







 本文介绍了M-P模型,这是模仿人脑神经元结构的一种模型,并详细解释了其与生物神经元的对应关系。同时,文章还探讨了几种常见的激活函数,包括BinaryStep、线性函数、Sigmoid、tanh和ReLU,分析了它们的优缺点及适用场景。
本文介绍了M-P模型,这是模仿人脑神经元结构的一种模型,并详细解释了其与生物神经元的对应关系。同时,文章还探讨了几种常见的激活函数,包括BinaryStep、线性函数、Sigmoid、tanh和ReLU,分析了它们的优缺点及适用场景。
1. M-P模型(阈值加和模型)
M-P模型实际上是模拟人脑中单个神经元结构
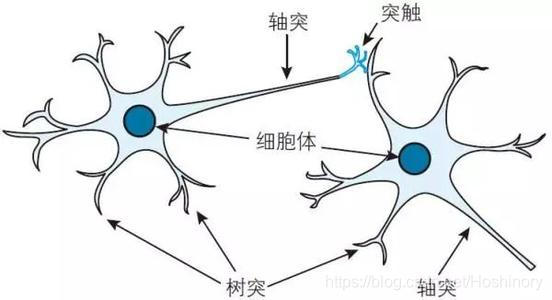
生物神经元细胞如图所示:
M-P模型结构如图所示:
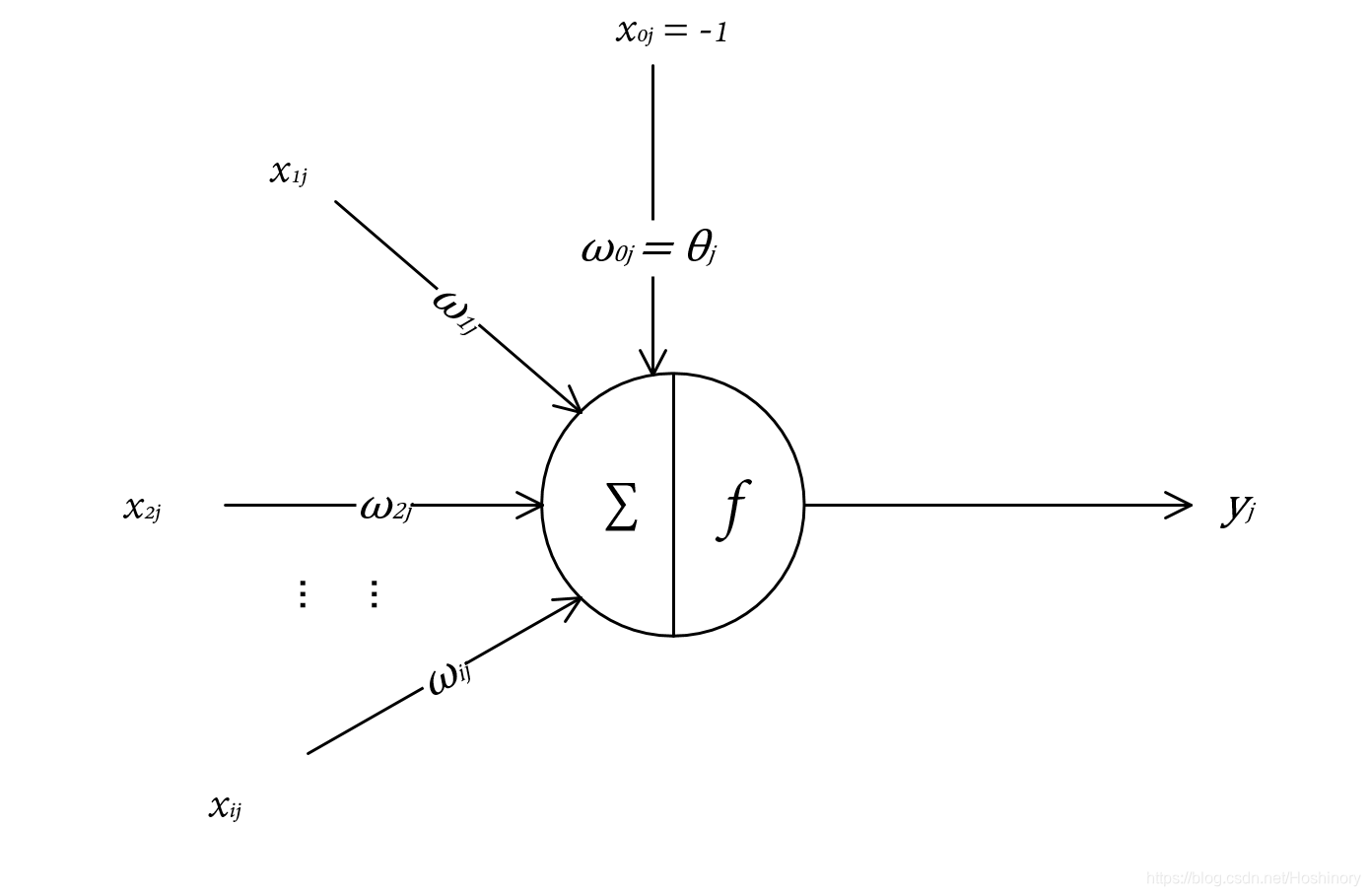
对比生物神经元结构与M-P模型,有如下对应关系:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 神经元结构 | 第 i i i个输入神经元 | 第 j j j个接收神经元 | 第 i i i神经元输入到第 j j j个神经元的信号 | 权重(连接强度) | 阈值 | 总的膜电位 | 第 j j j个神经元的信号输出 |
| M-P模型 | i i i | j j j | x i j x_{ij} xij | ω i j \omega_{ij} ωij | θ j \theta_{j} θj | ∑ i = 1 m x i j ω i j − θ j \sum_{i=1}^{m}x_{ij}\omega_{ij}\ - \ \theta_{j} ∑i=1mxijωij − θj | y j = f ( ∑ i = 1 m x i j ω i j − θ j ) y_{j} = f(\sum_{i=1}^{m}x_{ij}\omega_{ij}\ - \ \theta_{j}) yj=f(∑i=1mxijωij − θj) |
生物神经元接受来自多个不同树突的电信号输入(电信号有兴奋和抑制的区别),通过神经元细胞整合后,由轴突输出。
对于M-P模型:
x
i
j
x_{ij}
xij表示第
j
j
j个神经元接受来自第
i
i
i个神经元的输入信号大小,
θ
j
\theta_{j}
θj表示第
j
j
j个神经元的阈值,
ω
i
j
\omega_{ij}
ωij表示连接的强弱,如果将总的膜电位加和就有
∑
i
=
1
m
x
i
j
ω
i
j
−
θ
j
\sum_{i=1}^{m}x_{ij}\omega_{ij}\ - \ \theta_{j}
∑i=1mxijωij − θj,通过激活函数
f
(
⋅
)
f(·)
f(⋅),就能得到神经元
j
j
j的输出
y
j
y_{j}
yj。
激活函数选取需要注意的性质:
非线性:当激活函数为非线性的时候,可以证明两层的神经网络可以逼近任意复杂的函数。
连续可微:由于神经网络的训练是基于梯度的优化方法,因此要求激活函数连续可微。
范围:当激活函数的取值有限时,特征的表示受有限权重的影响更显著,依仗梯度的方法会更加稳定;反之,特征的表示会则显著影响大部分权重,训练效率会更高,因此采用较小的Learning-rate就能达到目的。
单调性:如果激活函数在原点附近恒有
f
(
x
