




 本文详细介绍了YOLOv5的架构和工作原理,包括输入预处理、CSPDarknet53主干网络、多尺度特征融合、预测头部与损失函数。通过在COCO128数据集上对比YOLOv5n和YOLOv5s的实验,展示了模型在不同规模和性能之间的平衡。
本文详细介绍了YOLOv5的架构和工作原理,包括输入预处理、CSPDarknet53主干网络、多尺度特征融合、预测头部与损失函数。通过在COCO128数据集上对比YOLOv5n和YOLOv5s的实验,展示了模型在不同规模和性能之间的平衡。
目录
· YOLOv5简介
· 总结
YOLOv5简介
YOLOv5是一种高效、实时的目标检测算法,其设计理念秉承“一次看(You Only Look Once)”原则,旨在实现高效率与准确性之间的平衡。相较于传统的多阶段检测方法,YOLOv5采用端到端的单阶段框架,直接从整幅图像中预测边界框及其对应的类别概率,从而大大提升了推理速度。
一、输入与预处理
YOLOv5接收原始图像作为输入,首先对其进行尺度调整、归一化等预处理操作,确保数据的一致性和适配性。这一阶段可能还包括特定的数据增强技术,如Mosaic拼接,这是一种创新的数据增广手段,通过随机选取四张图像并按照一定规则拼接成一幅新的复合图像,有效模拟了复杂场景布局和目标尺度多样性,显著提升了模型的泛化性能。
二、特征提取主干网络(Backbone)
YOLOv5采用了一种轻量级且计算高效的Backbone结构:CSPDarknet53以提取图像的多层级特征表示。Backbone通常采用跨阶段局部连接(Cross-Stage Partial Network, CSP)结构来减少计算复杂度,同时保持对目标特征的有效捕捉。
三、多尺度特征融合
在Backbone之后,YOLOv5构建了一个多层次的特征金字塔结构,通过融合不同深度的特征图,确保模型对不同尺度目标的敏感度。这一过程可能涉及SPP(空间金字塔池化)模块,它通过不同大小的池化窗口提取多尺度上下文信息;或者PANet(路径聚合网络),它通过自底向上和自顶向下的信息传递路径实现跨尺度特征交互。
四、多尺度预测头部(Head)与损失函数
YOLOv5设计了多个预测头部,每个头部负责在不同尺度的特征图上生成候选边界框(Anchor boxes)并预测其属性。这些属性包括边界框的中心坐标、宽高、类别概率以及一个表示框内是否存在物体的置信度得分。模型采用多任务损失函数进行联合训练,包括:
分类损失:衡量模型对每个候选框所属类别的预测准确度,通常采用交叉熵损失。
定位损失:用于优化边界框位置的回归,YOLOv5采用改进的IoU损失函数,如GIoU或CIoU,它们考虑了预测框与真实框的重叠区域及非重叠区域,提高了回归的稳定性。
置信度损失:鼓励模型准确估计候选框内是否包含目标物体。
五、模型变种与扩展应用
YOLOv5提供多个模型规模版本(n、s、m、l、x),允许用户根据实际任务需求在精度与速度之间进行权衡。这些变种通过调整网络深度(depth_multiple)和宽度(width_multiple)参数来改变模型复杂度。此外,YOLOv5的结构灵活性使得其易于适应特定领域的定制与改进,例如通过添加任务相关的层、修改损失函数或调整网络结构以应对特定物体检测任务。
YOLOv5的总体结构图
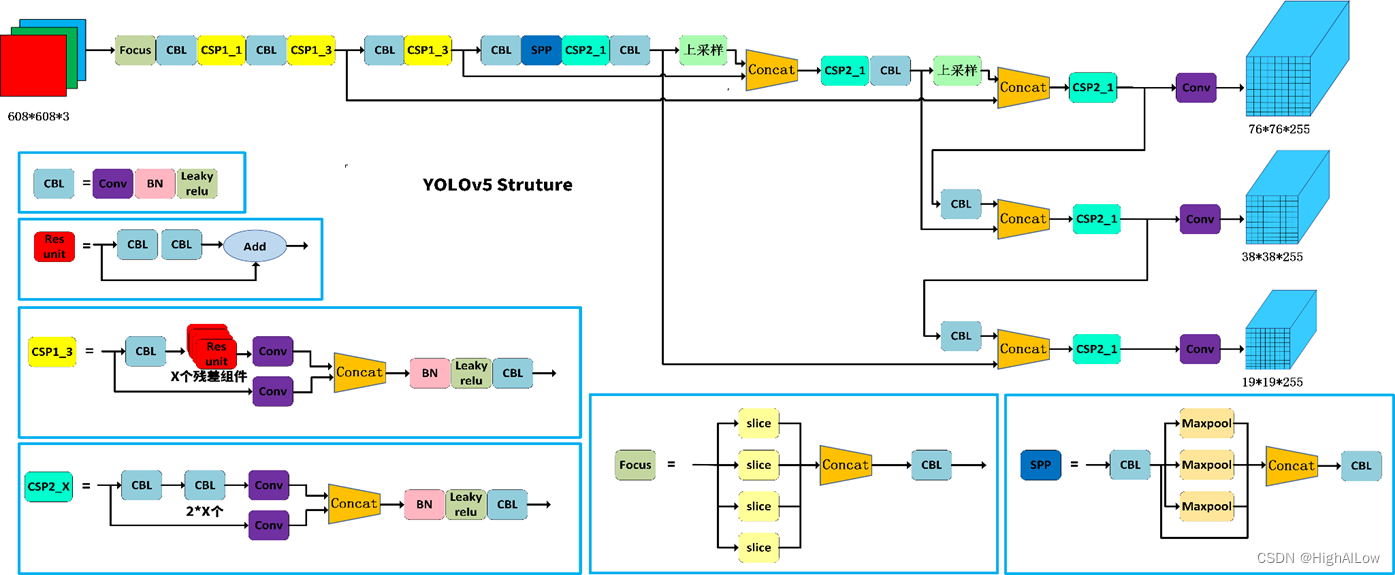
YOLOv5模型结构
from n params module arguments
0 -1 1 1760 models.common.Conv [3, 16, 6, 2, 2]
1 -1 1 4672 models.common.Conv [16, 32, 3, 2]
2 -1 1 4800 models.common.C3 [32, 32, 1]
3 -1 1 18560 models.common.Conv [32, 64, 3, 2]
4 -1 2 29184 models.common.C3 [64 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









