




摘要
深度学习几乎彻底改变了计算机科学的所有领域,包括数据管理。然而,对高质量训练数据的需求正在放缓深层神经网络的广泛应用。为此,数据增强(DA)成为一种常见的技术,它可以从现有的示例中生成更多标记的示例。同时,产生噪声示例的风险和超参数的大空间使得DA在实践中不那么有吸引力。我们介绍了Rotom,这是一个多用途的数据增强框架,用于一系列数据管理和挖掘任务,包括实体匹配、数据清理和文本分类。Rotom的特点是InvDA,这是一个新的DA操作符,通过将DA表述为seq2seq任务来生成自然但多样的增强示例。Rotom的关键技术创新之处在于,它是一个元学习框架,可以自动学习将不同DA操作符的示例组合在一起的策略,从而通过组合减少超参数空间。我们的实验结果表明,Rotom通过组合多个DA操作符有效地提高了模型的性能,即使单独应用它们并不能提高性能。凭借这一优势,Rotom在低资源环境下的性能优于最先进的实体匹配和数据清理系统,以及两种最近提出的用于文本分类的DA技术。
最先进的实体匹配和数据清理系统,以及两种最近提出的用于文本分类的DA技术。
如何减少参数空间?以前需要自动调试,现在将这个过程自动化
1 介绍
深度学习系统的爆发导致了许多领域的重大进步,例如自然语言处理 (NLP) 、计算机视觉 (CV) 、机器人等 [19,73,93] 。数据库社区也不例外 [42、61、85、92] 。例如,在数据集成中,通过将实体匹配 (EM) [49] 作为序列对分类任务并在下游EM数据集上训练深度神经网络,可以实现最先进(SOTA)的精度。虽然深度学习已经被证明是有效的,但是对训练数据的质量和数量的高要求正在减缓深度学习系统的广泛采用。为此,最近预训练模型 [19、41、53]的成功部分解决了这个问题,它通过允许开发者首先对大型未标记数据语料库上的模型进行预训练,然后对下游任务的相对较小的标记数据集上的模型进行微调。然而,仅部分解决了该问题,因为微调方法仍然需要大量的高质量标记示例(例如,对于典型EM应用来说为约10k [49,61]) 。鉴于获得质量标记数据的昂贵成本,人们对毫不费力地收集数据产生了极大兴趣 [47,69] 。
基于上述考虑,在本文中,我们研究了在只需要少量(例如200个)标记示例的情况下训练高质量深度学习模型的问题。我们开发了一个多用途系统Rotom,它支持一系列数据管理和挖掘任务,包括实体匹配、数据清理、文本分类。Rotom通过一个简单的微调LMs架构实现了这种多功能性,因此它可以支持任何可以表述为序列分类的任务。
Rotom本质上还是fine-tuning LMs的基础上增加了元学习的数据增强
Rotom 通过数据增强 (DA) 降低了对标记数据的要求。 DA 广泛用于 CV 和 NLP,自动从现有数据中生成额外的标记训练数据。 通常,DA 算子将训练样本转换为不同的版本,同时保留分类标签(例如,CV 任务的图像旋转或 NLP 任务的同义词替换词),因此它扩大了训练集并允许模型学习不同的不变性。(即类似与CNN具有局部不变性特征)多个 DA 算子可以被组合成一个 DA 策略以获得更好的结果。 Rotom 遵循元学习范式,以一种新颖的方式利用增强数据,因为它学习了一种选择和分配权重给增强示例的策略,以更好地训练目标LM。
利用元学习的思路,对增强数据的方式也进行了创新,即为增强示例选择和分配权重。
Challenges
为Rotom中的广泛应用开发普遍有效的DA运算符并非易事。下面我们将说明现有数据增强技术的两个主要限制因素,并深入了解我们如何在Rotom中解决这些问题。
即不能改过头,那样会错误;也不能改太少,那样说了等于没说
FIRST
首先,尽管数据增强通过增加训练数据的多样性被证明是有效的,但它有改变真实标签的风险。使用这些损坏的示例进行训练可能会损害目标 LM 的质量。
Example 1.1. Consider classifying the intent of a sentence:
Where is the Red Book? [Intent: Location]
