




之前有朋友用CodeBlocks遇到过这个问题,然后我实在才疏学浅,无法帮助他解决这个问题。
很不幸,这个问题在前段时间来到了我的身边,而且久久未解决。(果然别人的问题也是问题,不然会变成自己的问题,令人悲伤)
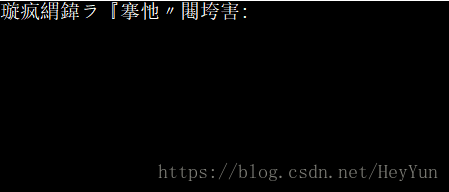
以下是一个令无数人糟心的截图
解决方法如下:
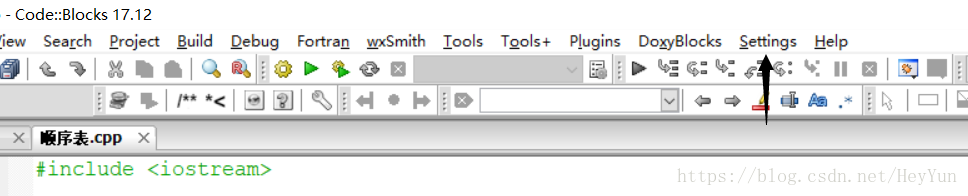
1.打开CodeBlocks–>settings–>compiler
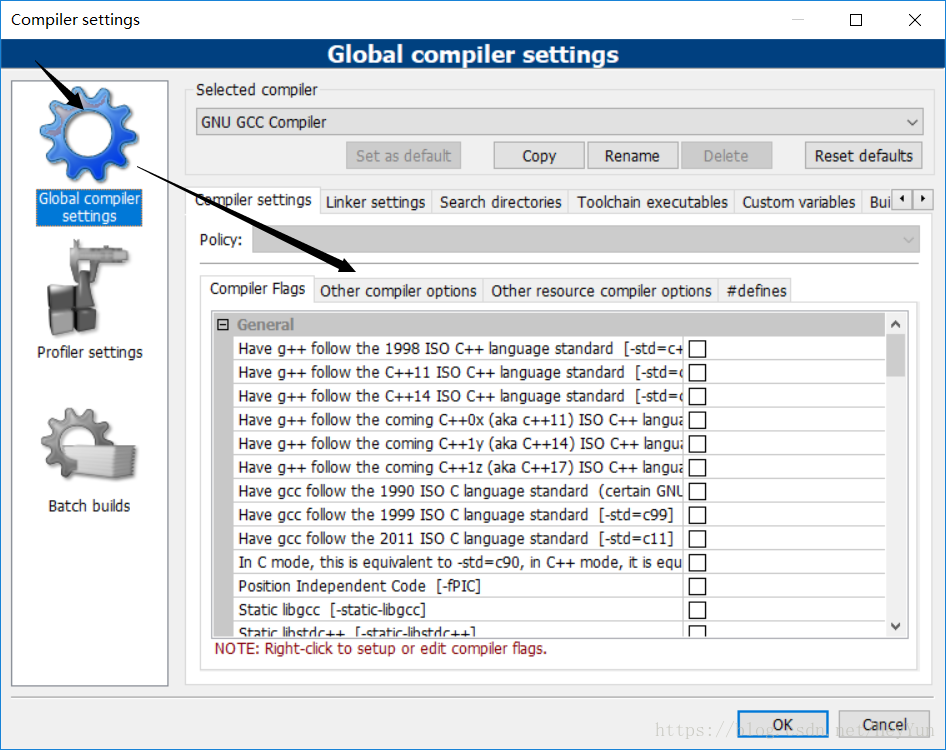
2.选择Other compiler options
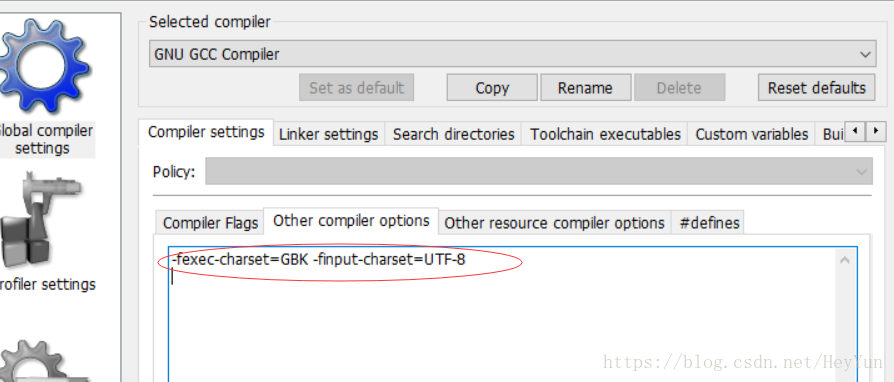
3.在输入框中添加一条语句
4.点击ok保存,再重新编译运行就能恢复正常了。
 解决CodeBlocks编译错误的方法
解决CodeBlocks编译错误的方法
 本文详细介绍了如何解决在使用CodeBlocks时遇到的编译错误问题。通过一系列步骤,包括打开设置、选择编译器选项、添加特定语句并保存,最终能够成功解决编译错误,恢复正常编译和运行。
本文详细介绍了如何解决在使用CodeBlocks时遇到的编译错误问题。通过一系列步骤,包括打开设置、选择编译器选项、添加特定语句并保存,最终能够成功解决编译错误,恢复正常编译和运行。
之前有朋友用CodeBlocks遇到过这个问题,然后我实在才疏学浅,无法帮助他解决这个问题。
很不幸,这个问题在前段时间来到了我的身边,而且久久未解决。(果然别人的问题也是问题,不然会变成自己的问题,令人悲伤)
以下是一个令无数人糟心的截图
解决方法如下:
1.打开CodeBlocks–>settings–>compiler
2.选择Other compiler options
3.在输入框中添加一条语句
4.点击ok保存,再重新编译运行就能恢复正常了。
 5290
5290
























 到【灌水乐园】发言
到【灌水乐园】发言






