




 本文介绍了大数据领域多个框架和技术。涵盖HDFS、MapReduce、YARN等Hadoop生态组件,以及Hive、Presto、Spark等计算平台,还提及Zookeeper、HBase等工具。此外,讲解了堡垒机、跳板机等企业开发机制,布隆过滤器原理,阿里云大数据服务,以及数据湖、数据仓库等概念。
本文介绍了大数据领域多个框架和技术。涵盖HDFS、MapReduce、YARN等Hadoop生态组件,以及Hive、Presto、Spark等计算平台,还提及Zookeeper、HBase等工具。此外,讲解了堡垒机、跳板机等企业开发机制,布隆过滤器原理,阿里云大数据服务,以及数据湖、数据仓库等概念。
# 框架-定位
## HDFS
定位:分布式的`文件`存储系统
HDFS:Hadoop Distributed File System
### 文件系统
存储以文件作为基本的逻辑单元,也就是存储的逻辑上是:文件夹、文件
### 特性
只是单纯的记录文件,没有任何的`检索`能力
也就是,完全没法做:
- 找到ID为xxx的数据
- 过滤xxx列
- 找出xxx>yyy的
==所以,HDFS是,高吞吐能力,无随机查询能力==
#### 吞吐
高吞吐: 进来的(吞)和出去的(吐)可以是海量的。
也就是HDFS也可以:
- 存入海量的数据,性能不低(高吞吐的吞),比如可以达到每秒上GB的存入能力
- 随着集群数量的增加,吞吐能力会动态增加
- 比如10台机器能够一秒接收1GB数据存入,那么如果100台服务器,就能有10GB每秒的接收能力,只要提供数据端有这个能力一秒发出去10个G
- 取出海量的数据,性能不低(高吞吐的吐),比如可以达到每秒GB以上的数据输出能力
- 从HDFS`取`数据,只要取数据端能够扛得住,HDFS可以很快。
#### 无随机查询能力
和上述特性一样,只能以文件为单位,存或取而已。没办法检索数据。
也就是,单纯的文件存进来,和文件取出去,性能超高,无法检索,这就是HDFS
## MapReduce
定位:分布式的数据计算
数据计算:有明确的结果要求,围绕着结果的要求,通过数据的计算得到结果。
### 特性
语言上:支持`Java`、Python等编程语言
计算方式上:必须写MapReduce代码,才可以运行MR程序。
MapReduce本体:MapReduce本体就是一堆代码而已,也就是SDK。
SDK:Software Development Kit,软件开发工具包。就是Python 的第三方库的感觉。
比如:
- PyMySQL 库
- Json 库
- OS 库
- 等,都可以认为是SDK,也就是别人写好的代码你可以调用它提供的API功能。
### 计算方式
只能手写代码,提交运行起来MapReduce
也就是,弊端在于,单纯的MapReduce本身是无法支持SQL
### 吞吐 性能
MapReduce也是一个高吞吐的计算框架,主要体现在`吞`上
可以拿到海量的数据做计算,`高效(绝对的,不和Spark等比较,只和单机比较)`的给出结果
### 弊端
编程模型上,只支持2个算子:map和reduce
由于只有这2个算子,复杂的任务,`很难以1个MapReduce程序得到结果`,一般都是些多个MR,第一个MR走Map->Reduce后,产出结果,第二个MR接着读取上一个的结果继续走M->R
按照这个流程, 可能要走很多次MR才能最终计算完成。
> 这个弊端就可以理解为:Spark只有map和reduce2个算子,干起活来太难受。
> 多次MR计算涉及到结果要写入磁盘,然后下一个MR再读取,销量在频繁的磁盘IO中消耗了。
>
> 同时单个MR的M和R之间的Shuffle也是磁盘交互
>
> 所以整体上性能对比Spark等差
## YARN
定位:分布式资源管理
YARN的出现,极大的改善了大数据任务的资源难以协调的模式
### YARN对大数据资源协调的贡献
假设公司要使用的计算框架有:
- MapReduce
- Spark
- Presto
如果没有YARN的出现,那么需要有3个独立的集群。
比如有30台服务器, 10台给MR集群,10台给Spark集群,10台给Flink集群。
没有YARN,大家都要启动:`StandAlone`,也就是各个框架自己:管理资源,提供Master-Worker在自己的Master Worker内运行自己的任务。
这三个框架各玩各的。
问题就是:Spark集群忙成狗,MR和Flink集群没事干。 过一段时间,Flink忙成狗,Spark和MR闲得很。
也就是,我运行Spark任务的时候,只能在10台Spark中运行,MR和Flink的集群就是摆设。
如果有YARN,30台服务器,都不允许框架的StandAlone,而是`都将资源提供给YRAN`
在公司内,`只有YARN集群`,而没有Spark、MR、Flink的StandAlone集群。
这样,如果只跑Spark,也能用上30台的资源。
如果大家混着跑,也可以基于YARN来做资源协调。
> YARN让很多小老板省了大钱(服务器资源高度利用)
## Hadoop
定位:
- 分布式文件系统存储能力
- 分布式计算能力
- 分布式资源管理能力
## Hive
定位:分布式`SQL`数据计算
主要是为了解决:MapReduce不支持SQL的场景。
### 数仓
为什么数仓都用Hive多呢? 因为Hive支持SQL
