







赫夫曼(哈夫曼)给出了求最优树的方法,该方法的关键就是:从带权为(这里假设
)的最优树T'中得到带权为
的最优树
比如我们要求带权 7 8 9 12 16 的最优树
那么我们就要使得每个节点尽可能的小这样求出来的节点的就会尽可能的小
所以我们可以重复执行如下操作:
- 排序数组
- 取出数组的前两个数相加
- 将相加后得到的数放回数组
即可得到最小的节点值例如刚刚的数据我们模拟一边可得
//第一次 : 7 8 9 12 16 ( 7 + 8 ) --> 9 12 15 16
//第二次 :9 12 15 16 ( 9 + 12) --> 15 16 21
//第三次 : 15 16 21 (15 + 16) --> 21 31
//第四次 :21 31 ---> 52
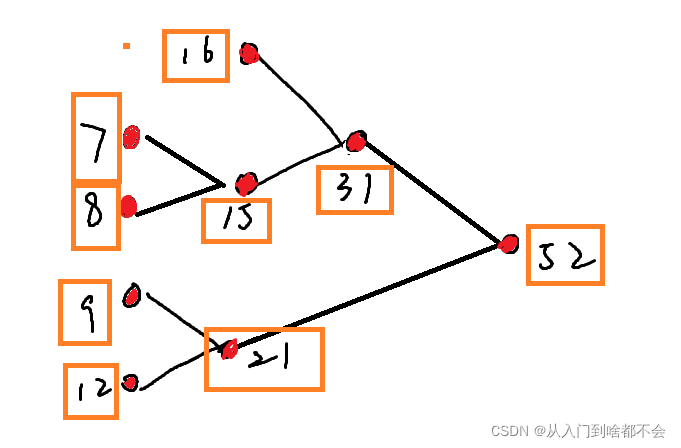
就像是上图的一颗最优树 我们可以发现每个节点一定是最小的子节点
那么我们就可以用这个思想来解决一个问题——合并果子
题目描述:
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过 (n−1) 次合并之后, 就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为 1,并且已知果子的种类数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。
例如有 3 堆果子,数目依次为 1,2,9, 。可以先将 1、2 堆合并,新堆数目为 3,耗费体力为 3。接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 12,耗费体力为 12。所以多多总共耗费体力为 3+12=15。可以证明 15 为最小的体力耗费值。
数据范围:
对于 30% 的数据,保证有:
对于 50% 的数据,保证有 ;
对于全部的数据,保证有 。
输入格式
输入的第一行是一个整数 n,代表果子的堆数。
输入的第二行有 n 个用空格隔开的整数,第 i 个整数代表第 i 堆果子的个数 。
输出格式
输出一行一个整数,表示最小耗费的体力值。
输入
3
1 2 9输出
15那么首先我们从题目中可以很清晰的看出来 :
例如有 3 堆果子,数目依次为 1,2,9, 。可以先将 1、2 堆合并,新堆数目为 3,耗费体力为 3。接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 12,耗费体力为 12。所以多多总共耗费体力为 3+12=15。可以证明 15 为最小的体力耗费值。
是这样的一个过程来得到的最小消耗体力
那么我们再回到刚刚的哈夫曼树的过程我们会发现这个题目的过程简直和哈夫曼树得到最优树的过程一摸一样
那么我们就可以得到核心代码(因为考虑到频繁的取出和插入元素我们可以使用队列)
int a = q.front();q.pop();
int b = q.front();q.pop();
int s = a + b;
q.push(s);//插入后排序
ans = ans + s;循环上面的代码过程
·Attention:
考虑到我们要对队列进行排列 因此我们可以使用 "小根堆"来实现这个算法 代码如下
//小根堆的定义
//头文件
#include <queue>
priority_queue<int,vector<int>,greater<int>> heap;//会自动排序使最小的数在堆顶
//这是一个特定的语法,所以可以背下来使用
heap.top();//取堆顶元素
heap.push(x);//将x推入堆中
heap.pop();//删除堆顶元素下面的就是AC代码了
AC Code
#include <iostream>
#include <queue>
using namespace std;
int n;
int main()
{
priority_queue<int,vector<int>,greater<int>> heap;
cin >> n;
for (int i = 0; i < n; i ++ )
{
int a;
cin >> a;
heap.push(a);
}
int t = 0 , s = 0 , ans = 0;
while( heap.size() > 1 )
{
t = heap.top(); heap.pop();
s = heap.top(); heap.pop();
ans = ans + t + s;
heap.push(t + s);
}
cout << ans;
return 0;
}

















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