即使只应用一个DA运算符,也会生成不保留原始标签的“wrong”示例。例如,如果简单地用另一个疑问代词“What”替换“where”一词,则生成的句子将具有不同的含义,并且意图将变成【asking for a description】。类似地,如果在“bowl”之后插入单词“From”,这很可能在使用语言模型预测insertion时发生,则问题意图也会变成【 asking for a description】。如果应用一系列DA运算符来获得更多样化的扩充示例,则更有可能得到“wrong”示例。
将DA运算符限制为那些改变句子含义风险最小的运算符 (例如,用字典中的同义词替换单词) 可以避免此问题,但会生成与原始示例几乎相同的示例,从而导致较少的性能增益。因此,对于数据增强,在多样性和质量之间存在权衡:对于生成更多样化示例 (例如一次应用多个运算符) 的方法,标签损坏的风险更高 [86]。调整这种权衡对于提高模型的性能很重要。
Rotom通过
(1) 引入新的DA运算符InvDA来解决这一挑战,该运算符可以通过将DA定义为seq2seq问题来生成多样而又自然的示例;
(2) 设计一种过滤/加权模型,该模型从潜在损坏的增强池中选择良好的增强示例。
这里的corrupted不仅仅是delete,各种DA操作符都会使得原始序列corrupted
SECOND
其次,找到最有效的 DA operators or policies是非常重要的。DA算子经常引入一组新的超参数。例如,简单的词替换变换具有至少两个超参数:
(1) 用于选择要替换的词的采样sample方法【定位方法】
(2) 用于选择要替换的同义词的基于字典 [59] 或基于相似度的方法 [60] 【替换方法】
在实践中,开发人员需要不断尝试组合并重新训练模型,直到结果令人满意。这个过程效率低下,依赖于启发式方法,经常导致次优选择。在CV中,一直有在努力自动寻找有效的DA政策 [16,51] 。然而,这些搜索算法通常被固定到模板 [32,44],例如,两个连续的简单变换,因此不支持简单变换以外的运算符,也不防止它们生成不良示例。
搜索算法固定到模板是啥意思?所谓的自动寻找,只是按照固定的模板去寻找。
我们通过考虑更一般的设置来应对这一挑战:Rotom 不是组合 DA 算子,而是组合由多个 DA 算子生成的增强示例。算子可以是简单的转换、基于生成的算子(例如 InvDA)或任何复杂的学习算子。无需手动调整超参数, Rotom 利用元学习自动学习优化策略,用于
(1) 过滤掉噪声增强
(2) 根据剩余示例的重要性重新加权。
因此,Rotom 有效地选择并组合了每个算子的高质量部分,以更好地训练目标模型。(通过组合示例,而不直接组合算子的方式)
在不手动调整超参数的情况下,Rotom利用元学习来自动学习优化的策略。
- 元学习的目标是学习得到一组合适的超参数,而不再是hand-crafted
Contributions
本文的贡献如下。
-
我们介绍了Rotom,这是一个多用途的数据增强系统,用于一系列数据管理和挖掘任务,包括实体匹配,数据清理和文本分类。Rotom将这些任务建模为序列分类(sequence classification),并通过fine-tuning诸如BERT之类的预训练语言模型 (LMs) 来解决它们 [19]。图1描述了Rotom的体系结构。
只要可以建模为序列分类的任务,都可以用Rotom解决
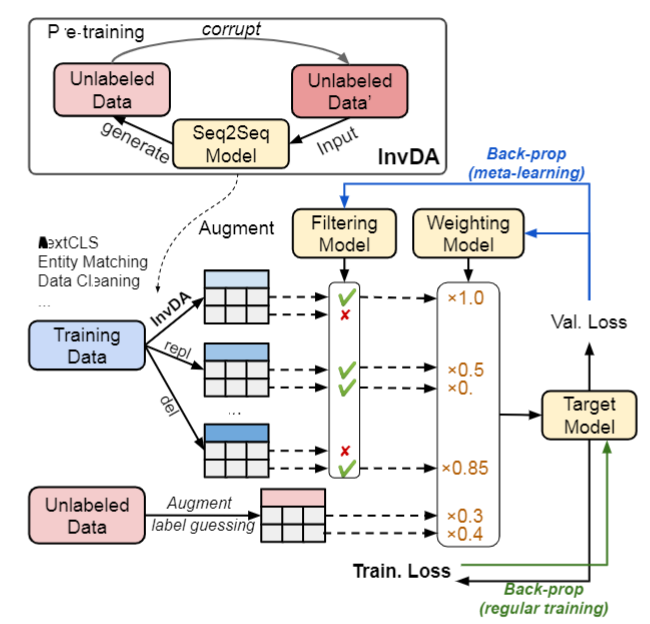
图一:Rotom DA框架用于实体匹配、错误检测、文本分类等。Rotom的InvDA算子通过重建损坏的未标记序列来学习seq2seqDA模型。Rotom还提供了一个半监督的元学习框架,用于过滤和加权增强的和未标记的示例。过滤+加权模型与目标模型通过下降到低验证损失来联合训练。
Rotom的InvDA算子通过重建损坏的未标记序列来学习seq2seqDA模型。