数仓是基于数据库理论发展而来,从最初到现在,都是基于SQL作为主力计算工具。
所以发展到现在,大数据数仓也主要以SQL进行。
Hive支持SQL,又能跑分布式计算,可以让SQL去计算上TB、PB的数据集,受到企业的选择。
> 扩展:基于Spark、Flink这些新技术以及对编程模型的优化,现在有不少新型数仓是SQL和代码的混合模式。
>
> 甚至都有基于实时技术构建的实时数仓了。
### 为什么SQL对大数据重要
1. 参见上面所说。
2. 人是懒的,能写SQL就不想写代码。
1. 同样的一个数据计算,写SQL SELECT要1分钟, 写同样功能的MR代码,要15分钟。
## Presto
定位:分布式的内存SQL计算平台
单纯从性能上看:Presto是高于Hive很多倍的,和Spark持平。
### 为什么架构中还有Hive而非直接Presto
为什么有Hive
1. Hive太成熟了,稳定、BUG少,用户多,出现问题百度好搜,出现的时间长很知名。
2. Hive是单机工具,对集群侵占性很小,主要运行在YARN上
为什么有Presto
1. Hive太慢(相对于Presto、Spark等)
在项目中,我们的SQL计算有2大类:
1. 指标计算(固定模式),要从ODS->APP走固定分层迭代计算,每天有固定调度做增量的任务,做计算的任务在跑。
1. 一个指标就是一个计算程序,是一套数据流程的过程,是一套固定的任务调度安排。
2. 也就是计算一个指标,不是说写一个SQL,run一下就OK的。
2. 即席查询(自助式查询),临时性的想要分析某些东西(当前指标不包含的)(非固定模式)
Presto主要提供项目的即系查询:
1. Presto快,即席都是临时需求,都是很想很快看到结果的。
既然Presto快,为何不替代Hive呢?
1. Presto是要有独立集群的。和企业的YARN集群冲突。要省钱。
也就是:
1. 固定指标计算,Hive好用
1. `不在于性能,在于成熟好用,资料多,稳定,问题好解决。这些比单纯跑得快重要。`
2. 即席查询,Presto好用
1. 临时性SQL查询,稳定、好用、好解决,不重要因为不是正式任务,快就行
所以,在一些架构中,70%的服务器资源给YARN跑Hive、Spark等, 30%的资源给Presto等侵入性框架,做StandAlone提供服务。
### 扩展 - Presto的同类竞品
在很多企业中有类似架构,也就是:
- Hive做固定模式的指标计算
- Presto、Impala、HAWQ、SparkSQL等作为即席查询(自助式查询)的引擎。
Presto的同类竞品很多:
- SparkSQL,内存计算,也很快
- Impala,Cloudera公司出品,类似Presto
- HAWQ,EMC公司出品,类似Presto
- RedShift,AWS出品
Hive、Presto、Impala、HAWQ、RedShift、SparkSQL、FlinkSQL,这些都可以满足:
1. 固定模式指标计算
2. 即席查询(自助式分析)
只是:
1. 固定模式更倾向于:Hive
2. 即席查询更不倾向于:Hive,而是其它更快的。
## Spark
Spark整体的定位是:`综合性`分布式`内存`计算平台。
综合性:Java、Python、Scala、SQL都OK,离线、实时都搞的定,甚至图计算、机器学习都OK。
Spark和Flink一样,都想做大而全的综合计算平台,最终目标是排挤全部的其它框架,在企业内部独占,也就是又它就够了。
### SparkCore - RDD
定位:类似MR,基于代码开发,构建离线计算任务。
### SparkSQL
定位:
- 在离线上,类似Hive,以SQL作为主线,构建离线计算任务,同时支持代码开发。
- 在实时上,以`微批`模式来实现实时计算,提供SQL和代码双模式的实时计算开发
### Spark结构化流
就是SparkSQL的实时版本。
特征:
- `微批`模式流计算
- 缺点:延迟高,总归是批处理,批处理就要等待`成批`
## Zookeeper
定位:分布式状态一致性协调工具
### 问题
分布式系统,特点在于数量多,数量多就会产生`分歧`
举例:
```shell
- Kafka的每个Topic的分区的副本有好几个,那么哪个副本是Leader?
- 好多Broker的看法要一致。
- 假设集群有多个NameNode,1个是工作的,其余的是待命的
- 好多的Datanode,对于当前谁是工作的NameNode要看法一致。
- Kafka内部有哪些Topic可以用
- 好多的Broker的看法要一致。
- 因为连接Kafka是可以连接任意一个Broker去干活的。
- node1认为Topic有:TopicA、TopicB
- node2认为Topic有:TopicA、TopicB、TopicC
- 出现了分歧。
- 蜜雪冰城会员卡,在A店能用,B店不能用,但是办理的时候说是全国所有店都可以用。
```
上面的案例,就是问题:`分布式系统的`,`状态不一致`, 也就是大家看法不一致
### 分布式状态一致
分布式系统的各个组成部件,对`同一件事情`的看法要`完全一致`,不受时间的影响。
也就是看法可以改,但是大家都要一致。
Zookeeper就是做这个的。
举例:
- Kafka的每个Topic的分区的副本有好几个,那么哪个副本是Leader?
