



JAVA通过ChromeDriver爬取数据 Jsoup解析爬取到的HTML数据
前言:最近项目有涉及到爬取生物数据的内容,于是总结一篇基础的爬取数据并解析的文章
依赖
<!-- hutool工具 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.5.7</version>
</dependency>
<!-- Jsoup用于解析HTML -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
<!-- selenium用于ChromeDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
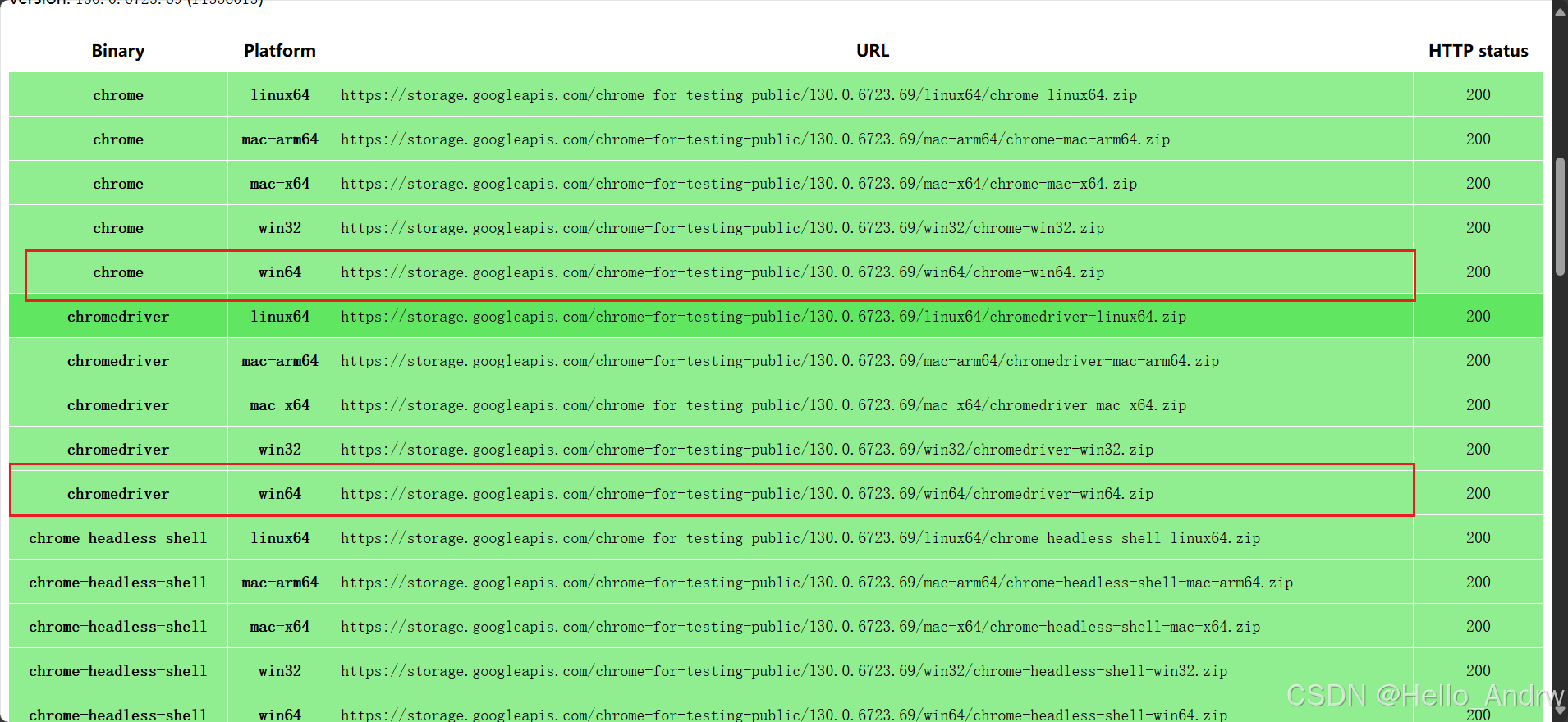
ChromeDriver及Chrome下载
根据自己的需求下载,ChromeDriver和Chrome的版本必须一致
下载地址:https://googlechromelabs.github.io/chrome-for-testing/
代码实现
/**
* 这是一个简单的html,方便我们理解使用Jsoup
* <!DOCTYPE html>
* <html>
* <head>
* <title>Sample HTML with Attributes</title>
* </head>
* <body>
* <h1>你好,世界</h1>
* <p class="sample-paragraph">人生不是轨道/p>
* <a href="https://www.example.com" id="myLink">是旷野<</a>
* <div id="myDiv">
* <p>生活不止眼前的苟且</p>
* </div>
* <div class="special-div">
* <p>还有诗和远方的田野</p>
* </div>
* </body>
* </html>
*/
public static void main(String[] args) {
//我们将上面的简单html作为字符串传入Jsoup
String html = "<!DOCTYPE html><html><head><title>Sample HTML with Attributes</title></head><body><h1>你好,世界</h1><p class=\"sample-paragraph\">人生不是轨道</p><a href=\"https://www.example.com\" id=\"myLink\">是旷野</a><div id=\"myDiv\"><p>生活不止眼前的苟且</p></div><div class=\"special-div\"><p>还有诗和远方的田野</p></div></body></html>";
Document doc = Jsoup.parse(html);
//当我们只想拿到 你好,世界 我们就需要找到h1的标签在使用text
String h1 = doc.select("h1").text();
/**
* 当一个标签有跳转链接的时候 我们想要拿到这个链接
* 就需要先找到a标签 在使用attr找到href字段
* 这样就能拿到链接啦
*/
String url = doc.select("a").attr("href");
// 当有多个标签的时候 如div 我们就需要找到他的id来缩小检索的范围
String myDiv = doc.select("div#myDiv").text();
