




 本文介绍了如何使用JDBC的FilteredRowSet接口来过滤数据库查询结果。FilteredRowSet允许在应用程序级别实现数据过滤,提高了性能,避免了多次数据库请求。通过创建自定义过滤器并应用到CachedRowSet上,可以实现对查询结果的定制化筛选。
本文介绍了如何使用JDBC的FilteredRowSet接口来过滤数据库查询结果。FilteredRowSet允许在应用程序级别实现数据过滤,提高了性能,避免了多次数据库请求。通过创建自定义过滤器并应用到CachedRowSet上,可以实现对查询结果的定制化筛选。
抽丝剥茧 细说架构那些事——【优锐课】
有时,对数据库的应用程序查询返回大量行。尽管获取的数据缓存在ResultSet对象中,但它通常太大而无法使用。结果,我们必须能够将它们筛选为不同的数据集以限制可见行。本文通过适当的示例深入介绍JDBC RowSet的筛选方面。
本文来自国内专业IT教育学院【优锐课】。Java学习资料交流qq群:907135806,在接下来的学习如果过程中有任何疑问,欢迎进群探讨。
RowSet概述
RowSet是对JDBC API for JavaBeans组件模型的补充。它提供了一组属性,允许将其实例配置为连接到JDBC数据源。RowSetinstance主要用于从数据源检索数据。此接口的setter方法用于填充SQL查询的command属性的参数,然后用于从关系数据库中获取记录。因为RowSet遵循JavaBean组件模型,所以它支持JavaBean事件。这些事件用于通知其他组件有关事件的信息,例如行集上值的更改。因为RowSet接口被设计为JDBC驱动程序之上的一层,所以它可以接受自定义实现。这种自由性使供应商能够构造自己的微调实现,并将其与JDBC产品一起交付。
FilteredRowSet
FilteredRowSet是RowSet系列的接口扩展。此接口有一个参考实现,称为FilteredRowSetImpl类。为了提供FilteredRowSet接口的自定义实现,可以根据需要扩展FilteredRowSetImpl类或使用FilteredRowSet接口。在某些情况下,我们需要对RowSet获取的内容进行某种形式的过滤。一个简单可行的解决方案是为所有RowSet实现提供查询语言。但是,这并不是可行的方法,因为RowSet是基于断开连接的轻量级组件的想法构建的。这将使物体沉重并违背其设计原理。我们需要一种方法来解决需求,但不将重量级查询语言与过滤的处理逻辑一起注入。JDBC FilteredRowSetstandard实现通过诸如CachedRowSet和WebRowSet之类的子接口分别扩展了RowSet。FilteredRowSet可以通过CachedRowSet接口提供的一组受保护的游标操作方法来操纵光标。可以根据要求覆盖这些方法,并在筛选RowSet内容时提供帮助。
一个简单的例子
这是一个示例,说明如何使用FilteredRowSet存储由激发到数据库的查询返回的内容。查询结果将根据应用于FilteredRowset实现的配置进行过滤。这定义了可见内容或我们对查询返回的结果感兴趣的行。在下面的示例中,我们创建了一个名为SimpleFilter的过滤器类。在我们的案例中,此类定义了FilteredRowSet的自定义实现。然后,我们将此过滤器应用于数据库查询返回的结果。过滤意味着限制可见的行数。因此,在此我们将根据提供的所选作者姓名来限制图书信息记录的数量。
为了进行动手操作,以下是即将在Java代码中使用的数据库表。
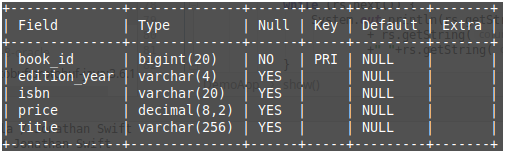
Figure 1: Database table, book
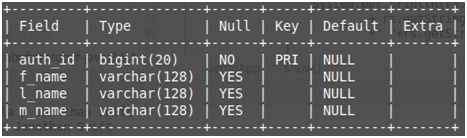
Figure 2: Database table, author
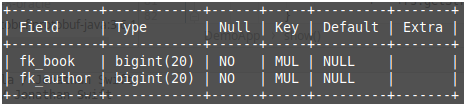
Figure 3: Database table, book_author
SimpleFilter类实现谓词的评估方法以实现我们的自定义过滤器。
package org.mano.example;
import javax.sql.RowSet;
import javax.sql.rowset.Predicate;
import java.sql.SQLException;
public class SimpleFilter implements Predicate {
private String[] authors;
private String colname = null;
private int colno = -1;
public SimpleFilter(String[] authors, String colname) {
this.authors = authors;
this.colno = -1;
this.colname = colname;
}
public SimpleFilter(String[] authors, int colno) {
this.authors = authors;
this.colno = colno;
this.colname = null;
}
@Override
public Boolean evaluate(Object value, String colName) {
if (colName.equalsIgnoreCase(this.colname)) {
for (String author : this.authors) {
if (author.equalsIgnoreCase((String)value)) {
return true;
}
}
}
return false;
}
@Override
public Boolean evaluate(Object value, int colNumber) {
if (colNumber == this.colno) {
for (String author : this.authors)
if (author.equalsIgnoreCase((String)value)) {
return true;
}
}
}
return false
}
@Override
public Boolean evaluate(RowSet rs) {
if (rs == null) return false;
try {
for (int i=0;i<authors.length;i++) {
String al = null;
if (this.colno> 0) {
al = (String)rs.getObject(this.colno);
} else if (this.colname != null) {
al = (String)rs.getObject(this.colname);
} else {
return false;
}
if (al.equalsIgnoreCase(authors[i])) {
return true;
}
}
} catch (SQLException e) {
return false;
}
return false;
}
}