- 好多Broker的看法要一致,找Zookeeper问,自己说的不算,Zookeeper说啥是啥,以Zookeeper说的为准。
- 假设集群有多个NameNode,1个是工作的,其余的是待命的
- 好多的Datanode,对于当前谁是工作的NameNode要看法一致。
- 找Zookeeper问,自己说的不算,Zookeeper说啥是啥,以Zookeeper说的为准。
- Kafka内部有哪些Topic可以用
- 好多的Broker的看法要一致。
- 因为连接Kafka是可以连接任意一个Broker去干活的。
- node1认为Topic有:TopicA、TopicB
- node2认为Topic有:TopicA、TopicB、TopicC
- 出现了分歧。
- 解决方式:找Zookeeper问,自己说的不算,Zookeeper说有哪些Topic就有哪些Topic,以Zookeeper说的为准。
- 蜜雪冰城会员卡,在A店能用,B店不能用,但是办理的时候说是全国所有店都可以用。
- 解决:找总部客服(Zookeeper),说啥是啥。
分布式状态的不一致,我们就找一个大家信得过的、有威望的(Zookeeper)作老大,统一从Zookeeper哪里接收信息。
### Kafka为什么用Zookeeper
要在Kafka的各个小弟之间同步状态。
比如:
1. 用户基于node1提供的服务,创建了TopicA,在这个过程中,Zookeeper完全知晓
2. Zookeeper记录Topic有TopicA,那么node2和node3就都知道了。
## Kafka
定位:项目中的:`消息中心`,统一的数据中转站
类似公交车枢纽
不论是实时还是离线,都可以应用Kafka作数据中转的。在实际的应用中,批处理的离线项目还是基于批处理的工具更多,比如SQOOP
kafka是实时架构,不管数据的属性是什么,进到kafka内,就成为实时数据了。
纯离线架构一般不怎么用Kafka
离线、实时混合架构,会有kafka
- kafka出来的数据,落地到比如HDFS中,供离线Hive等实用
- Kafka出来的数据,实时连接Spark、Flink等,供实时计算。
## Sqoop
基本定位:ETL数据采集工具
详细定位:`离线批处理`MapReduce架构的数据采集工具
一定要认知到Sqoop是一个批处理工具,一次处理一批数据
什么是批处理:处理的时候数据有明确的起始和明确的结束,也就是被处理的数据范围是确定的。
## Flume
基本定位:实时ETL数据采集工具
详细定位:`实时无状态流计算平台`
Flume的架构是`原生流计算架构`,针对每一条数据做处理,而非针对批。也就是来一条处理一条。
本质上和Flink没啥区别,就是来一条处理一条。
Flink支持各类算子,可以做聚合操作。
Flume只是做简单的无状态处理,比如格式转换、清洗过滤,无法做数据聚合,一般也就是做为数据采集工具、数据传输工具使用。做ETL。
可以认为:
- Flume就是Spark结构化流的Append模式
- Flink就是Spark结构化流的3种模式都OK
> - SQOOP运行完成后,程序结束(批处理一批搞定了)
> - Flume启动后会一直运行,不会停止(流处理,持续处理新数据)
## ElasticSearch
定位:分布式`全文检索`系统,文档型的NoSQL数据库。
重点突出在:全文检索。
全文检索:类似SQL里面的:WHERE name LIKE %xxx%;
特点:高性能、记录海量数据,在海量数据的前提下,可以进行超快的数据检索服务。
> 用来在海量数据中做搜索。
### 画像项目为何用ES
1. 标签是一种海量数据,因为标签是要做到一人一套。
1. 假设是千万用户,每个用户都有十几个标签打上,这就是上亿数据量了。
这种上亿级别的数据量,对大数据来说不够,对很多系统来说已经很大了。
比如:
- 业务系统是计算不了和存不了的。
- MySQL是存不了的
- 亿级别的数据量对MySQL来说如果做高效检索,已经不合适了。(除非你技术特牛,公司技术特牛)
2. 标签也是一种频繁更新的和海量存取操作的
1. MySQL也不合适
3. 标签作为文本类型,是动态的,有模糊匹配需求,以及动态增长需求。
综上所述,ES可以提供全文检索、性能在亿级别起步的数据量上完全OK。
为何不选:
- MySQL,太大了MySQL扛不住
- Hive,太慢
- Presto,快,但是没必要,大材小用
- HBase,HBase的索引条件是固定的,标签搜索是任意的
> 如果不用ES,同类的MongoDB也算可以。
## 编程语言
很多大数据岗位,都要求会:Java、Scala、Python,三选一。
一般来说:
- Scala是过去式了,后续也基本没啥市场了。
- Java和Python在大数据中还有一席之地。
- 都干不过:`SQL`
- 大数据核心主要业务在离线,离线主要做数仓,数仓主要用SQL,所以框架都要配合SQL玩,玩到现在所有框架都以SQL为重点。
- 数仓做指标计算,也就是统计分析,统计分析,SQL最能打,其它的都不行。
