




写在前面
近几日使用pytorch时对其方法大致有两种:
一、使用Sequential顺序块,在这个块内部定义顺序执行的每一层网络和内部参数,这样做可以不用自己定义继承的forward前向传播方法。但是相应的,灵活性不是很高
二、继承pytorch的module类,重新定义其中的初始化网络方法和前向传播函数。
对于第二种,明显是我想使用的方法。然后为此学习了一下python面向对象编程的知识,具体知识和写代码完成的简单练习之后我会写出来。
然后也因此我基本上搞明白了pytorch构建网络模型的方法和含义还有怎么写,具体的我会这几天写出来,尤其是继承类以后每一步需要干什么。
这两部分内容我会在最近三到五天写出来发布。
本文目的和近日问题
在学习完成前面章节后,尝试进行了一维卷积神经网络进行建模,但是遇到了问题。下面是这几天的总结。
这几天我经历了无数次卷积神经网络的报错,尤其在数据格式方面,比如一维卷积网络中输入需要(样本数或者批大小,通道=1,特征数=561)但是实际情况中,我按照这个输入,reshape了train_X,但是对于(8000,1,561)的输入,在计算损失函数时,应该和一个8000个labels进行对比。但是提示要一个4000的labels而不是8000,也曾尝试(8000,1)和(2,4000)等各种形式,均出现各种错误。然后,查阅一些资料,尝试了使用x = x.unsqueeze(1)来讲(8000,561)拉成(8000,1,561),居然就可以了。其中具体原因我还不知道,如果有人知道可以私信告诉我,感激不尽。
结论就是,尽量使用x = x.unsqueeze(1)来改变数据格式,而不是自己reshape。当然可能在后面的处理中会被打脸。
上面最后代码跑通也是今天尝试,并未对其进行调优。在这个疯狂报错的虐心过程中,我中途完成了一个在之前softmax基础上,构建的多层感知机模型,效果良好。
多层感知机模型(飞浆得分95.15)
首先,先夸一下这个项目数据集的提供者,完全已经处理好了数据,我使用标准化方法和不使用标准化方法得分一样。(上次也介绍过,这个数据集提供者已经进行了特征处理和标准化)
这个多层感知机中共有四个全连接层,最终输出六个分类,下面是代码:其中导入块是好多个模型都需要的块,一次性导入。每次都需要就都放一起了
#先导入块
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
from sklearn.metrics import roc_auc_score
import pandas as pd
import numpy as np
%pylab inline
import seaborn as sns
#先提取特征集合、标签
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
train_df['Activity'] = train_df['Activity'].map({
'LAYING': 0,
'STANDING': 1,
'SITTING': 2,
'WALKING': 3,
'WALKING_UPSTAIRS': 4,
'WALKING_DOWNSTAIRS': 5
})
train_X = train_df.iloc[:,0:561] #提取特征集
train_Y = train_df['Activity'] #提取标签
#数据标准化
scaler = StandardScaler()
train_X = scaler.fit_transform(train_X)
test_X = scaler.transform(test_df)
# 转换成PyTorch张量
train_X = torch.tensor(train_X, dtype=torch.float32)
train_Y = torch.tensor(train_Y, dtype=torch.long)
test_X = torch.tensor(test_X, dtype=torch.float32)
