 Elasticsearch中文分词实践
Elasticsearch中文分词实践





 本文详细介绍了在Elasticsearch 6.4.1环境下安装和使用中文分词器IKAnalyzer的过程,包括配置、扩展及通过Java API和REST API测试分词效果的方法。
本文详细介绍了在Elasticsearch 6.4.1环境下安装和使用中文分词器IKAnalyzer的过程,包括配置、扩展及通过Java API和REST API测试分词效果的方法。
一:使用背景和安装过程.
1.1 ElasticSearch-6.4.1.(Windows环境下)
ElasticSearch默认的分词器对中文分词器支持不好,下面安装中文分词器.Linux下是一样的安装方式就是wget+url然后新建目录,解压到指定的目录下,然后重启ES即可.
1.2 中文分词器IKAnalyzer下载.
1.3 来到ElasticSearch的安装目录.
新建目录:ik

1.4 将刚才下载的IK解压到ik目录下.

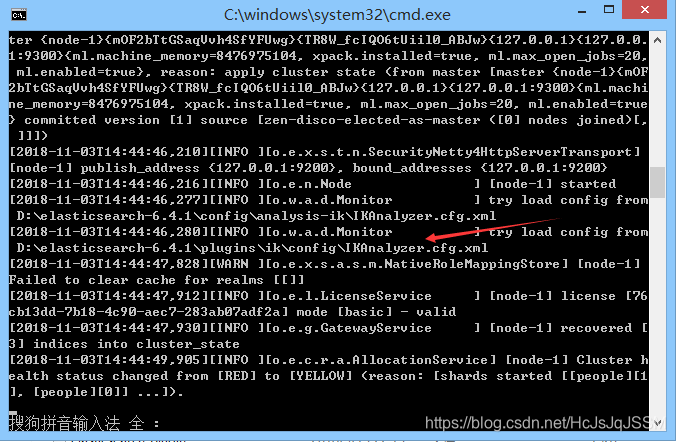
1.5 启动ElasticSearch.(观察一下启动日志).