> 大数据对于编程语言,无所谓。
>
> 语言的工作是:
>
> - 将人的思想转换为语言代码,如SQL、Python代码
> - 基于SQL、Python代码所承载的逻辑,让框架干活
>
> 用啥无所谓,只要能让框架理解你要干啥,能够准确的描述你要的逻辑即可。
## 存储计算的各个方向
文件存储型:HDFS
存储随机查询型:HBase
全文检索型:ES、MongoDB
`超超超超超高`性能的KeyValue检索(内存缓存):Redis
复杂分析型:Hive、Spark、Flink
- 通用SQL分析:Hive、SparkSQL、FlinkSQL
- 通用分析:Spark、Flink、MapReduce
# 名词
## 离线-实时
### 离线 - Offline
一句话:离线就是不需要网
离线计算,是基于已存在的数据,做一批批的批处理。在计算的过程中无需联网(不会接受到新的数据)
数据仓库就是典型的离线计算,在每天的计算过程中,是无需联网(不需要新数据的,其实也没有),只对当前已经有的数据做批处理计算,一次处理一大批。
对于新数据,可以是比如T+1的模式,每天连一次网,传输一下(每日新增ETL)新数据即可。
离线称之为`批处理`,也称之为有界数据计算。
有界:被计算的数据,有明确的边界(有明确的开始和结束)
### 实时 - Online
实时计算一般也称之为在线计算,需要在计算的过程中联网(会有新数据源源不断的到来)
比如:
- Kafka,在运行的过程中可以源源不断的接收新数据处理
- Spark结构化流,在运行的过程中可以源源不断的对新数据产出结果
实时也称之为:无界数据流计算
无界:被计算的数据,有明确的开始(启动),但没有明确的结束。
### 程序的运行方式
- 离线:启动后运行,运行完成后程序结束。
- 实时:程序启动后运行,一直运行,运行到你主动停掉它或者出现问题才停止,一切正常不会停止,持续运行。
## OLTP-OLAP
### OLTP
Online Transaction Processing:联网`事务`处理
事务:开始和结束是明确的,状态统一的。在OLTP中的事务,指的是对业务进行服务的意思。
OLTP指的是使用计算机技术,对业务(面相用户、消费者)进行开发服务。
> 说白了就是开发功能,服务用户。
>
> OLTP:
>
> - 用户下单
> - 用户查询商品
> - 提交订单
> - 修改用户名,验证密码,注册
> - 。。。
> - 常规的用户、消费者需求
OLTP一般是后端开发(Java开发)的领域,开发后端程序服务用户。
### OLAP
Online Analysis Processing:联网`分析`处理
分析:针对于数据的,统计、计算、数仓那些。
OLAP:
- 数据仓库指标统计
- ETL
- BI
> 大数据主要做的就是OLAP
## 无状态、有状态
一般用户指代计算的过程是否是有无状态的。
### 无状态计算
在计算的过程中,被计算的那一条数据,不需要依赖其它数据或其它服务,数据`本身就足以`完成计算。
举例,SQL的无状态:
> - SELECT CONCAT(name, age) FROM tbl;
> - SELECT YEAR(date_ts) FROM tbl;
> - MONTH()、DAY()等等函数,都是无状态计算。
其它的无状态:
> - 对来的服务器温度监控数据进行判断,一旦超过100度,就报警,发邮件。
> - 对每一条数据从CSV转换为Json格式。
举例,PySpark的:
> - map算子
> - filter算子
> - flatMap算子
> - 都是无状态,都是对数据一条条处理,处理逻辑是针对每一个数据本身,无需依赖其它数据或其它服务。
> 只给一条数据,计算逻辑也足够完成,这就是无状态。
### 有状态计算
在计算的过程中,被计算的那一条数据,`需要依赖`其它数据或其它服务,数据`本身【不】足以`完成计算。
举例,SQL的状态:
> - SELECT SUM(age) FROM tbl GROUP BY gender;
> - 有状态,因为需要每个gender组的`全组`数据才能完成SUM
> - SELECT xxx FROM yyy JOIN zzz;
> - 有状态,需要关联其它数据
> - 聚合操作、Join都是有状态
其它的无状态:
> - 对来的服务器温度监控数据进行判断,一旦`连续5次`超过100度,就报警,发邮件。
> - 每一条被计算的数据,依赖前4条
> - 对每一条数据从CSV转换为Json格式,并且在过程中将CSV中的IP地址,去查询数据库转换为省市区。
> - 依赖其它服务
举例,PySpark的:
> - reduce算子
> - reduceByKey算子
> - fold算子
> - 都是有状态,数据本身不足以计算,需要和前面的结果做累计。
## NoSQL
Not Only SQL,不仅仅是SQL
从这个意义上分析,可以理解为:
- SQL,仅SQL:关系型数据库处理,有主键、外键约束、有事务控制,比如:MySQL、Oracle、SQL Server、DB2、PostgreSQL等