#构建网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(561, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 64)
self.fc4 = nn.Linear(64, 6)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = self.fc4(x)
x = self.softmax(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
#训练模型
for epoch in range(100):
running_loss = 0.0
optimizer.zero_grad()
outputs = net(train_X)
loss = criterion(outputs,train_Y)
loss.backward()
optimizer.step()
running_loss += loss.item()
#对测试样本进行预测
test_inputs = test_X
with torch.no_grad():
test_outputs = net(test_inputs)
_, predicted = torch.max(test_outputs.data, 1)
print('Predictions:', predicted)
#结果转换和保存
predicted=np.array(predicted)
predicted = pd.DataFrame(predicted,columns=["Activity"])
predicted['Activity'] = predicted['Activity'].map({
0:'LAYING',
1:'STANDING',
2:'SITTING',
3:'WALKING',
4:'WALKING_UPSTAIRS',
5:'WALKING_DOWNSTAIRS'
})
predicted.to_csv('submission.csv', index=None)
!zip submission.zip submission.csv然后尝试了用一维卷积神经网络(得分89.35分)
先介绍一下一维卷积神经网络的数学计算
由于很多教材卷积神经网络基本上都是处理三维的图片来距离,而一维的特征向量和构造却谈及甚少。
查阅众多资料,下面这篇介绍很棒:
https://blog.youkuaiyun.com/perfect_csdn1/article/details/116862691
介绍了一维卷积的三种计算方法。和多通道输入输出。
正如开头所说即使是一维也很难控制特征和输入标签,期间报错真的很多。
下面是解决了问题的代码:
#导入模块和上面一样,这里不再重复
#先提取特征集合、标签
train_X = train_df.iloc[:,0:561] #提取特征集
train_Y = train_df['Activity'] #提取标签
#数据标准化
scaler = StandardScaler()
train_X = scaler.fit_transform(train_X)
test_X = scaler.transform(test_df)
# 转换成PyTorch张量
train_X = torch.tensor(train_X, dtype=torch.float32)
train_Y = torch.tensor(train_Y, dtype=torch.long)
test_X = torch.tensor(test_X, dtype=torch.float32)
#网络构建
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv1d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)
self.pool1 = nn.MaxPool1d(kernel_size=2, stride=2)
self.conv2 = nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)
