



 本文讲述了如何从B站爬取动漫数据,并进行数据存储、分析和可视化。通过对评分、追番人数和播放数量的分析,揭示了动漫作品的受欢迎程度。
本文讲述了如何从B站爬取动漫数据,并进行数据存储、分析和可视化。通过对评分、追番人数和播放数量的分析,揭示了动漫作品的受欢迎程度。
哔哩哔哩(英文名称:bilibili,简称B站)现为国内领先的年轻人文化社区,该网站于2009年6月26日创建,被粉丝们亲切的称为“B站”。
B站的特色是悬浮于视频上方的实时评论功能,爱好者称其为“弹幕”,这种独特的视频体验让基于互联网的弹幕能够超越时空限制,构建出一种奇妙的共时性的关系,形成一种虚拟的部落式观影氛围,让B站成为极具互动分享和二次创造的文化社区。B站目前也是众多网络热门词汇的发源地之一。
大家都知道B站的动漫资源可是十分丰富的,而且大多年轻人都喜欢看动漫,所以这次就从B站爬取了20部比较热门的动漫作品并做一个简单的数据分析。
1.数据爬取
1.1获取API接口
需要爬取bilibili动漫需要先找到bilibili的api接口,通过浏览器f12分析后,可以查询到api接口。
https://api.bilibili.com/pgc/season/index/result?season_version=-1&spoken_language_type=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=%5B2021%2C2022)&style_id=-1&order=3&st=1&sort=0&page=1
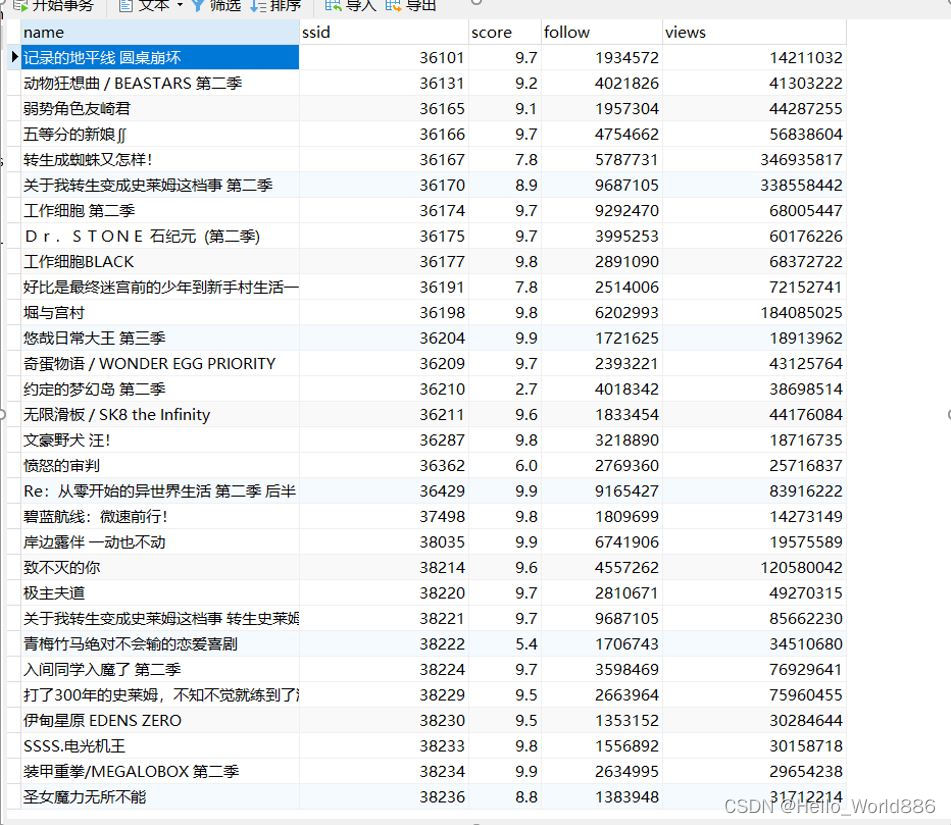
其中page参数是页面数,所以我们只需要修改page参数,就可以获取不同的动漫基本信息(动漫名称和SSID)获取到SSID后,再通过SSID来查找对应动漫的点赞数,追番数等信息。
https://api.bilibili.com/pgc/web/season/stat?season_id=
https://www.bilibili.com/bangumi/play/ss
https://api.bilibili.com/pgc/view/web/season?ep_id=
通过这三个api接口获取番剧信息。
1.2得到基本数据
通过此函数得到数据信息。
# 得到一个指定URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息,向服务器发送消息
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
} # 用户代理,告诉服务器我是浏览器
req = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(req) # 向网页发起请求,爬取数据
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
1.3数据匹配
在之前得到数据之后,再在数据里面匹配自己想要的数据,使用正则或者BeautifulSoup实现
这个是获取评分的正则表达式
s_epid = r"(?<=Fep).*?(?=\",)" # 获取 Epid 的正则表达式
s_score = r"\"score\":(.*?)}" # 获取评分的正则表达式
这是获取SSID号
s_id = r"\"season_id\":(.*?)," # 获取所有番剧的 SSID 号的正则表达式