)
=
x
f(x) = x
f(x)=x即
f
′
(
0
)
=
1
f^{'}(0) = 1
f′(0)=1,且
f
′
(
x
)
f^{'}(x)
f′(x)在0点连续,则使用小的随机值初始化权值就能高效地训练神经网络;反之,则需要谨慎选取初始化权值。
下面介绍几种常用的激活函数
f
(
⋅
)
f(·)
f(⋅):
(1)Binary Step函数
f
(
x
)
=
{
1
,
i
f
x
≥
0
0
,
i
f
x
<
0
f(x) = \begin{cases} 1, & if \quad x \geq 0 \\ 0, & if \quad x < 0 \end{cases}
f(x)={1,0,ifx≥0ifx<0
其优点是简单实用,可用于而分类问题,但是由于
f
′
(
x
)
=
0
,
f
o
r
a
l
l
x
∈
R
f^{'}(x) = 0, for\ all\ x \in R
f′(x)=0,for all x∈R均成立,因此无法用于依仗梯度的逆向传播机制。
(2)线性函数
f
(
x
)
=
ω
T
x
+
b
,
x
∈
R
f(x) = \boldsymbol{\omega}^{T}x + b , x\in R
f(x)=ωTx+b,x∈R
优点是激活输出值与输入成正比,但由于其梯度
f
′
(
x
)
=
ω
f^{'}(x)= \boldsymbol{\omega}
f′(x)=ω,与
x
x
x无关,因此无论神经网络有多少层,其输出都只是一个线性变换而且无法减少误差,因此同样也不能用于逆向传播网络中。
(3)
S
i
g
m
o
i
d
Sigmoid
