







-
现存问题
Both convolutional and recurrent operations are building blocks that process one local neighborhood at a time.(卷积操作只处理neighborhood一小块) -
如何捕获远距离的依赖/相关性?
- 对于序列化的数据,recurrent operations 是主流的解决方案
- 对于图像数据,使用大的感受野以及卷积操作的叠加
-
现存方法的不足
卷积和循环操作只能够处理局部数据,所以想获得远距离信息必须有大量的重复
(1) 计算耗时
(2) 优化问题?
(3) 信息难以远距离传递 -
non local 操作
a non-local operation computes the response at a position as a weighted sum of the features at all positions in the input feature maps(non local操作将一个位置处的响应计算为输入特征图中各个位置的特征的加权平均)
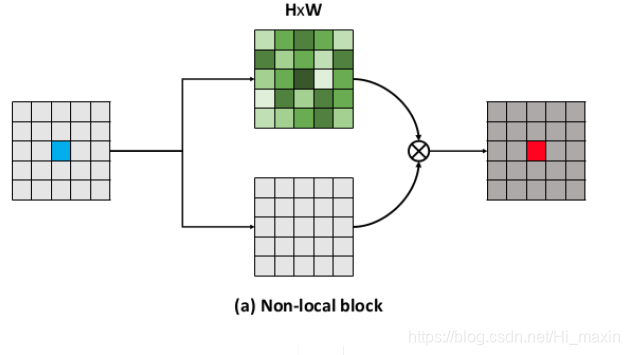
优点:
(1) non local操作直接计算两个位置之间的交互,不论这两个位置相隔多远
(2) 使用更少的层数
(3) 保留了输入的大小,使得嵌入变得更加容易 -
公式
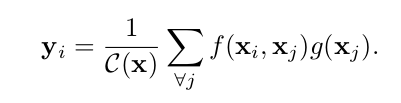
其中i是代表的输出位置的索引,x是输入,j是对所有位置的列举,f(xi,xj)表示输入的第xi和xj之间的相关性,g(xj)中,g用于计算输入数据中j这个位置的特征.- 与卷积之间的区别
对于一个卷积核大小为3卷积操作来说,i − 1 ≤ j ≤ i + 1 - 与全连接之间的区别
对于全连接层来说,xi和xj之间的相关性并不是关于输入数据的函数,而是通过学习得到的. 而且全连接层要求输入数据的大小是恒定的 - 相似度函数
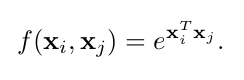
- non local 块
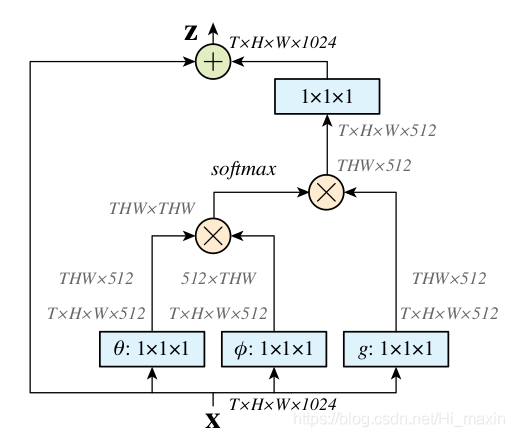
(1) 1*1卷积 bottleneck层降维
(2) 计算相似度矩阵
(3) 通过相似度矩阵,对每一个像素进行 non local操作
(4) 1*1 卷积升维
- 与卷积之间的区别
论文阅读- Non-local Neural Networks
最新推荐文章于 2023-03-20 17:22:51 发布
 本文探讨了卷积和循环操作在处理图像和序列数据时的局限性,即难以有效捕捉远距离依赖。Nonlocal操作作为一种创新方法,通过计算任意两点间的直接交互,解决了这一难题,其优势在于减少计算复杂度,优化信息传递,并保持输入尺寸不变,适用于深度学习的多种场景。
本文探讨了卷积和循环操作在处理图像和序列数据时的局限性,即难以有效捕捉远距离依赖。Nonlocal操作作为一种创新方法,通过计算任意两点间的直接交互,解决了这一难题,其优势在于减少计算复杂度,优化信息传递,并保持输入尺寸不变,适用于深度学习的多种场景。

















 4237
4237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