s_title = r"\"title\":\"(.*?)\"," # 获取所有番剧的名称的正则表达式
这是追番人数
s_sfoll = r"\"series_follow\":(.*?)," # 获取每个番剧追番人数的正则表达式
这是播放数
s_views = r"\"views\":(.*?)}" # 获取番剧播放数的正则表达式
2.数据存储
2.1连接MySQL数据库
import pymysql
class PyMysql:
# 获取Mysql Server连接
def __init__(self):
# 连接数据库服务器,创建一个数据库对象,操作student_management_system数据库
self.db = pymysql.connect(
host='localhost',
user='root',
password='',
port=3306,
db='bilibili_fanjuin_formation',
charset='utf8',
)
# 开启mysql的游标功能,创建一个游标对象
self.cursor = self.db.cursor()
# 获取多条数据
def fetch_all(self,sql):
# 使用execute()方法执行SQL语句
self.cursor.execute(sql)
# 使用fetchall()方法获取多条数据
results = self.cursor.fetchall()
# print("查询成功")
# print(results)
return results
# 获取单条数据
def fetch_one(self,sql):
# 使用execute()方法执行SQL语句
self.cursor.execute(sql)
# 使用fetchone()方法获取多条数据
results = self.cursor.fetchone()
# print("查询成功")
# print(results)
return results
# 添加、删除、更新数据
def Insert(self,sql,datas):
# 使用execute()方法执行SQL语句
self.cursor.execute(sql,datas)
# 提交数据库执行SQL语句
self.db.commit()
# print("插入成功")
return 1
# 关闭连接
def close(self):
self.db.close()
2.2将数据放入MySQL数据库
def saveData(datadict, viewinfos, followinfo, scoreurlinfo):
name = getDataName(datadict) # 获取番剧名称
ssid = getDataSSID(datadict) # 获取番剧 ssid
mysql = Rdb.PyMysql()
for i in range(len(name)):
sql = "insert into info values(%s,%s,%s,%s,%s)" # 将数据插入数据库的 SQL 语句
data = [name[i], int(ssid[i]), scoreurlinfo[i], int(followinfo[i]), int(viewinfos[i])]
# print(str(data))
i = mysql.Insert(sql,data) # 将数据插入数据库