不知道理解的对不对:注意,这种训练方式属于自监督学习。而只所以使用unlabeled sequences(这里的unlabel是针对下游任务而言),是我们需要用与任务无关的数据进行预训练。
-
我们在 Rotom 中引入了一个通用的数据增强算子 InvDA。基于 seq2seq 生成模型,InvDA 可以生成与原始序列任意不同的自然和多样化的增强序列。通过完全自动化的自我训练过程,我们允许 InvDA 学习如何通过反转多个简单转换的效果来增强。
-
Rotom具有元学习框架,该框架对大量增强的示例进行过滤和加权,以将其组装成高质量的训练信号【training signals】。Rotom无需手工制定DA策略,而是与目标模型共同地自动优化过滤/加权模型。结果,过滤/加权模型 “学习” 如何更好地选择和组合增强的示例,以提高目标模型的整体性能,从而解决了DA中的多样性-质量权衡。
什么是Rotom中的元学习思想:无需hand-craft DA policy,而是通过过滤/加权模型,学习得到如何组合出合适的增强示例。
-
我们展示了 Rotom 可以自然地扩展到半监督学习 semi supervised learning (SSL) 设置,以利用大量未标记的数据。 虽然猜测标签的大量质量差异是传统 SSL 的主要挑战,但元学习框架使 Rotom 能够仅选择高质量的猜测,从而进一步提高目标模型的性能。
半监督学习方法的性能依赖于所用的半监督假设
元学习如何评估半监督学习的质量?即所加权重的依据是什么?
-
我们进行了广泛的实验,以评估所有3个受支持任务的基准数据集上的Rotom。我们的实验结果表明,Rotom有效地结合了简单的DA运算符,InvDA和未标记的示例,即使独立应用它们不会产生性能提升。利用这种能力,Rotom的性能优于
- F1得分优于SOTA EM系统最高达6%
- F1得分优于SOTA错误检测系统7.64%
- 以及两种最近的低资源文本分类技术。
Paper outline
论文的其余部分组织如下。第2节回顾了支持的任务,第3节介绍了InvDA操作。我们将在第4节介绍我们的元学习框架。我们将这个框架扩展到第5节中的半监督设置。第六部分给出了实验结果。最后,我们在第7节讨论相关工作,并在第8节结束。
2 准备
在本节中,我们首先回顾并正式定义我们论文中考虑的任务。接下来,我们介绍了一种针对这些任务的的基线方法【baseline method】,即微调预训练语言模型 (LM) 。我们还总结了基本的数据增强算子,它们生成额外的训练数据以优化微调基线。
3种任务都基于微调-预训练语言模型
2.1 Problem definition
实体匹配和数据清洗的序列分类
Rotom的目标是一般形式的序列多分类任务

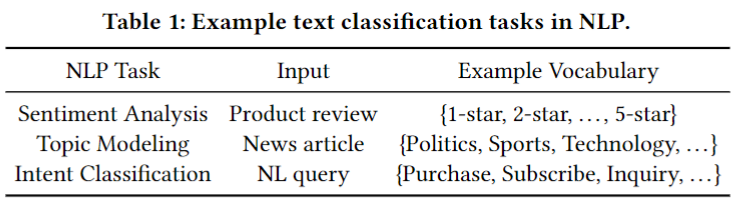
上述定义常用于表述自然语言处理中的文本分类问题,具有广泛的应用范围。例如,在情绪分析中,输入序列可以是一个产品评论,分类器预测评论的二元情绪类(即积极或消极)。表1总结了一些文本分类应用的例子
虽然上述设置在NLP中最常用,但它也适用于许多数据管理任务。接下来,我们将回顾两个这样的任务:实体匹配和数据清理。
实体匹配(EM)
给定两个数据条目集合,EM[12]试图识别是否引用相同的真实世界实体的数据条目对。EM工作流[37]有两个主要步骤:阻塞【blocking】和匹配【matching】。阻塞阶段通常使用简单的启发式【heuristics】方法(例如,一对匹配的记录必须共享至少1个令牌)来识别一个相对较小的候选对集。接下来,匹配阶段对每个候选对是否为真实匹配进行分类。
启发式算法(heuristic algorithm)是相对于最优化算法提出的。一个问题的最优算法求得该问题每个实例的最优解。启发式算法可以这样定义:一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般不能被预计。