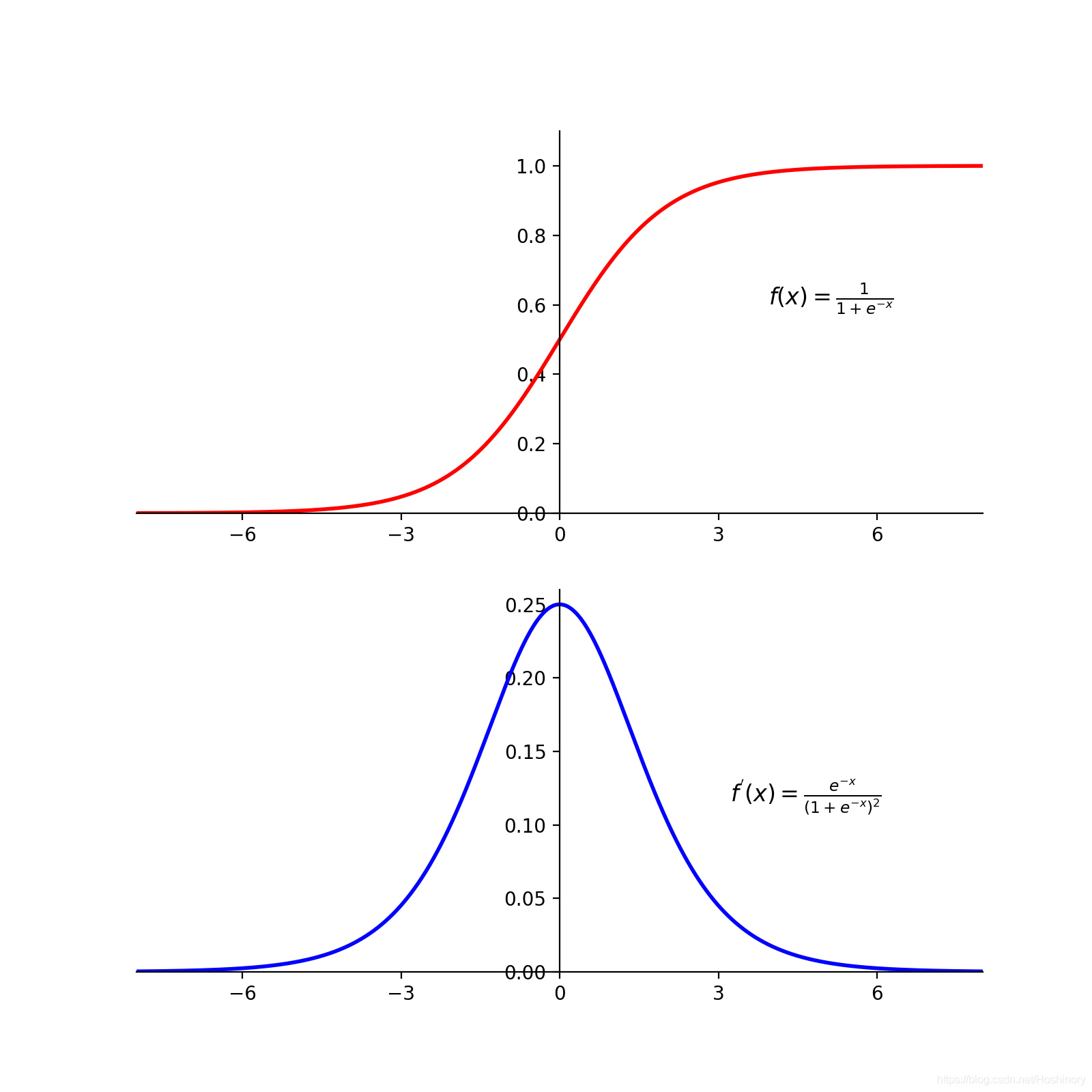
Sigmoid函数
f
(
x
)
=
1
1
+
e
−
x
,
x
∈
R
f(x) = \frac{1}{1 + e^{-x}}\ , x\in R
f(x)=1+e−x1 ,x∈R
其优点是非线性,处处连续可微,值域
f
(
x
)
∈
(
0
,
1
)
f(x) \in (0,\ 1)
f(x)∈(0, 1),且
f
′
(
x
)
=
f
(
x
)
(
1
−
f
(
x
)
)
f^{'}(x) = f(x)(1 - f(x))
f′(x)=f(x)(1−f(x)),缺点是计算耗时,容易出现梯度消失问题,
lim
x
→
±
∞
f
′
(
x
)
→
0
\lim_{x \to \pm \infty }f^{'}(x) \to 0
limx→±∞f′(x)→0,
max
f
′
(
x
)
=
0.25
\max \ f^{'}(x) = 0.25
max f′(x)=0.25,根据链式法则,逆向传过来的梯度至少会缩小到原来的
1
4
\frac{1}{4}
41,层数越多梯度会越趋近于0,而且函数输出并不是Zero-Centered, 因为
f
(
x
)
>
0
f
o
r
a
l
l
x
∈
R
f(x) > 0\ for \ all \ x \in R
f(x)>0 for all x∈R。
(4)
t
a
n
h
tanh
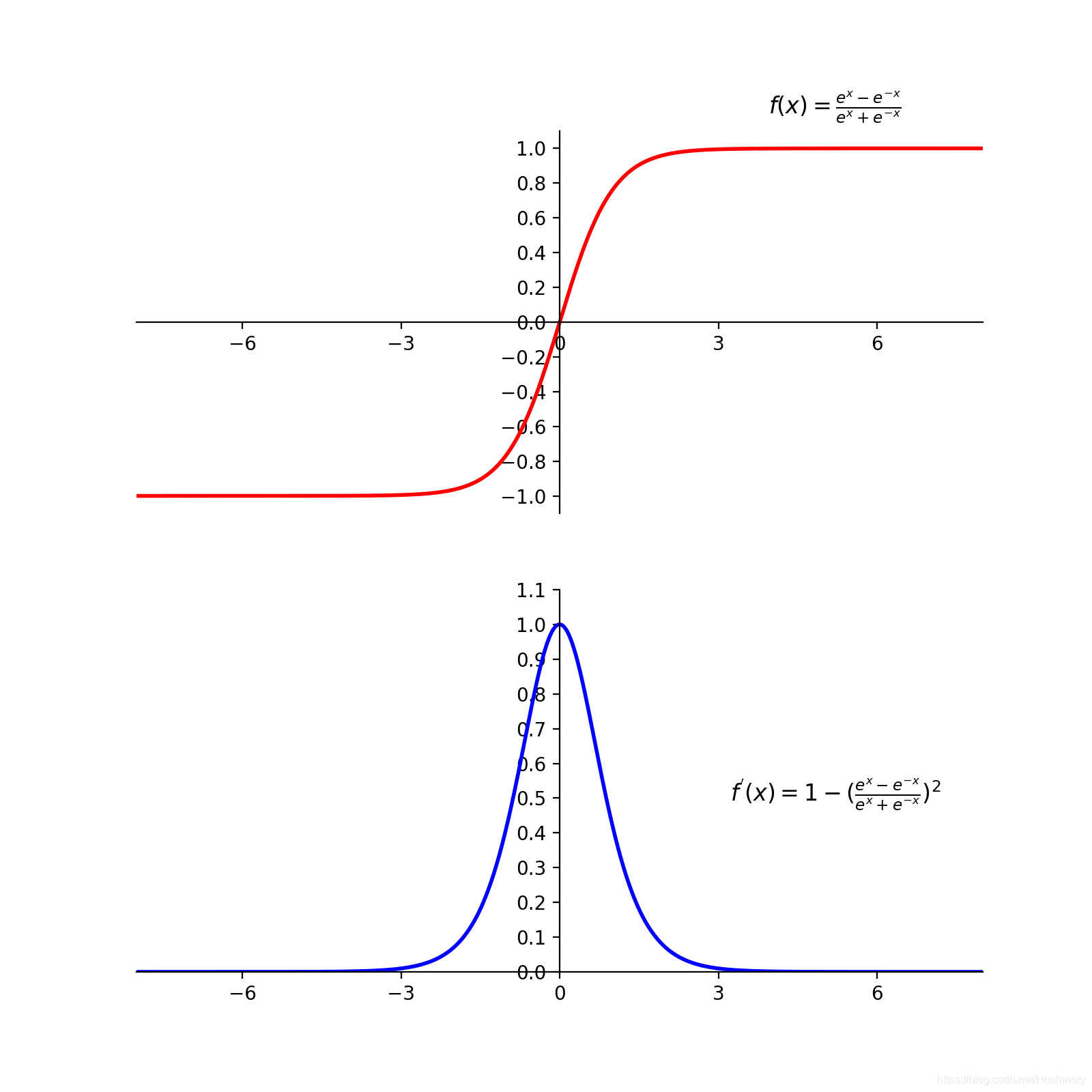
tanh函数
f
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
,
x
∈
R
