







可靠传输实现机制
确认应答
这是保证可靠性的最核心机制
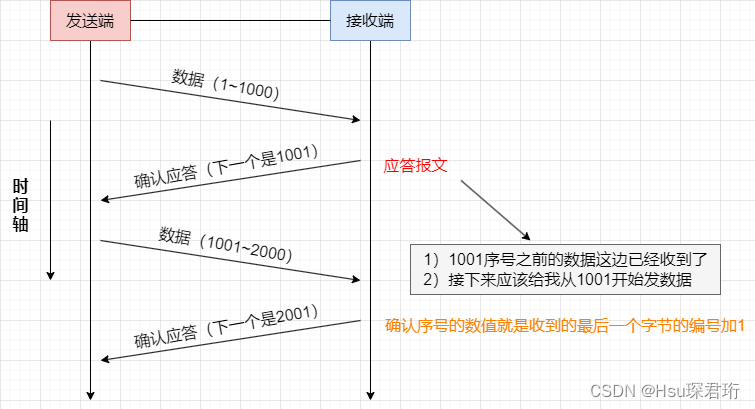
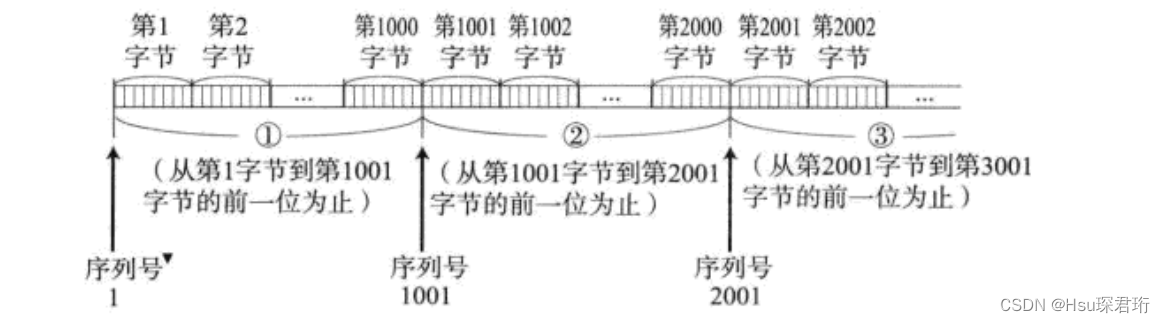
TCP将每个字节的数据都进行了编号。即为序列号。
这是为了防止连续发多条数据的时候,可能出现“后发先至”的情况,也就是为了可靠性传输
由于TCP是面向字节流的,不是以“条”为单位来传输的。这里是第一条11000,第二条10012000,也可以第一条11500,第二条15012000。
- 是针对字节编号的,不是针对“条”
- 应答报文也是要和收到的数据的序号相关联的,但不是“相等”
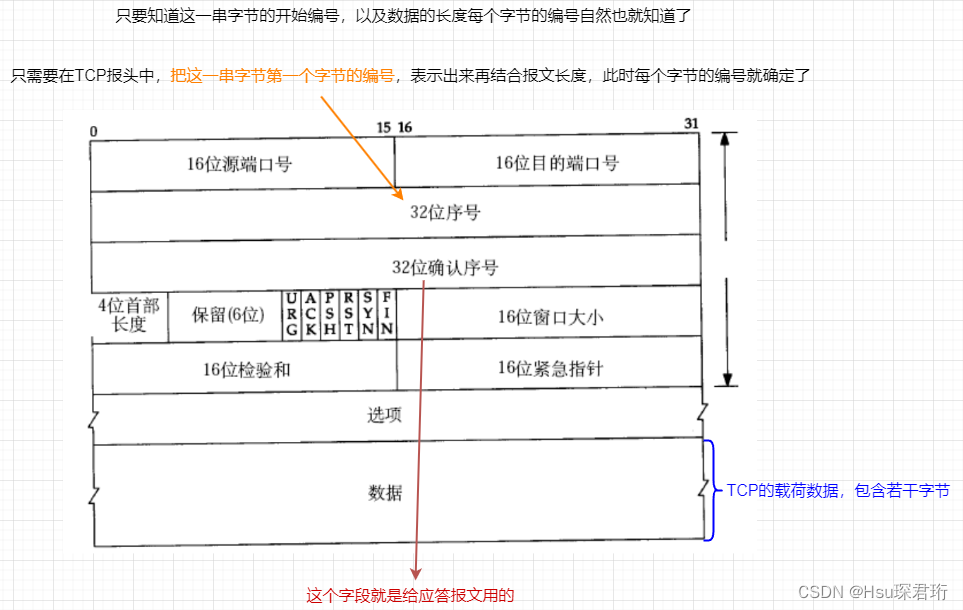
此时就需要有办法区分出当前的这个报文是普通报文还是应答报文
就用到了6位标志位中的 ACK
ACK 为 0 表示这是一个普通的报文。此时只有 32 位序号是有效的
ACK 为 1 表示这是一个应答报文,这个报文的 序号 和 确认序号 都是有效的
ACK => acknowledge 应答
每一个ACK都带有对应的确认序列号,意思是告诉发送者,我已经收到了哪些数据;下一次你从哪里开始发。
TCP报文中,开始序号+长度-1 => 最后一个序号(但TCP报文中,没有保存最后一个序号,只有开始序号,但可以通过这样算)
核心一句话:确认应答,是TCP保证可靠性的最核心机制。而超时重传是TCP可靠性机制的有效补充
网络上说TCP保证可靠性的核心机制是“三次握手”,这是错的!!!