形式上,假设每个数据条目𝑒由一组键-值对{ (attr𝑖,val𝑖)}1≤𝑖≤𝑚\left \{ (attr_𝑖,val_𝑖)\right \} _{1≤𝑖≤𝑚}{ (attri,vali)}1≤i≤m表示。
给定一对数据条目(e,e′)\left(e, e^{\prime}\right)(e,e′),一个匹配的模型𝑀在{0,1}中输出一个标签,其中M(e,e′)=1 if (e,e′) is a match and 0 otherwise M\left(e, e^{\prime}\right)=1 \text { if }\left(e, e^{\prime}\right) \text { is a match and } 0 \text { otherwise }M(e,e′)=1 if (e,e′) is a match and 0 otherwise
通过将匹配问题表述为一个序列分类任务[49],可以有效地解决该匹配问题。在[49]之后,我们将两个条目中的所有属性/值序列化并连接到一个序列中。
For example, consider two entries {Name: “Google LLC”, phone: “(866) 246-6453”} and {Name: “Alphabet inc”, phone:“6502530000”}, we can serialize them as
“[COL] Name [VAL] Google LLC [COL] phone [VAL] (866) 246-6453 [SEP]
[COL] Name [VAL] Alphabet inc [COL] phone [VAL] 6502530000”
然后我们可以应用序列分类技术来解决匹配任务。请注意,我们插入了特殊的标记[COL]和[VAL]来指示属性或值的开始。
特殊的标记[SEP]可以将这两个条目分开
数据清洗
给定一组关系表,数据清理[29,33,54,55]的目标是识别并修复表中的任何错误,如拼写错误、数据格式化错误或约束违反。我们主要关注识别错误条目的问题的第一部分,这也被称为错误检测[29,55]。表2显示了错误检测问题的一个示例实例。

在Rotom中,我们将错误检测转换为与EM一样的序列分类。我们可以通过连接特殊的标记来序列化我们想要检查的正确性的单元格值。例如,对于表2的最后一个单元格,我们生成序列“[COL]phone[VAL]6502530000”。为了检测与上下文无关的错误,即仅与单元格值相关的错误,我们可以使用这个字符串作为序列分类器的输入。对于与上下文相关的错误,我们将整个行序列化为“上下文”,并附加到感兴趣的单元格的末端(由“[SEP]”分隔)。
例如,为了检测第三行最后一个单元格的错误,我们用下面的序列作为输入
关于序列化数据条目的讨论
由于它的构想很简单,所以Rotom支持任何可以转换为序列分类的任务。这使得Rotom成为了一个灵活的解决方案。例如,如[49]中所示,序列化EM的数据条目允许输入实体具有任意的模式,因此在匹配之前不需要模式对齐【schema alignment】。然而,序列化并不总是能产生最好的性能。例如,在错误检测中,可能存在违反表级约束的错误类型,如聚合约束和函数依赖关系。捕获这样的约束需要序列化整个表,这很容易超过LM允许的最大序列长度。从这个意义上说,Rotom更擅长于可序列化为文本和中等长度的序列(例如,数百个标记)
每个LM都有对应的最大序列长度
2.2 Baseline
Fine-tuning language models
微调预训练语言模型(LMs)已被证明是一种简单而有效的序列分类[19,67]方法。预训练的LMs,如BERT[19]和GPT-2/3[8,66],在广泛的NLP任务中显示出良好的性能。这些模型通常是由Transformer层[83]组成的神经网络,通常是12层或24层,并通过自监督学习在大型文本语料库,如维基百科上进行预训练。在预训练过程中,对模型进行自我训练self-trained,执行诸如缺失标记和预测下句【missing token and next-sentence prediction】等辅助任务,使模型能够学习捕获输入序列的词汇或语义意义。