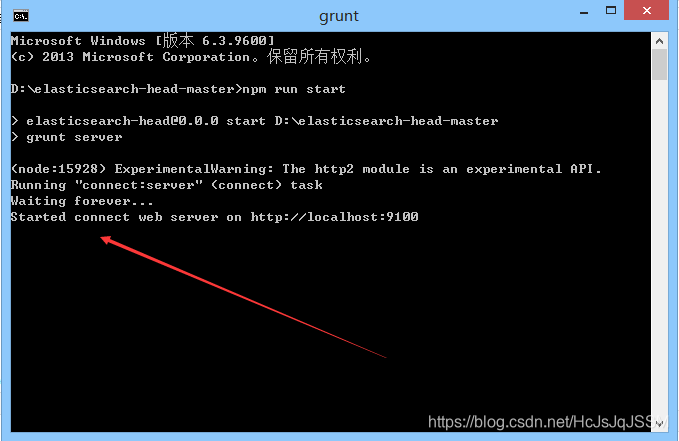
1.6 启动head插件.
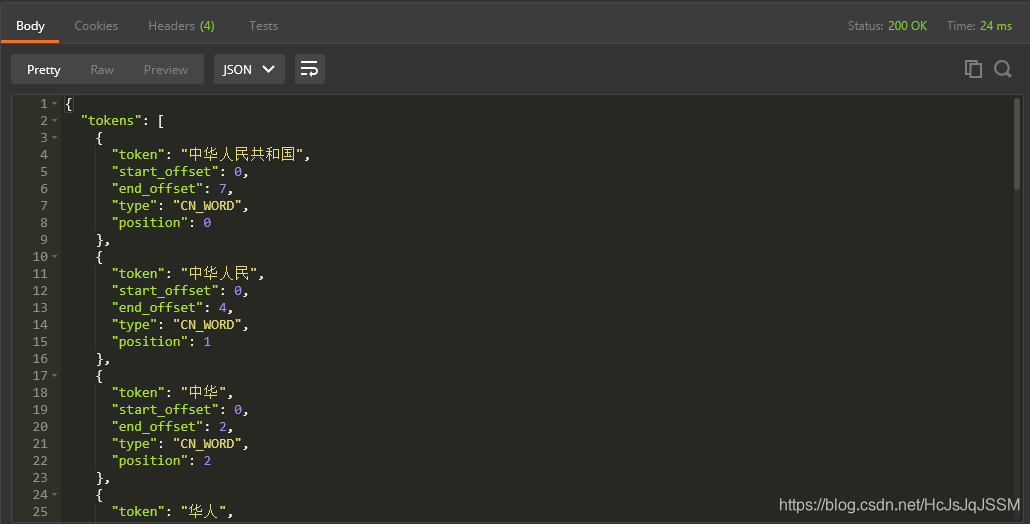
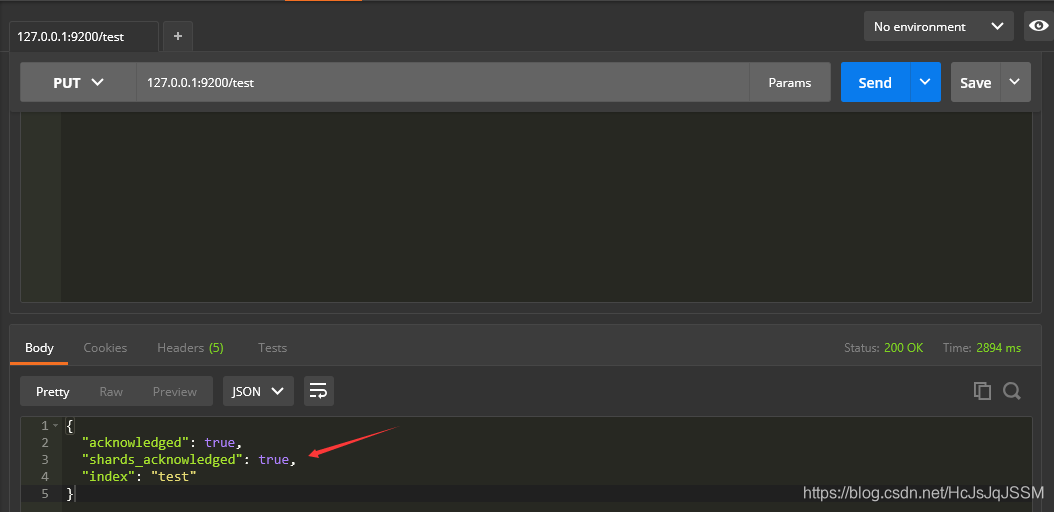
1.7 测试IK分词器.(PostMan下测试)
1. 7.1 一个删除ES索引的测试.(自己测试的,与本文无关). 
1.7.2 IK分词效果有两种,一种是ik_max_word(最大分词)和ik_smart(最小分词)
现在的分词文本是:中华人名共和国港珠澳大桥建成通车.
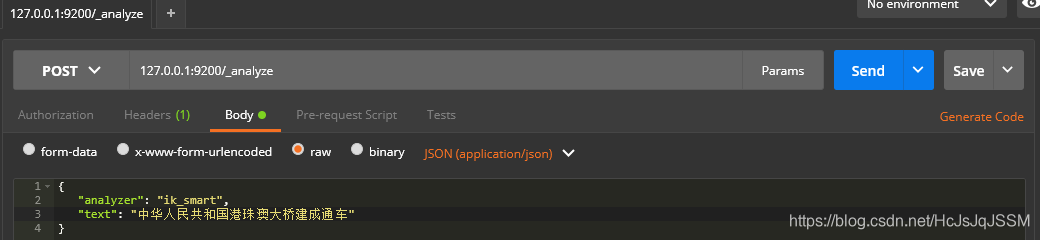
1.8 REST API 使用AK分词器.
1.8.1 测试最大分词效果.




1.8.2 测试最小分词效果.