- 关系型数据库的关系:体现表和表(数据和数据)之间的关系连接,也即是:主键、外键。
- NoSQL,不仅仅是SQL:非关系型的一类数据库。重点不体现在关系上,不体现在外键、主键、事务等。而是针对特定的领域做数据库存储,比如:
- 针对基于Key找Value可以有:HBase(KV型)、Redis(KV型)
- 文档型:MongoDB(存Json等文档数据)
- 搜索型:ElasticSearch(全文检索)
- 分析型:Presto、Hive、HAWQ、Impala、Drios、ClickHouse
NoSQL没有普适性,都有`针对性`的应用场景,很难在全场景下都用一个NoSQL搞定。
- NoSQL只要在自己适合的场景下,性能贼野。
- 离开使用场景,啥也不是
关系型SQL有普适性,任何场景都可以用,但是性能嘛,就不咋地。
# 数据仓库
## 数据库和数据仓库
数据库:针对`一类业务类型`做数据存储并提供检索或简单计算的服务。也就是业务数据库。
- 说白了,就是针对业务系统提供数据的CRUD(增删改查,Create Read Update Delete)操作,给用户做服务。
- 说白了,数据库就是做服务的。
数据仓库:针对企业的各类业务数据做`集中存储`,并进行`集中分析`
数据库:一个企业可以有`多个`业务数据库负责不同的场景,比如订单模块业务库、配送模块业务库、金融模块业务库。。。
数据仓库:一个企业一般只有`一个`数据仓库系统(要做`集中`存储和分析,多个就成了数据孤岛)(中央数仓系统)
做分析的最讨厌数据孤岛,数据分散做分析,比如GROUP BY、Join数据都不全,很难受。
大部分分析都是有聚合场景(有状态计算),聚合讲究全部数据到位出的结果才准确。
## 数据孤岛
概念:被分析的数据库,分散在多个系统中。
也就是,一条SQL要跨越不同的系统才能工作,理论上很难且没必要,需要做ETL把数据都集中存储、集中分析。
所以,数据仓库体系解决了分析中的数据孤岛问题。
## 数据仓库的常规分层
> 详细数仓分层,每个公司都不一样,甚至不同业务都不同,为了针对性的做分析。
一般数据仓库有个常规(通用型)分层,可以是:
- ODS(数据原始层、数据贴源层),`Original` Data-Warehouse Service
- 数据在进入ODS,基本上是原汁原味的。
- 数仓计算后面会有很多的清洗、转换、过滤、聚合、Join等操作,后面出问题了,保留原始数据是可以重来的。
- DWD(数据明细层),Data Warehouse Detail
- 对数据进行明细抽取、内容格式转换、垃圾数据过滤等操作
- 对数据进行`精洗`
- DWM(数据中间层),Data Warehouse Middle(中间数据,下一步就基本上结果数据了)
- 对数据在进行指标计算之前,做前置预处理:
- 针对主题域做预聚合(针对销售主题,做相关的维度预聚合)
- 针对主题域做数据维度退化(大宽表)
- 这一层叫做中间层,是中间数据,下一步就基本上结果数据了
- DWS(Data Warehouse Service,数仓服务层)、DWT(Data Warehouse Topic,数仓主题层)
- 这一层就是针对要做的指标做计算了,得到指标计算的结果表(维度聚合表,指标+各个维度的大混合表)
| sales_amount | year | month | day | province | city | district | dim_type |
| ------------ | ------ | ------ | ------ | -------- | ------ | -------- | -------- |
| 333 | 2023 | <null> | <null> | <null> | <null> | <null> | 1 |
| 555 | 2023 | 06 | 11 | <null> | <null> | <null> | 3 |
| 666 | <null> | <null> | <null> | 浙江省 | <null> | <null> | 4 |
| 888 | 2023 | <null> | <null> | 浙江省 | <null> | <null> | 7 |
类似上表,针对销售额指标,混合了全部的维度,基于dim_type来区分每一行是什么维度下的指标结果
- DWS、DWT,一般也被称之为:`数据集市层`
- 集市是买东西的,DWS、DWT卖指标结果的
- 卖指标在不同维度下的结果,用户可以自选,比如需要年维度的销售额,就来表中选择dim_type=1即可。
- 比如上表,卖的是`销售额`结果,用户可以自助选择销售额的维度:
- 按年销售额,请付款:dim_type=1
- ```shell
SELECT slaes_amount, year FROM tbl WHERE dim_type=1;
```
- 按日销售额统计,请付款:dim_type=3
- 按省份销售额统计,请付款:dim_type=4
- ...