f(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}, x\in R
f(x)=ex+e−xex−e−x,x∈R
具有
S
i
g
m
o
i
d
Sigmoid
Sigmoid函数的优点,
f
(
x
)
∈
(
−
1
,
1
)
f(x) \in (-1,\ 1)
f(x)∈(−1, 1),其
f
′
(
x
)
=
1
−
f
2
(
x
)
f^{'}(x) = 1 - f^{2}(x)
f′(x)=1−f2(x),与
S
i
g
m
o
i
d
Sigmoid
Sigmoid函数缺点相似,
lim
x
→
±
∞
f
′
(
x
)
→
0
\lim_{x \to \pm \infty }f^{'}(x) \to 0
limx→±∞f′(x)→0,因此也会出现梯度消失问题。
(5)
R
e
L
U
ReLU
ReLU函数
f
(
x
)
=
max
(
0
,
x
)
,
x
∈
R
f(x) = \max (0,\ x), \ x \in R
f(x)=max(0, x), x∈R
不会出现梯度消失问题,运算速度快,收敛性远高于
S
i
g
m
o
i
d
Sigmoid
Sigmoid和
t
a
n
h
tanh
tanh函数,但是输出不是Zero-Centered,而且某些神经元可能永远不会被激活,导致相应的参数永远不被更新,主要是Learning-rate过高,梯度更新过快导致的。

















 9963
9963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