我们可以在下游任务中利用预训练LM,通过在特定任务的训练集上进行微调。对于序列分类,这可以通过以下步骤来完成:
(1)在LM的最后一层之后添加特定的任务层【task-specific layers】
具体地说,我们添加了一个输出维数等于类数的全连接层和一个softmax分类器作为最终的层来进行多类分类。
(2)用预训练LM的参数初始化修改后的网络N。
(3)训练N在训练集上直到收敛。
图2显示了一个LM的模型架构。
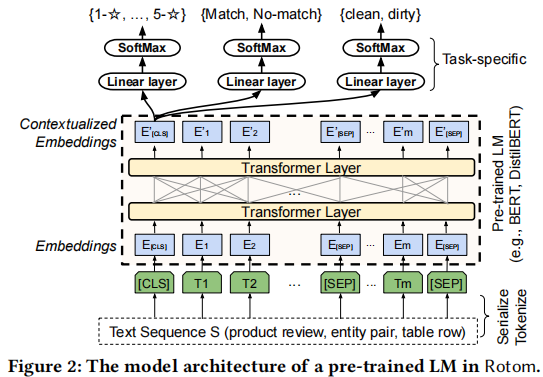
该模型由(1)a token embedding layer(2)Transformer层,使用自注意机制捕获序列语义[83],(3) the added task-specific layers(linear followed by softmax)用于下游分类任务。从概念上讲,[CLS] token“总结”了分类所需的所有上下文信息,作为上下文嵌入向量𝐸[CLS]′𝐸'_{[CLS]}E[CLS]′,可以作为分类[19]的输入特征提供给特定任务的层。
𝐸[CLS]′𝐸'_{[CLS]}E[CLS]′为分类token([CLS])对应最后一个Transformer的输出,𝐸[i]′𝐸'_{[i]}E[i]′ 则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务(如,序列标注和问答任务),就把𝐸[i]′𝐸'_{[i]}E[i]′输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把输入到𝐸[CLS]′𝐸'_{[CLS]}E[CLS]′额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
2.3 Simple data augmentation operators
上述微调方法的成功在很大程度上取决于高质量的标记训练数据的数量。当训练数据量不足时,数据增强(DA)是一种常用的技术。例如,在计算机视觉中,人们可以通过执行简单的转换,如旋转或翻转原始训练图像来获得额外的训练示例,并期望图像的标签保持不变。对于文本分类,这种简单的转换可以是插入或删除单个标记。简而言之,DA由一个保留原始训练示例的标签的转换操作组成。
除了扩大训练集外,DA还提高了训练模型对数据噪声的鲁棒性,因为模型被迫“更努力地学习”。例如,通过应用删除操作【deletion operator】,模型学习了不变性属性【invariance property】,即当删除单个标记时,句子的含义保持不变。
DA的优点
- 扩大训练集
- 提高训练模型对数据噪声的鲁棒性【robustness】:学习样本的invariance property。例如CNN模型可以捕捉到局部不变性一样,我们也希望模型能够捕捉到文本和序列中的不变性。
数据增强对Rotom[29,49,86]的所有3个支持任务都有效。我们在表3中总结了我们在Rotom中实现的简单增强运算符。每个运算符在不同的级别上转换输入序列:标记【token】、跨度【span】、列/属性【column/attribute】或实体【entity】。token的采样可以是均匀采样,也可以是根据每个标记的重要性进行抽样。我们通过其反向文档频率inverse document frequency (IDF) 来衡量token的重要性,以便更多地replaced/deleted不重要的令牌。我们通过wordnet [60] 获得token的同义词。我们注意到,这个列表绝不是完整的。Rotom的用户可以选择添加为特定任务定制的转换。 【Users of Rotom have the option of adding transformations customized for a specific task.】