此类用于执行SimpleRowSet过滤器类。注意我们如何利用FilteredRowSet来过滤应用程序中的数据。处理发生在应用程序级别而不是SQL数据库级别。结果,我们可以实现一系列过滤器,并将它们应用于相同的结果集以获得所需的结果。这可以提高性能,因为我们不必向数据库触发多个查询来获取修改后的结果。相反,我们可以对一次触发到数据库的查询结果应用多个过滤。该应用程序具有两个重要阶段:
• 我们创建一个过滤器,该过滤器列出了过滤数据的条件。这是通过实现Predicate接口来完成的。可以有多个构造函数接受不同的参数集。此外,过滤器可能包含一个数组evaluate()方法,它们也接受具有其自己独特的实现集的不同参数集。
• 必须实例化FilteredRowSet类以获得所需的效果,这是我们使用applyFilter()方法完成的。 FilteredRowSet使用我们提供的自定义过滤器类来确定要查看的记录。
package org.mano.example;
import com.sun.rowset.FilteredRowSetImpl;
import javax.sql.RowSet;
import javax.sql.rowset.FilteredRowSet;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DemoApp {
private static final String DB_URL =
"jdbc:mysql://localhost:3306/my_lib";
private static final String DB_DRIVER =
"com.mysql.cj.jdbc.Driver";
private static final String DB_USERNAME =
"root";
private static final String DB_PASSWORD =
"secret";
public static Connection conn = null;
public static FilteredRowSet filteredRowSet = null;
public static void main(String[] args) {
try {
Class.forName(DB_DRIVER);
conn = DriverManager.getConnection(DB_URL,
DB_USERNAME,DB_PASSWORD);
System.out.println("Database connection
successful.");
applyFilter();
} catch (SQLException | ClassNotFoundException ex) {
System.out.println(ex);
} finally {
if (conn != null) {
try {
conn.close();
catch (SQLException ex) {
ex.printStackTrace();
}
}
if (filteredRowSet != null) {
try {
filteredRowSet.close();
} catch (SQLException ex) {
ex.printStackTrace();
}
}
}
}
public static void applyFilter() {
String[] arr = {"Donne", "Milton"};
SimpleFilter aFilter = new SimpleFilter(arr, 3);
try {
filteredRowSet = new FilteredRowSetImpl();
filteredRowSet.setCommand("SELECT title, f_name, l_name "
+ "FROM book_author BA, "
+ "author A, "
+ "book B "
+ "WHERE A.auth_id = BA.fk_author "
+ "AND B.book_id = BA.fk_book");
filteredRowSet.execute(conn);
System.out.println
("--------------------------------------------");
System.out.println("Before applying any
filter:");
System.out.println
("--------------------------------------------");
show(filteredRowSet);
System.out.println
("--------------------------------------------");
System.out.println("After applying
filter :");
System.out.println
("--------------------------------------------");
filteredRowSet.beforeFirst();
filteredRowSet.setFilter(aFilter);
show(filteredRowSet);
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void show(RowSet rs) {
try {
while (rs.next()) {
System.out.println(rs.getString(1) + " / "
+ rs.getString(2)
+ " "+rs.getString(3));
}
} catch (SQLException ex) {
ex.printStackTrace();
}
}
}
Output
Database connection successful.
--------------------------------------------
Before applying any filter:
--------------------------------------------
Gulliver's Travels / Jonathan Swift
...
Ill Pensoroso / John Milton
Areopagitica / John Milton
--------------------------------------------
After applying filter:
--------------------------------------------
The Flea / John Donne
Holy Sonnet / John Donne
Paradise Lost / John Milton
Paradise Regained / John Milton
Ill Pensoroso / John Milton
Areopagitica / John Milton
结论
处理查询返回的大量行有很多问题。首先,检索到的数据会占用内存。
始终有助于根据需要和相关性限制它们。使用RowSet,我们可以根据条件过滤它们,而无需发出任何其他数据库请求。这样可以更轻松地处理数据库行,并充分利用代码的效率。


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