- DWS是所有指标的结果表,类似上表,都在DWS中,所以DWS、DWT是个大集市。
- APP(RPT、ADS)层(APP:Application应用,RPT:Report报表,ADS:Analysis Data Service分析服务)
- 最终是指代数据应用层的概念,从DWS中抽取需要的指标结果,做最终应用。
- 比如,在BI报表中,需要针对年做指标展示,可以从上面的DWS中抽取dim_type=1的数据到本层
- PS:有些场景BI会直连DWS,会跳过数据应用层。
- APP、RPT、ADS这是数据应用层的三个叫法,含义一样,就是做数据最终应用。
- APP、RPT、ADS这三个层,可以不在Hive中,是Hive外的,比如APP层可以在MySQL中,但是在架构上是数据数仓的一个层。
> 数仓分层在实际应用中是各个公司各自决定,都不一定相同。思想是一样的:
>
> 1. 按照输入->处理->输出的模式计算
> 2. 按照分步骤(分层迭代)一步步算
## 数仓常用技术架构
在数仓体系中常用的技术架构有如下角色:
- ETL角色
- DataX、Sqoop、Flume、Python、Kettle......
- 存储角色
- HDFS
- 计算角色
- MapReduce
- Spark
- Presto
- 元数据管理角色
- Hive Metastore
- 结合MR计算,就是纯Hive构建数仓
- 结合Spark计算,Spark On Hive构建数仓
- BI报表角色
- FineBI、TableAu、PowerBI、SuperSet(免费开源)
- 调度角色
- `Oozie`、`DS`(海豚调度)、AirFlow
# Spark
## RDD
概念:RDD(Resilient Distributed Dataset)叫做弹性分布式数据集
- 弹性:分区(分布式能力)是可以动态增加、减少的(Shuffle)
- 分布式:RDD这个数据集是`跨越服务器的、跨越进程的`
- 假设RDD存了[1, 2, 3, 4, 5],可能[1, 2, 3]是在node1的内存中,[4, 5]在node2的内存中。 RDD逻辑上的数据[1, 2, 3, 4, 5]是跨越了2个服务器
- 数据集:数据的集合,比如Python中的:`List、Dict、Set、Str、Tuple`都是数据集,能包含一堆数据的都叫数据集。
> RDD描述了一个:可以跨越不同的服务器的,以多分区运行的,数据集
### RDD是Spark的基础操作对象,Spark的所有的功能,都是基于RDD而来
任何Spark的代码,在运行的时候,都是将数据转换为RDD对象,基于RDD对象提供的方法(算子)来进行计算。
在代码上,想要处理分布式的数据集,就必须以RDD来做,这是Spark唯一支持的编程方式。
- 不管Java、Scala、Python,都提供了RDD这个类,你的代码,必须得到RDD类对象,才能继续写下去。
### RDD代码如何运行在集群中的
示例伪代码:
```python
spark = SparkSession.......
local_list = [1, 2, 3, 4, 5]
rdd1 = spark.parallilism(local_list)
rdd2 = rdd1.map(lambda ...)
rdd3 = rdd2.flatMap(lambda ...)
rdd4 = rdd3.reduceByKey(lambda ...)
list = rdd4.collect()
```
代码流程是:从本地list[1, 2, 3, 4, 5]开始 -> RDD -> Python本地集合List结束。
上述代码在:单机、分布式 2个概念上是分离了。
单机代码(不涉及到跨服务器交互):
- spark = SparkSession.......
- local_list = [1, 2, 3, 4, 5] 这只是一个单纯的Python List,Python的List是单机对象,无法跨服务器。
- list = rdd4.collect()得到的结果list,也是一个单机的Python List对象
分布式代码:
- RDD1 -> RDD2 -> RDD3 -> RDD4的转换流程,这是分布式的。
单机代码(非RDD转换代码)运行在哪里? 在Driver中
分布式代码运行在哪里? 在Executor中。
> 上面一整段代码,都是Driver统一协调的,统一控制管理的。
>
> 在运行的时候:
>
> - 单机代码是Driver真正执行了
> - RDD分布式代码,是Driver告知各个Executor应该干什么,由各个Executor具体干活。
### 图解RDD代码如何运行在集群中
```python
spark = SparkSession.......
rdd1 = spark.textFile(HDFS://xxx.txt)
rdd2 = rdd1.map(lambda ...)
rdd3 = rdd2.flatMap(lambda ...)
rdd4 = rdd3.reduceByKey(lambda ...)