// 当有多个标签的时候 如div 我们就需要找到他的class来缩小检索的范围
String divParagraphText = doc.select("div.special-div").text();
//那当我只想拿到div#myDiv下面的p标签的时候就需要使用 > 就是表示是div下面的p标签
String p1 = doc.select("p").text();
String p2 = doc.select("div > p").text();
String p3 = doc.select("div#myDiv > p").text();
/**
* 上面是一些基础的Document如何使用
* 下面我们来试一下使用chromedrive或者直接请求网站
*/
/**
* 1.用hutool的请求工具直接请求网站
*/
String bkmsUrl = "https://bkms.brenda-enzymes.org/index.php?booleans%5B%5D=1&categories%5B%5D=1&variants%5B%5D=1&searchterms%5B%5D=a&ssq=true&SYN=1&l=10&Search=Search#results";
HttpResponse response = HttpUtil.createGet(bkmsUrl).execute();
if (response.getStatus() != 200){
System.out.println("------------------------------------------------------------获取数据失败");
return;
}
// 将响应的结果使用Jsoup解析HTML
Document doc1 = Jsoup.parse(response.body());
//todo 进行解析并保存到数据库
/**
* 2.使用chromedrive来请求网站
*/
// 设置ChromeDriver的路径
System.setProperty("webdriver.chrome.driver", "D:\\chromedriver\\chromedriver-win64\\chromedriver.exe");
// 初始化ChromeOptions
ChromeOptions options = new ChromeOptions();
// 设置Chrome浏览器的路径
options.setBinary("D:\\chromedriver\\chrome-win64\\chrome.exe");
// 设置无头模式(不设置无头模式的话 任务栏会弹出chrome浏览器然后根据你的网址自动访问)
options.addArguments("--headless");
// 初始化ChromeDriver并应用配置
WebDriver driver = new ChromeDriver(options);
// 访问目标网址
driver.get(bkmsUrl);
String responseBody = driver.getPageSource();
// 使用Jsoup解析HTML
Document doc2 = Jsoup.parse(responseBody);
//todo 进行解析并保存到数据库
}

















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