限制
有几个因素限制了上述简单的DA操作符在实践中的有效性
(1)首先,由这些DA操作符生成的例子是不自然的,即偏离了原始的序列分布。对于文本分类,生成的序列可能有语法错误,因此对于某些任务可能是不可取的。(这点不容忽视)
(2)其次,简单的DA操作符不能生成更多样的同时保留类标签的示例。例如,由token_repl生成的序列与原始序列最多相差1个标记。跨级运算符【span level operators】可能会过多地更改序列,从而破坏标签。
(3)第三,结合这些DA算子引入了一个大的超参数空间。开发人员需要从一个操作池【pool of operators】中进行选择,以及使用不同的特定于操作的选项【different operator-specific options】。因此,在以前的工作[49,58,86]中,通常只枚举和选择性能最好的单个DA操作符,这可能会导致次优性能。
combining these DA operators introduces a large space of hyper-parameters.
超参数空间大指的是如何具体选择DA算子,对于所选择的DA算子如何设置,如果是组合,则更加复杂,这些都是需要在训练之前设置好,而如何设置则太难去考虑。
operator-specific options:例如,对于token_repl,要设置采样方式(抽样、基于重要性)、替换方法(相似度(如果是相似度,哪种相似度,阈值多少)、字典),对于span-level,考虑span长度等等
3 seq2seq数据增强
接下来,我们介绍了InvDA,一个新的DA算符,用于Rotom生成自然而多样的增广序列。
InvDA是一个在 task-specific的序列语料库上训练的seq2seq模型。
也是在大型预训练网络上进行微调
3.1 Seq2seq model
seq2seq(序列到序列)模型[80]𝑀gen将一个输入序列𝑠作为输入,并生成一个新的序列序列𝑡=𝑀gen(𝑠),我们称之为目标序列。Seq2seq模型通常用于NLP任务,如机器翻译或文本摘要,它们的输出是一个完整的序列,而不是一个类标签(即,这些任务是生成性的【generative】,而不是有区别的【discriminative】)。该模型通常由一个编码器和一个解码器组成,其中编码器接受𝑠并将其映射到一个固定大小的向量表示,而解码器基于这个向量表示顺序预测token,以生成一个目标序列𝑡。
seq2seq:Encoder—语义编码C—Decoder
Seq2seq模型已用于文本数据增强[44,90]。将数据增强表述为序列生成问题的主要优点是模型的灵活性。与限制原始序列更改次数的简单转换不同,seq2seq模型具有不受限制的输出空间,这意味着它的输出可以与输入任意不同。然而,使用这些seq2seq模型仍然有一些缺点,因为它们没有在下游任务的领域上进行训练。例如,我们不能直接对用于文本数据的seq2seq模型[44,90]给EM和EDT任务,因为EM和EDT中的序列通常不是句子,而且这种在大型自然语言语料库上训练的seq2seq模型可能不会生成接近EM和EDT输入的分布序列。因此,需要在task-specific的语料库上训练基于seq2seq的DA方法,以生成更多样化的序列。
本质上是通过Seq2seq模拟真正可以同义替换的句子。
这种Seq2seq model没法直接借助在大型自然语言语料库上的训练过的seq2seq模型。这节的最后,我们用一种更有效的预训练模型T5,配合下游task-specific的训练数据集来实现。
具体如何训练?接下来会介绍InvDA,InvDA是一个在任务特定的序列语料库上训练的seq2seq模型。
3.2 Inverse data augmentation