list = rdd4.collect()
```
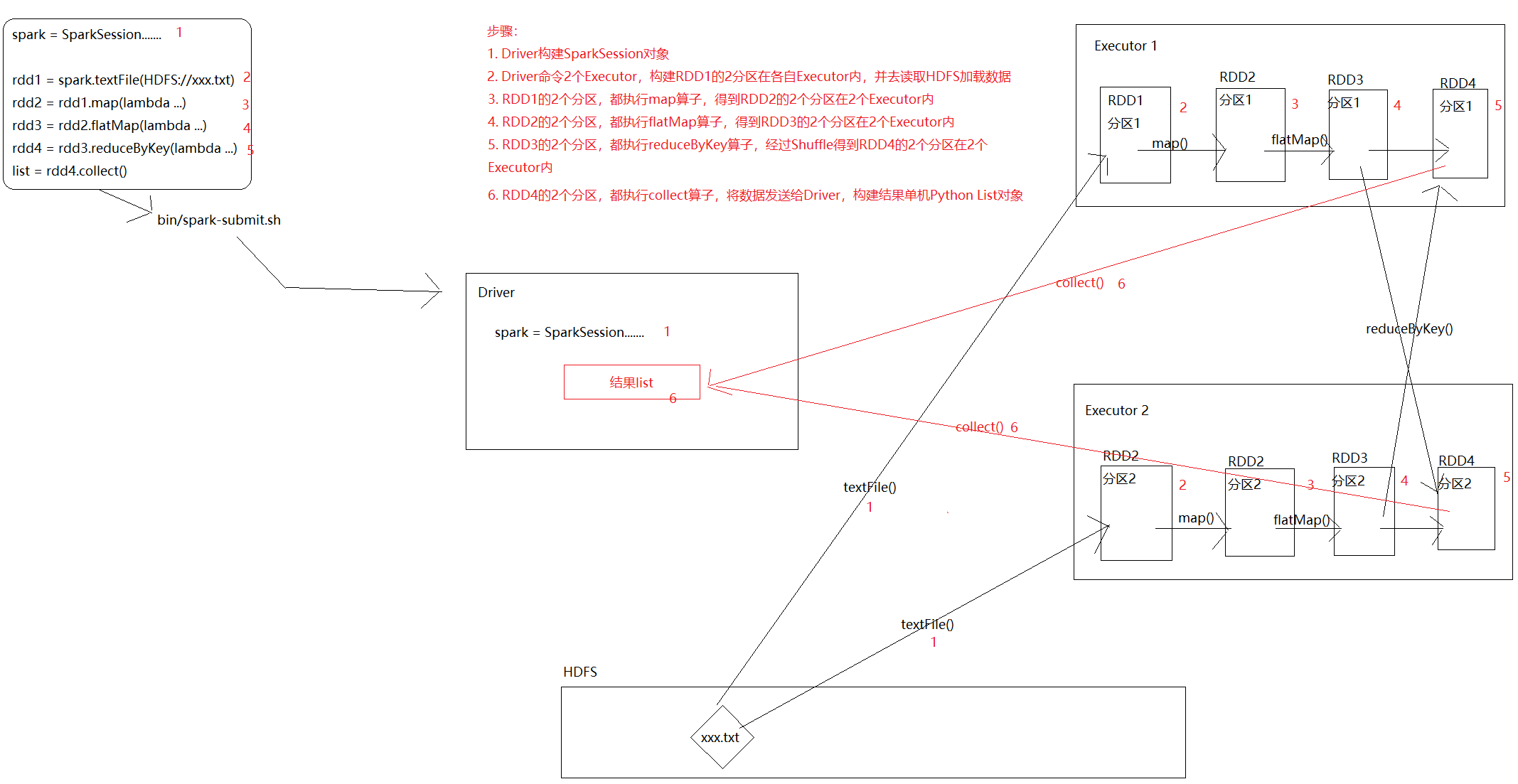
上图中的Spark的`内存迭代计算`,可以发生在下图的绿色框框中(task1和task2,2个并行内存的迭代计算管道)
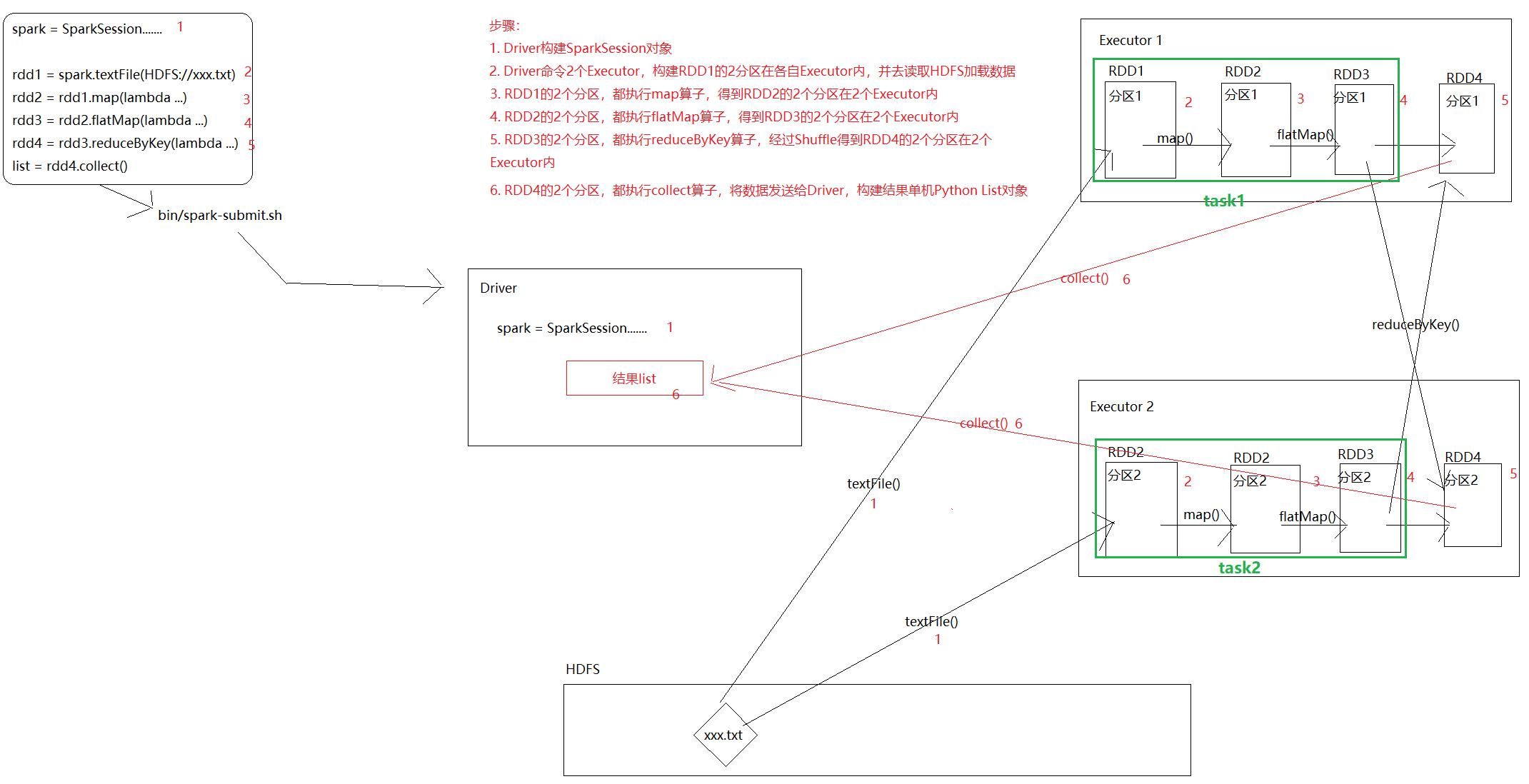
### RDD的五大特性

- RDD有分区,体现RDD的分布式特性的
- 算子在RDD的每一个分区上执行
<img src="https://image-set.oss-cn-zhangjiakou.aliyuncs.com/img-out/2023/07/18/20230718171957.png" alt="image-20230718171957838" style="zoom:50%;" />
如图,map算子应用在RDD1的每个分区上,用来构建RDD2
- RDD之间是有依赖的,如上图,RDD1->RDD2->RDD3->RDD4,也就是有血缘关系
- 某个并行(上图是2个并行)出现问题,可以基于依赖(血缘关系)进行回溯(重新计算)
- 如果是KV型的RDD,默认有Hash分区器,如上图ReduceByKey是基于Key做Hash的Shuffle
- 除了默认的Hash规整外,可以自定义分区器(更换分区的规整,比如不按照Hash来都是可以的)
- RDD在构建的时候(读取HDFS文件),每一个分区所在的Executor会首选,自己所在机器的block块进行读取(加速操作)
### RDD的算子类型
- Transform转换算子,返回值依旧是`RDD`的是转换算子
- Action动作算子,返回值`不是RDD`的是动作算子,包括无返回值也是。
### Driver和Executor
Driver的工作职责是:
- 运行非RDD转换代码,构建基础环境
- `调度、指挥Executor干活`
- 启动、恢复失败的Executor
Executor的工作职责是:
- `在Driver的调度和指挥下:干活`
- 专业术语叫做:接收Driver分配的任务指令,启动对应的Task线程干活。
- 和Driver做任务汇报,反馈消息,反馈数据。
- 启动或恢复失败的Task线程
数量上:
- Driver只有1个