self.pool2 = nn.MaxPool1d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(32 * 140, 256)
self.fc2 = nn.Linear(256, 64)
self.fc3 = nn.Linear(64, 6)
def forward(self, x):
#将张量x的维度从(a,b)变成(a,1,b)。即在第二个维度上增加一个维度,使得原本的每个元素变为一个包含一个元素的张量。
x = x.unsqueeze(1)
x = self.conv1(x)
x = nn.functional.relu(x)
x = self.pool1(x)
x = self.conv2(x)
x = nn.functional.relu(x)
x = self.pool2(x)
x = x.view(-1, 32 * 140)
x = self.fc1(x)
x = nn.functional.relu(x)
x = self.fc2(x)
x = nn.functional.relu(x)
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
#模型训练
for epoch in range(50):
running_loss = 0.0
inputs=train_X
labels = train_Y
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, train_Y)
loss.backward()
optimizer.step()
running_loss += loss.item()
if(epoch%10==0):
print("第",epoch,"轮训练")
#模型预测
with torch.no_grad():
inputs=test_X
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
#结果转换和保存
print(predicted)
predicted=np.array(predicted)
predicted = pd.DataFrame(predicted,columns=["Activity"])
predicted['Activity'] = predicted['Activity'].map({
0:'LAYING',
1:'STANDING',
2:'SITTING',
3:'WALKING',
4:'WALKING_UPSTAIRS',
5:'WALKING_DOWNSTAIRS'
})
predicted.to_csv('submission.csv', index=None)
!zip submission.zip submission.csv结果展示
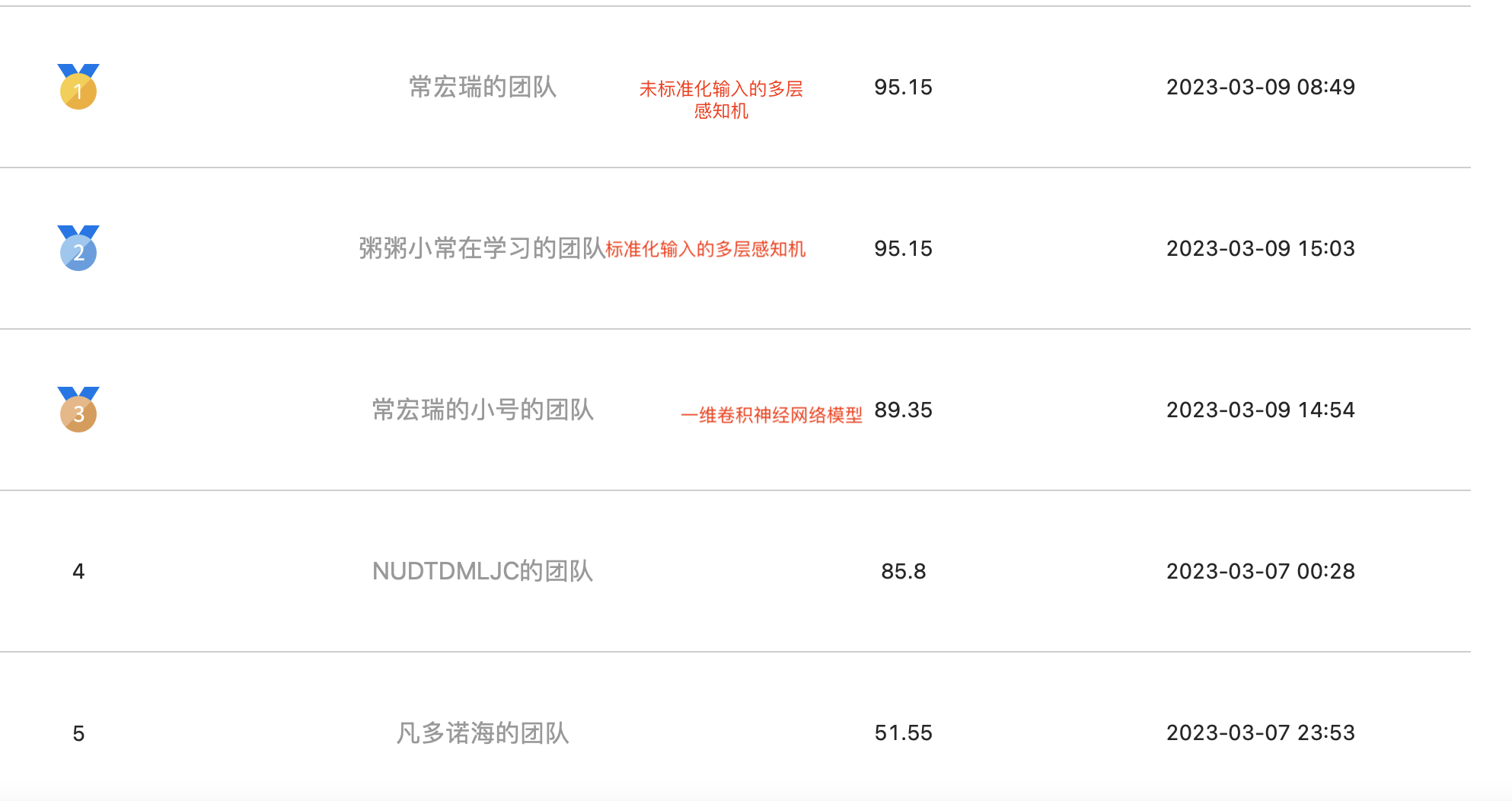
由于今天一次性跑通了代码,并且进行一些尝试,多注册了俩小号来提交观察结果。
下一步工作思考和任务方向
一、继续学习,尤其是希望学到一维卷积神经网络如何才能更优化,参数设置怎么更合理更好。
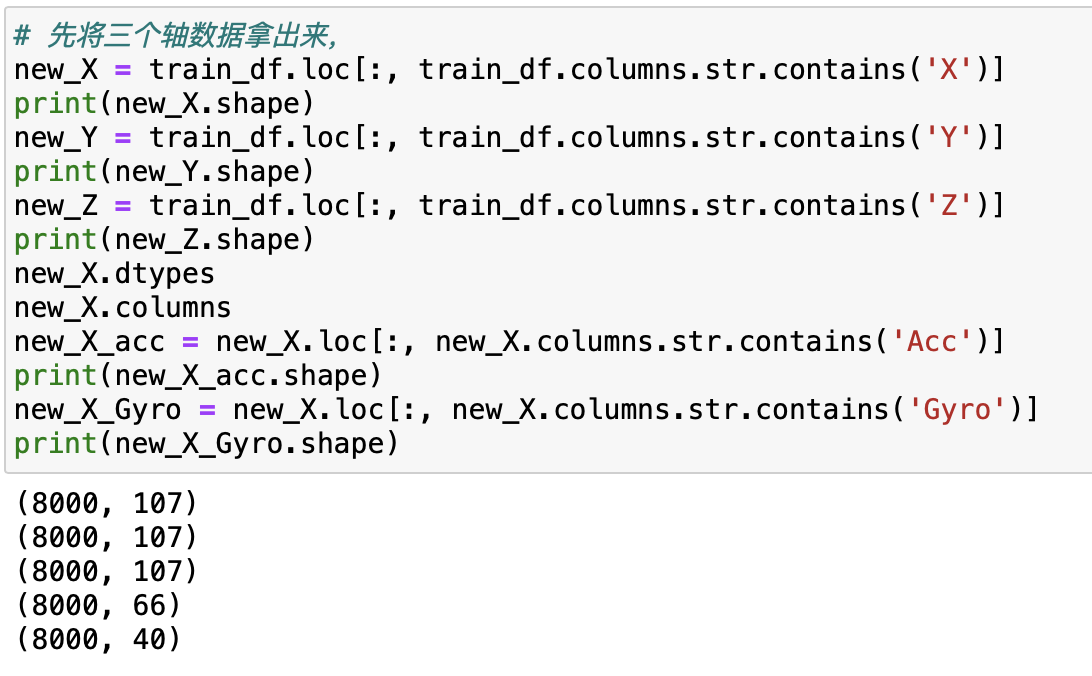
二、处理过程中发现X,Y,Z三个方向的变量各有66个水平轴数据和40个角动量数据,还有一个综合数据,561-107*3=220,还有220个其他数据。接下来有两种预想:
尝试直接将数据X,Y,Z轴当成类似RGB三个通道,并且进行边缘填充,构造一个(8000,3,12,13)的张量作为输入。使用二维,也就是正常的卷积神经网络进行尝试。
优化一维卷积神经网络模型
三、下一步任务
继续学习卷积神经网络,接上之前的学习,学习经典的卷积神经网络。
学习循环神经网络,探究处理手机行为识别问题的可能性。
学习优化算法。
把开头提到的pytorch编写代码的理解过程和python面向对象编程的学习写出来。



















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