超时重传
丢包,在网络上很可能出现发一个数据然后丢了
网络传输过程中,路由器/交换机是“交通枢纽”。如果设备太繁忙,后面新来的数据等太久了,就可能被丢弃了,网络负载越高,越繁忙,就越容易被丢包
举例:你发信息给别人,信息发丢了但你不知道,但你知道你没有收到应答,因此你就会重新发一次
而超时重传,就是等待一定时间,超过一定的时间之后,再进行重传。
超时重传相当于针对确认应答,进行的重要补充
发的信息本身丢包了
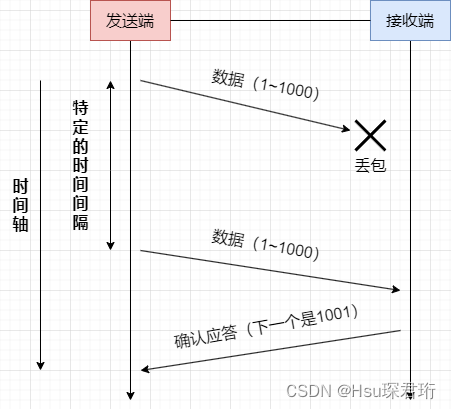
发送端发送数据给接收端之后,可能因为网络拥堵等原因,数据无法到达接收端;
如果发送端在一个特定时间间隔内没有收到接收端发来的确认应答,就会进行重发;
但是,发送端未收到接收端发来的确认应答,也可能是因为ACK丢失了;
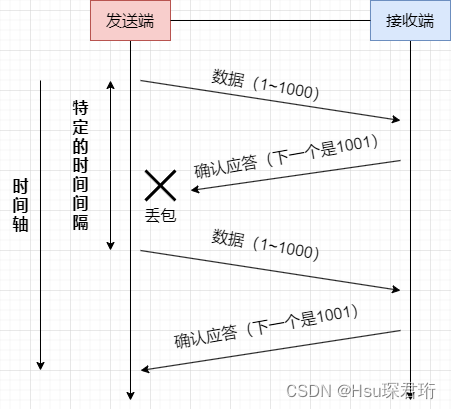
因此接收端会收到很多重复数据。那么TCP协议需要能够识别出那些包是重复的包,并且把重复的丢弃掉。
这时候我们可以利用前面提到的序列号,就可以很容易做到去重的效果。
以上两种情况无法区分,那就只能都重传咯~~
那么,如果超时的时间如何确定?
最理想的情况下,找到一个最小的时间,保证 “确认应答一定能在这个时间内返回”。
但是这个时间的长短,随着网络环境的不同,是有差异的。
如果超时时间设的太长,会影响整体的重传效率;
如果超时时间设的太短,有可能会频繁发送重复的包;
TCP为了保证无论在任何环境下都能比较高性能的通信,因此会动态计算这个最大超时时间。
Linux中(BSD Unix和Windows也是如此),超时以500ms为一个单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍。
如果重发一次之后,仍然得不到应答,等待 2*500ms 后再进行重传。
如果仍然得不到应答,等待 4*500ms 进行重传。依次类推,以指数形式递增。
重传次数达到一定程度,此时就会尝试“重置”TCP连接,TCP复位报文,是6位标志位中的RST,如果为1就是一个复位报文就尝试重新连接了
累计到一定的重传次数&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









