







 本文详细介绍了如何使用Hive SQL删除数据分区,包括单个分区字段和多个分区字段表的删除方法,以及元数据和数据存储的变化。内容涵盖删除语法、不同场景的示例,如单个和多个分区数据的删除,以及分区范围数据的处理。
本文详细介绍了如何使用Hive SQL删除数据分区,包括单个分区字段和多个分区字段表的删除方法,以及元数据和数据存储的变化。内容涵盖删除语法、不同场景的示例,如单个和多个分区数据的删除,以及分区范围数据的处理。
目录
1.删除语法
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec[, PARTITION partition_spec, ...]
2.元数据及数据存储变化
可以使用ALTER TABLE DROP PARTITION删除表的分区。将会删除该分区的数据和元数据。如果配置了Trash,数据实际上会被移动到.Trash/Current目录,除非指定了PURGE,但是元数据会完全丢失。
3.示例
测试数据以日期为测试分区字段
3.1 单个分区字段表
测试数据准备
-- 建表语句
create table if not exists test_dt (
col string
)
partitioned by (dt string)
;
-- 测试数据
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table test_dt partition (dt)
select 'a' as col,'2021-10-01' as dt
union all
select 'a' as col,'2021-10-02' as dt
union all
select 'a' as col,'2021-10-03' as dt
union all
select 'a' as col,'2021-10-04' as dt
union all
select 'a' as col,'2021-10-05' as dt
union all
select 'a' as col,'2021-10-06' as dt
;3.1.1 删除单个分区单个分区数据
alter table test_dt drop partition (dt = '2021-10-01');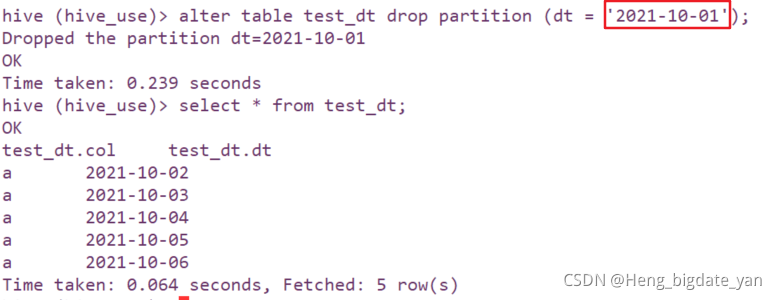
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









