







一:
1.requests库安装
r=requests.get("http://www.baidu.com")//构造一个向服务器请求资源的Request对象。
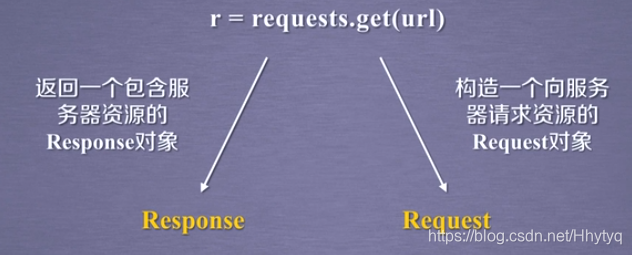




Requests库的异常:
r.raise_for_status()//如果不是200,产生异常requests.HTTPError
爬取网页的通用代码框架:
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果不是200,产生异常requests.HTTPError
r.encoding=r.apparent_encoding//解码方式
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
二:
HTTP协议及Requests库方法



1)Requests库的head()方法:

2)Requests库的post()方法
import requests
payload={'key1':'vaue1','key2':'vaue2'}
r=requests.post('http://httpbin.org/post',data=payload)
print(r.text)#向URL POST一个字典,自动编码为form(表单)

3)Requests库的put()方法,(能将原有数据覆盖掉)
4)


5)

例子:
import requests
kv={'key1':'valuel','key2':'value2'}
r=requests.request('GET','http://python123.io/ws',params=kv)
print(r.url)
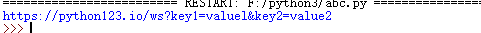
6)

import requests
kv={'key1':'valuel','key2':'value2'}
r=requests.request('POST','http://python123.io/ws',data=kv)
body="主体内容"
r=requests.request('POST','http://python123.io/ws',data=body)
7)

import requests
kv={'key1':'valuel','key2':'value2'}
r=requests.request('POST','http://python123.io/ws',json=kv)
8)

import requests
hd={'user-agent':'chrome/10'}
r=requests.request('POST','http://python123.io/ws',headers=hd)//可以用于模拟各种浏览器。


9)

import requests
r=requests.request('POST','http://python123.io/ws',timeout=10)
·10)

import requests
pxs={'http':'http://user:pass@10.10.10.1:1234','https':'https://10.10.10.1:4321' }
r=requests.request('POST','http://python123.io/ws',proxies=pxs)

三:


四:Robots协议

例子;百度的Robots协议
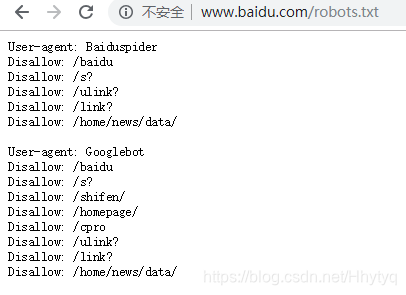
#注释: *代表所有 /代表根目录
User-agent:*
Disallow:/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