- Executor最少1个,多则不限(Local模式除外)
算子 转换 action,算子是如何工作的
## Spark的各个角色
完整的`Spark环境`要包含如下的4类角色
Spark集群中有4类角色:
- 资源Master角色,管控整个Spark任务可以使用的全部资源
- 资源Worker角色,管控具体某个服务器上可以给Spark提供的资源
- 任务Master角色,Driver,管控`单个Spark`任务的`运行`
- 任务Worker角色,Executor,针对`单个Spark任务`去`干活`
## 运行模式
Spark的运行模式主要有:
- `Local`
- `StandAlone`
- `On YARN`
- Client模式
- Cluster模式
- K8S模式(忽略)
### Local模式
<img src="https://image-set.oss-cn-zhangjiakou.aliyuncs.com/img-out/2023/07/18/20230718173815.png" alt="image-20230718173815459" style="zoom: 50%;" />
如图,Local模式是指:以1个单独的`进程`,提供整个Spark运行环境(4类角色都有)
- 资源Master:Local进程本身
- 资源Worker角色:Local进程本身
- Driver:Local进行内的某个线程
- Executor:不存在(在Spark的WEB页面中,Local模式是不显示Executor)
- 但是,可以启动具体的工作线程,来做具体的工作(其实就是Executor)
Local模式全部的活儿都是,Local模式这个`进程`全干了。
Local模式能够使用你机器的多少CPU资源取决于:`Local[x]`的x(x可以是*,表示全部)
> Local模式很重要,90%的Spark开发的时间,都耗在了Local上。
>
> 主要是做开发、调试、测试用。
### StandAlone模式
Spark的资源管理角色以独立的进程存在运行,就是StandAlone
<img sr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