接下来,我们描述了我们的基于seq2seq的DA方法InvDA。如前所述,InvDA模型需要进行适当的训练,以确保增强序列的质量。seq2seq模型的训练数据由一个输入-目标序列对【input-target sequence pairs】组成。训练一个高质量的seq2seq模型通常需要大量这样的对。例如,一个典型的EN-DE翻译模型[83]是在超过450万对正确翻译的英语德语句子对上进行训练的。
训练出一个高质量的seq2seq模型需要大量的pairs
为了训练InvDA来完成下游任务,理想情况下,需要提供输入-目标对,其中输入是任务的原始序列,而目标是一个“好的”增强。如果增广序列是下面这样,则它很好:
(1)语义保留【semantics-preserving】
(2)来自与输入相同的序列分布【格式,形似】
(3)尽可能地与输入序列不同【内容,神不似】
然而,在实践中,如果没有人工注释【human annotations】,很难自动获得这种输入-目标对。因此,我们提出了一种新的自监督方法来训练InvDA模型。
如果自动获得这种pairs,需要工作量极大的人工注释成本。
解决方法:我们用自监督的方式来进行训练。
我们的方法背后的直觉是,虽然很难获得高质量的增强示例,但原始的训练示例对于某些输入序列可能是高质量的增强。
此外,我们还可以通过破坏corrupting原始序列来获得这些序列【即上面的“某些输入序列”】,这可以通过应用多个DA操作符(删除令牌s、交换令牌s顺序等)来实现。我们在算法1中正式地描述了这个过程。

从概念上讲,seq2seq模型𝑀gen𝑀_{gen}Mgen学习了如何反转或恢复【被多个简单的DA操作符所破坏序列的】效果
the seq2seq model 𝑀gen learns how to invert or restore the effect of corrupting a sequence by multiple simple DA operators。
这句话如何理解?学习如何翻转或恢复【因_______破坏的】效果
在预测时,我们应用𝑀gen𝑀_{gen}Mgen对原始输入序列sss进行变换。𝑀gen𝑀_{gen}Mgen的训练示例【即输入-目标对】通过构造满足上述(2)和(3)的要求,因为目标序列【target sequences】来自原始训练集【original training set】,可以通过控制应用增强的数量【 controlling the number of applied augmentations】与输入序列任意不同。
满足3吗?尽可能地不同于输入序列?也算满足,毕竟是可以控制operator梳理
语义保留的(1)要求不那么明显。从直觉上看,corruption过程通常会从输入序列中“removes”信息(例如,从“I want to eat a sandwich”中删除“sandwich”会提供 input-target pair“I want to eat a”——“I want to eat a sandwich”作为训练)。在预测时,我们可以期待有一个添加信息的反向效应【expect an inverted effect of adding information】,例如,给定原始训练集中的另一个序列*“I want to eat at the cafe”*作为输入,seq2seq模型可以生成“I want to eat sandwich at the cafe”这可能保留了来自输入的意义,并且比简单的DA操作的输出更接近于原始训练集【original training set】的分布。
何为Inverse data augmentation?通过corruption过程,我们从输入序列中“removes”信息。但是,在训练的过程中,迫使模型能学习到这部分信息,即the models are forced to “learn harder”.那么在预测时候,在模型的输出序列中,就有了添加信息的反向效应【inverted effect of adding information】
通过破坏来学习!与预训练中,BERT的预训练目标Masked language model (MLM)的思想一致!
