




 本文介绍了DetNet,一种针对目标检测任务设计的骨干网络,旨在解决传统方法中因分辨率减小导致的大物体定位不准确问题。DetNet使用空洞卷积保持空间尺寸不变,增加像素感受野,从而提高检测准确性。与ResNet50-FPN相比,DetNet59在计算量更小的情况下,检测性能更优。尽管如此,文章仅对比了ResNet50,未能全面展示与更强大模型如ResNet101的差异。DetNet不仅适用于自身结构,还可以整合到MaskRCNN等框架中提升性能。文章指出,未来可能通过改变空洞卷积的rate分布来进一步优化网络。
本文介绍了DetNet,一种针对目标检测任务设计的骨干网络,旨在解决传统方法中因分辨率减小导致的大物体定位不准确问题。DetNet使用空洞卷积保持空间尺寸不变,增加像素感受野,从而提高检测准确性。与ResNet50-FPN相比,DetNet59在计算量更小的情况下,检测性能更优。尽管如此,文章仅对比了ResNet50,未能全面展示与更强大模型如ResNet101的差异。DetNet不仅适用于自身结构,还可以整合到MaskRCNN等框架中提升性能。文章指出,未来可能通过改变空洞卷积的rate分布来进一步优化网络。
极简笔记 DetNet: A Backbone network for Object Detection
文章的核心提出了一种专用于detection任务的backbone network:DetNet。目前检测网络的主流方法是基于classification网络加FPN和RPN结构进行定位。大部分分类网络通过减小深层的spatial size 来加大像素的感受野,较小的resolution一定程度影响了大物体定位的准确性。文章提出的DetNet在网络深层使用rate=2的空洞卷积替代原有bottleneck的3x3卷积,在不缩小spatial size,小幅增加计算量的同时增加像素感受野,以增加检测的准确性。为了减小计算量,深层部分的channel数停留在256没有增加。

文章的主要对比实验室ResNet50-FPN结构,因此构造了对应的DetNet59结构,大致结构对比如上图。DetNet是对骨架网络进行改造,因此可以同理加上FPN结构。因为DetNet59的计算量(FLOPs-4.8G)还是会比ResNet50的计算量(FLOPs-3.8G),有人可能会说提高的性能是由于更大的计算量带来的,于是文章又加了ResNet101(FLOPs-7.6G)的对比实验,显示在det任务上DetNet以更少的计算量取得了更高的检测结果。
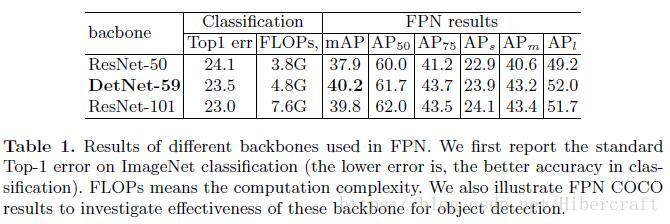
但是接下来文章就偷懒了,剩下的分析就只剩和ResNet50的对比了。在对比average precision(AP)和average recall(AR)时大中小三种尺度的物体DetNet59都超过了ResNet
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