if i==0:
mysql.close()
return 0
mysql.close() # 关闭数据库
return 1
3.数据分析及可视化
3.1 关于每部动漫评分分析
选取数据,获取动漫评分数据
# 获取番剧评分
def getDataScore(datadict, ssurl, epidurl):
scorelist = [] # 用于存放番剧评分信息的列表,并返回
EpidList = [] # 用于存放番剧 Epid 号
ssid = getDataSSID(datadict)
for i in range(len(ssid)):
url =ssurl + str(ssid[i]) # 计算需要爬取的 url
html = askURL(url) # 爬取数据
# print(html)
# 逐一解析数据
s_epid = r"(?<=Fep).*?(?=\",)" # 获取 Epid 的正则表达式
List = re.findall(s_epid, html)
print(List[1])
EpidList.append(List[1])
for i in range(len(EpidList)):
# print("-"*50)
url = epidurl + str(EpidList[i]) # 计算需要爬取的 url
# print(EpidList[i])
html = askURL(url) # 爬取数据
# 逐一解析数据
s_score = r"\"score\":(.*?)}" # 获取评分的正则表达式
ScoreList = re.findall(s_score, html)
if ScoreList: # 如果番剧评分为 0 ,表示该番剧未上映,只是预告片
scorelist.append(ScoreList[0])
else:
scorelist.append('0')
# print(ScoreList)
# print("-" * 50)
# print(scorelist)
return scorelist
绘制树状图
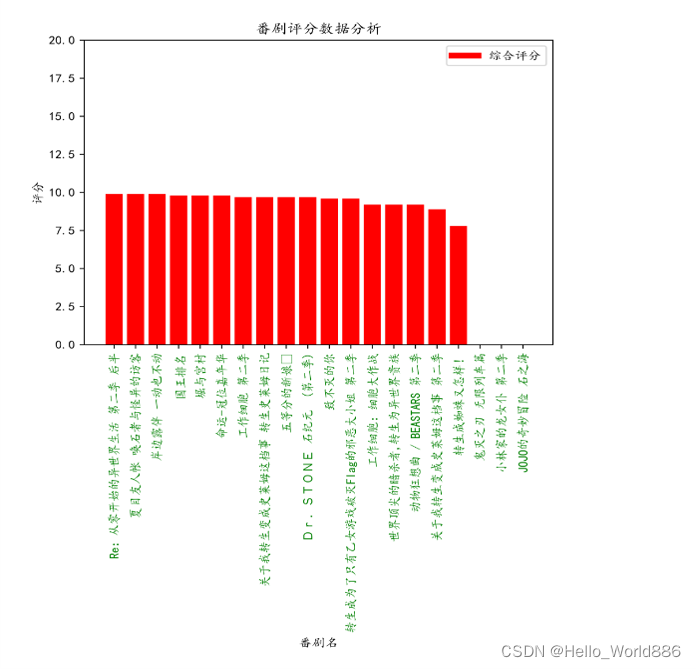
从图中可以发现一半多的动漫评分都接近10分,让我惊讶有这么多评分如此高的动漫,说明受还是很受中国观众的喜爱,大家给的评分都还挺高的。
3.2 关于每部动漫追番人数分析
选取数据
# 获取每个番剧的追番人数
def getDataFollowInfo(datadict, infourl):
info = [] # 用于存放番剧追番人数的列表
ssid = getDataSSID(datadict)
for i in range(len(ssid)):
url = infourl + str(ssid[i]) # 计算需要爬取的 url
html = askURL(url) # 爬取数据
# 解析数据
s_sfoll = r"\"series_follow\":(.*?)," # 获取每个番剧追番人数的正则表达式
SFollList = re.findall(s_sfoll, html)
# print(SFollList, end="\t")
info.append(SFollList[0]) # 每一次获取番剧追番数后将数据放入 indo 列表
return info
绘制成树状图
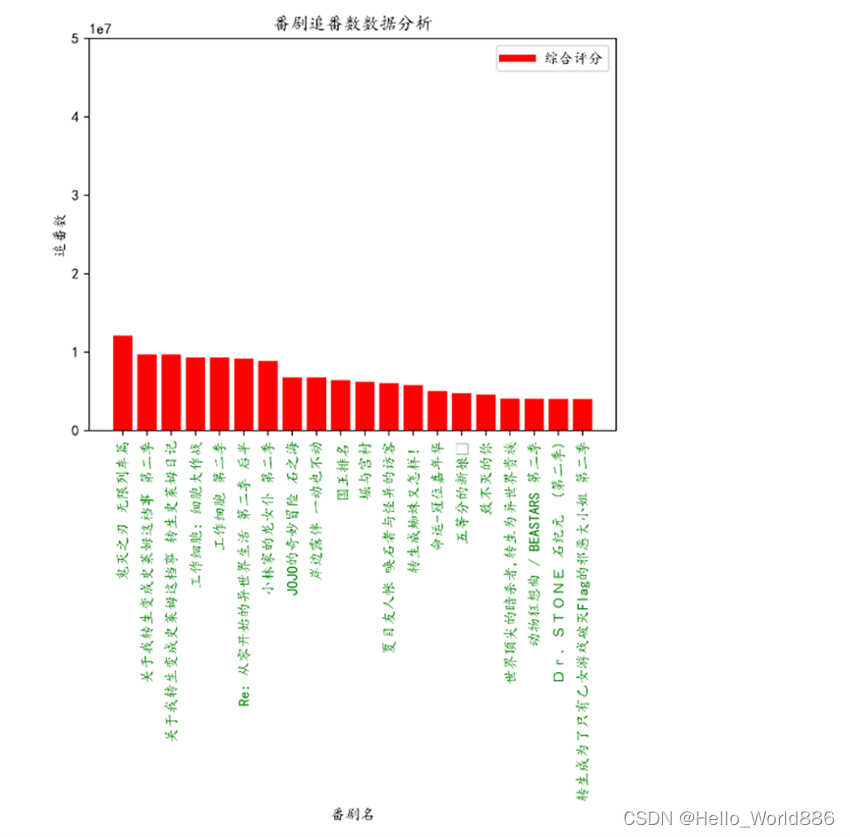