注意在训练时,target sequence为原始训练集中的序列。上述中,“I want to eat a sandwich”“I want to eat at the cafe”这两句话都来自原始训练集,因此对于“I want to eat at the cafe”的预测结果“I want to eat sandwich at the cafe”显然比简单DA更接近原始训练集
我们在表4和表5中的例子中观察到了这种效应。
Choice of models and generation methods
虽然上述方法允许对InvDA进行全自动训练【fully automatic training】,但从头开始训练seq2seq模型仍然是不可行的,特别是在训练集𝑆较小的情况下。我们再次通过利用预训练过的模型来解决这个问题。最近提出的预训练的seq2seq模型,如BART[46]、T5[67]和GPT-3[8],可以通过相对少量的训练数据来微调到下游任务。我们在我们的实现中选择了12层的T5-base model[67],因为它的规模相对较小,并且可以适用于多个任务,包括机器翻译、总结和问题回答。
T5模型:Transfer Text-to-Text Transformer
借助预训练模型,对InvDA进行训练,要比从头开始训练seq2seq模型快的多
对于其他基于序列生成的DA方法,请参阅第7节以了解这些技术的讨论并与InvDA进行比较。在第6.5节中,我们还比较了实验性的InvDA和之前基于生成的文本分类方法[44]。
3.3 Examples
我们在表4和表5中为Rotom支持的3个任务的InvDA示例。


在文本分类方面,InvDA生成的3个序列都是很好的增强,因为它们保留了位置寻找【location seeking】的语义含义【semantic meaning】,同时自然地与原始序列有很大的不同。在错误检测示例中,InvDA(令我们惊讶的是)可以从一个真实的电影名称“DUFF”中生成自然的假电影名称,以便它们保持原始数据条目的正确性【preserve the correctness of the original data entry.】。在实体匹配方面,InvDA将术语“关系数据库”重写为“数据库”、“数据库系统”和“开源数据库”等有意义的术语。
只所以说在EDT中,生成了自然的“假”电影名仍然保持了数据条目正确性,是因为我们数据清洗的目标是清洗语法错误的单元。
另一方面,我们观察到,由简单的转换生成的序列有些不自然,或偏离了原来的意义。虽然InvDA可以生成更自然和多样化的例子,但不能保证保留原始标签,因此仍然需要进一步对增强的例子进行过滤和加权。
如何实现filtering and weighting?借助元学习,将整个过滤和加权的过程,视作是一个Learning Algorithm,即是一个可学习,可优化的目标。
4 元学习来选择和结合增强的例子
target model是为classifier服务的
meta-learner是为target model服务的,以便【target model更好地为classifier服务】
机器学习模型的性能在很大程度上取决于该模型所训练的数据。因此,当我们应用DA(简单转换或InvDA)时,确保增强的示例的高质量是至关重要的。 在Rotom中,我们通过将其作为一个优化问题来实现这个目标。
将“ensure that the augmented examples are of high-quality”作为一个优化问题,也就是我们元学习的目标,meta-objective
我们设置的优化目标是【找到一组由任何DA算子生成的增强示例的集合】,以优化在该集合上训练的目标模型的性能。请注意,这比选择要应用的DA运算符的子集是一个更一般的设置。对于生成不同且有噪声的示例的DA算子,我们期望Rotom从有噪声的示例中分离出“good portion”,而不是完全保留或完全放弃由算子生成的所有示例。
注意,我们要寻找的目标模型,是要在增强数据集上具有良好表现的目标模型。
与选择DA运算符的区别是,存在即合理,取其精华去其糟粕
形式上,对于一个语言模型𝑀和一组训练数据S,我们用Train(𝑀,𝑆)表示在𝑆上微调的模型𝑀:

问题1(DA优化)
给定一个要训练的(文本分类、实体匹配、错误检测)模型𝑀,带标签的训练集StrainS_{train}Strain,验证集SvalS_{val}Sval,一组DA运算符𝐷,和要最小化的函数损失,找到一个子集Saug ⊆Ud∈D{ d(s)∣s∈Strain }S_{\text {aug }} \subseteq U_{d \in D}\left\{d(s) \mid s \in S_{\text {train }}\right\}Saug ⊆Ud∈D{ d(s)∣s∈Strain }以使得loss(Train(M,Saug),Sval)loss\left(\operatorname{Train}\left(M, S_{\mathrm{aug}}\right), S_{\mathrm{val}}\right)loss(Train(M,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











