




 本文介绍了使用sklearn构建决策树的建模流程,强调了fit、score、get_params和predict等关键接口。文章探讨了决策树的不纯度概念,指出随机性在防止过拟合中的作用,如random_state和splitter参数。还详述了8个重要参数,包括criterion、max_depth、min_samples_leaf等,以控制模型复杂度和防止过拟合。最后预告将使用回归树解决泰坦尼克号案例。
本文介绍了使用sklearn构建决策树的建模流程,强调了fit、score、get_params和predict等关键接口。文章探讨了决策树的不纯度概念,指出随机性在防止过拟合中的作用,如random_state和splitter参数。还详述了8个重要参数,包括criterion、max_depth、min_samples_leaf等,以控制模型复杂度和防止过拟合。最后预告将使用回归树解决泰坦尼克号案例。
上回书说到,决策树是一种非参数的有监督学习方法,它的作用是将表中数据所隐含的规律总结出来,并对新的输入数据进行基于已有规则的判断。决策树的两个核心问题是如何选择最佳的分枝特征以及如何防止过拟合。今天,我们将从应用sklearn来创建决策树这一视角出发,来简述一下回归树的建模流程以及重要参数。同样地,这次分享不涉及有关参数的数学原理,想看原理的朋友们可以有个心理预期啦。
---------------------------------------------------------------------------------------------------------------------------------
1.sklearn的建模流程
几乎所有的sklearn上的模型都可以用下面的三步来建模;
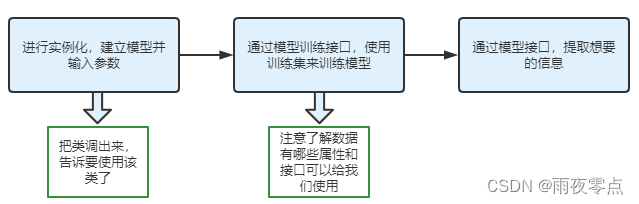
其中比较重要的接口是:
fit —训练模型的接口,输入xtrain ytrain
score — 用与评测给定的测试数据与标签间的准确度,分数越高模型越好,输入xtest ytest
get_params — 获取这个模型评估对象的参数
pedict — 预测测试集中样本点的标签
2.理论上决策树的建树基本流程
不纯度:可以粗略的理解为样本属于同一类别的程度。

如果按照上述流程建树,就会遇到一个问题,一棵每一步都是不纯度相关指标最优化的树,真的是效果最好的树吗?很显然答案是不一定的,当然原因是什么我不知道。为了解决这个问题,sklearn引入了一定程度的随机性,它随机建很多课树,我们可以从中挑出效果最好的那一棵来使用。具体的随机性的控制参数random_state以及splitter我们在回顾参数的时候详细的说一说。
3.决策树的重要参数
关于决策树的重要参数,菜菜老师已经总结了8个最重要的参数,分别为criterion、random_state、splitter、max_depth、min_samples_leaf、min_samples_split、max_features、min_impurity_decrease。
(1)criterion
可以选择gini 与 entropy作为度量信息不纯度的方法,其中参数值默认为gini。进一步深化一下,决策树算法主要分为ID3,C4.5,CART三种,其中:
ID3采用熵来衡量信息的不确定度,选择信息增益最大的特征作为分枝的节点
C4.5同样采用熵来衡量信息的不确定度,选择信息增益比最大的特征作为分枝的节点
CART采用基尼系数作为衡量信息不确定度的指标,选择最小的特征作为分枝的节点。
通过sklearn各种参数的配合,可以得到与上述算法相似的效果。
(2)random_state
我们之前已经讨论过了,最优的各个节点的集合,长出的不一定是效果最优的树;sklearn为了解决这个问题,便通过random_state随机选择一部分特征,从中选取相关指标最好的作为节点,而不是用全部的特征来进行建树;通过设置相同的random_state,便可以使sklearn选择特征的模式固定下来,方便复现实验结果。(PS:在网上看到一个说法,当很多特征的信息增益等度量不纯度指标的大小一致时,也是通过random_state来随机选择特征作为分枝节点的。)
它的效果和随机数种子类似,会产生一堆伪随机数,从而使随机性变得“既随机又可控”,通过对random的设置,可以使你的实验结果复现出来。
同时,在测试集与训练集的划分方面,random_state在train_test_split类中也有同样的运用,通过设置它,来使训练集与测试集的划分具有可复现性。
(3)splitter
splitter也是一个带随机性的参数,它有两个选项,‘best'与'random’,选择best代表分枝时虽然随机,但是会优先选择有更好结果的值来进行分枝,选择random,决策树分枝时随机性就更高了,这样树会含有更多噪声信息从而变得更深更大,来减少过拟合。
训练模型时,有可能会出现这样一种情况,训练集上得分很高,测试集上得分却不高,这便是过拟合,模型拟合了太多属于训练集的无关噪声,从而减少了它的泛化性;从另一个角度看,便是这棵树长的太深太精细了,因此需要对它进行剪枝,将那些精细的树枝剪掉,减少过拟合的发生。因此接下来我会介绍5个剪枝参数。
(4)max_depth
它用来限制树的最大深度,深度超过阈值的部分全部剪掉。它是剪枝参数中最重要的一个参数,通常调参先调它。它在高纬度低样本量时效果非常好,因为决策树每多分一层,它对样本的需求量就会上升一倍。
(5)min_samples_leaf
一个节点在分枝后,每个子节点都必须包含至少min_samples_leaf个样本,否则:
1)子节点样本数量不够,父节点就直接不分枝了
2) 也可能向数量不够的那一个子节点多分一些样本过去,使其至少要超过最低阈值(也可以超过很多,看实际情况)
(6)min_samples_split
该参数限定,一个节点必须至少包含min_samples_split个样本,它才允许分枝,否则就不能产生子节点。
(7)max_features
该参数粗暴的限制分枝时参与筛选的特征数,这样可能会舍弃重要的特征,因此若遇到高维数据,可以用降维算法先降维。
(8)min_impurity_decrease
该参数用来限制信息增益或基尼的大小,小于该数值就不会发生分枝。通常在网格搜索中配置该参数。
---------------------------------------------------------------------------------------------------------------------------------预告:下一期会用回归树来做泰坦尼克号案例
---------------------------------------------------------------------------------------------------------------------------------

















 1767
1767




 到【灌水乐园】发言
到【灌水乐园】发言