通过此树状图可以发现大多数观众对《鬼灭之刃 无限列车篇》这部动漫的剧场版期待很高。
3.3 关于每部动漫受欢迎程度分析(播放数量)
选取数据
# 获取每个番剧的播放数
def getDataViewInfo(datadict,infourl):
info = [] # 用于存放番剧播放数信息的列表
ssid = getDataSSID(datadict)
for i in range(len(ssid)):
url = infourl + str(ssid[i]) # 计算需要爬取的 url
html = askURL(url) # 爬取数据
# 解析数据
# print(html)
s_views = r"\"views\":(.*?)}" # 获取番剧播放数的正则表达式
ViewsList = re.findall(s_views, html)
# print(ViewsList)
info.append(ViewsList[0]) # 每一次获取番剧播放数后将数据放入 info 列表
return info
绘制树状图
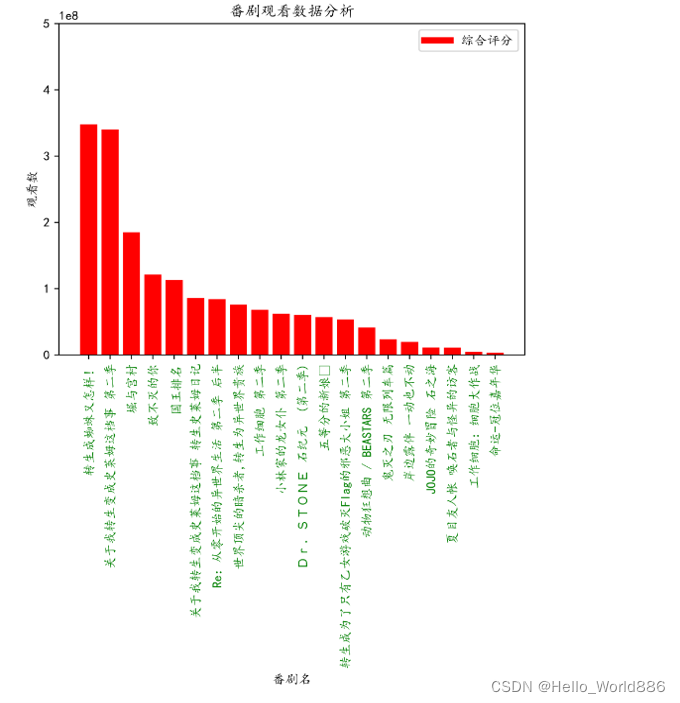
从图中可以清晰看出这些动漫最近的播放量,差距还是很明显的,高低层次一目了然。
4.结尾
本次爬取运用的部分相关函数:
# 根据给定的位置,为数据排序(降序),返回元组类型
def getsort(infos,n)
# 将数据转换为元组
def getDatainfos(datadict, viewinfos, followinfo, scoreurlinfo)
# 数据转换
def getDatadict(datalist)
# 获取字典中的 SSID
def getDataSSID(datadict)
# 获取字典中的名字
def getDataName(datadict)
# 获取番剧评分
def getDataScore(datadict, ssurl, epidurl)
# 爬取前100个番剧的名称和 SSID 号
def getDataF(baseurl)
# 获取每个番剧的追番人数
def getDataFollowInfo(datadict, infourl)
# 获取每个番剧的播放数
def getDataViewInfo(datadict,infourl)
# 保存数据
def saveData(datadict, viewinfos, followinfo, scoreurlinfo)
# 获取番剧元组信息中的各项值
def getTupleValues(tup,n)
# 将字符串列表转换为浮点型列表
def getFloatList(l)
# 将字符串列表转换为整型列表
def getIntList(l)
# 获取番剧评分的统计图并保存
# img_name:保存图片名称,title:统计图标题,xlabel:统计图横坐标标题,ylabel:统计图纵坐标标题
# min_ylim:纵坐标范围最小值,max_ylim:纵坐标范围最大值,n:需要统计信息在列表中的位置
def Viewabledata(infos,img_name,title,xlabel,ylabel,min_ylim,max_ylim,n)
# 得到一个指定URL的网页内容
def askURL(url)

















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









