pixels
在前面几章获得t时刻的背景模型后,将与平均值差异较大(大于某个临界值)的像素点作为前景。理论上针对这个问题,这不是一个精确的解决方法,应该找到相对于学习到的背景模型作为背景的概率较低的像素。然而,由于精确方程中的平方根运算和自然对数运算,找到这样的像素需要更多的计算量。作者凭经验发现,对方差进行简单的阈值处理,结果也是可用的,不需要复杂计算。在数学上,对于第i个像素集中的像素j,如果
(
I
j
(
t
)
−
μ
A
,
i
(
t
)
)
2
>
θ
d
σ
A
,
i
(
t
)
(16)
\tag{16} (I^{(t)}_j-\mu^{(t)}_{A,i})^2>\theta_d\sigma^{(t)}_{A,i}
(Ij(t)−μA,i(t))2>θdσA,i(t)(16)
则将此像素认定为前景像素,其中,
θ
d
\theta_d
θd是临界值。注意,只用当前背景模型决定前景。通过这种方式可以避免背景模型受到污染导致的错误背景。
3.Experments
作者使用C++和OpenCV3提供的KLT实现。具体的参数设置:
网格大小 N=4;匹配阈值
θ
s
\theta_s
θs=2;age的衰减参数
λ
\lambda
λ=0.001;age衰减阈值
θ
v
=
50
∗
50
\theta_v=50*50
θv=50∗50;确定前景的检测阈值
θ
d
=
4
\theta_d=4
θd=4。
对于方差的初始化,使用一个中等的值,比如20*20,age最大为30以保证最低的学习率。
作者在Intel Core i5-3570 3.4GHz PC对320*240的视频进行检测达到的效果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