二. JAVA API使用AK分词器.
2.1 首先新建一个索引.
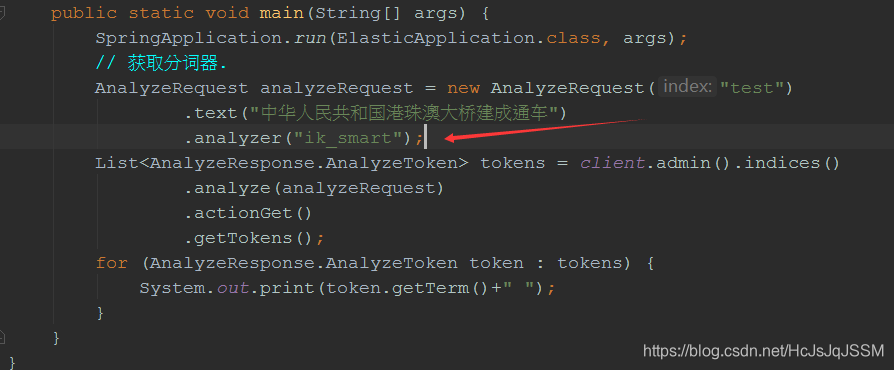
2.2 Java API使用分词器.
首先是获取TransportClient对象. 注入静态方法中注意初始化的方式.
使用标准分词器.
public class ElasticApplication {
private static TransportClient client;
@Autowired
public void setClient(TransportClient client){
ElasticApplication.client=client;
}
public static void main(String[] args) {
SpringApplication.run(ElasticApplication.class, args);
// 获取分词器.
AnalyzeRequest analyzeRequest = new AnalyzeRequest("test")
.text("中华人民共和国港珠澳大桥建成通车")
.analyzer("standard");
List<AnalyzeResponse.AnalyzeToken> tokens = client.admin().indices()
.analyze(analyzeRequest)
.actionGet()
.getTokens();
for (AnalyzeResponse.AnalyzeToken token : tokens) {
System.out.print(token.getTerm()+" ");
}
}
}运行结果:
 使用最大分词器.
使用最大分词器.
 运行结果:
运行结果:
 使用最小分词器.
使用最小分词器.
运行结果:

可以对比最小分词效果没有最大的分词效果好一些.
三 扩展IK分词库.
3.1 扩展的步骤非常简单,这里以Linux环境演示一下.
cd /usr/local/elasticsearch-6.4.1/plugins/ik/config/(切换至ik分词器的配置文件目录).
mkdir custom(创建一个自定义的目录,用于放置自定义的分词.)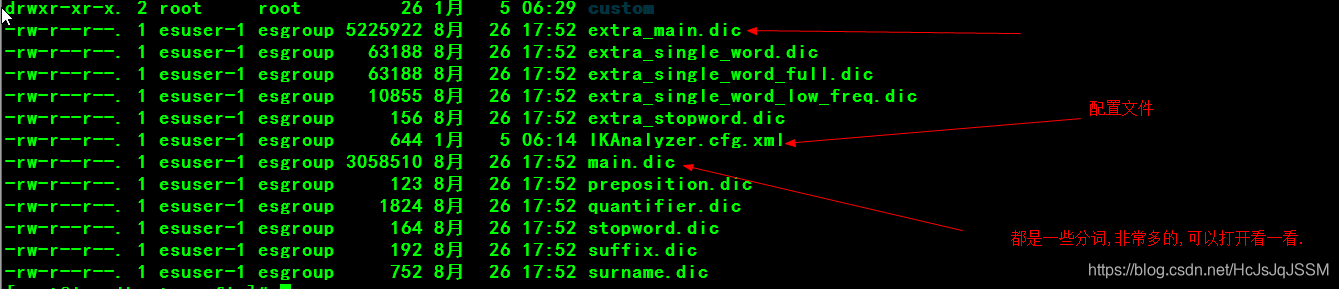
touch hotwords.dic(创建自定义的热词).

修改ik分词器的配置.

3.2 启动ES.确定自定义热词已经加载了.
![]()

3.3 Postman工具里面进行测试一下.EX6.4.X可以使用Post和Get方式查看分词效果,要以Json格式数据存在Body中.
使用最小分词器.
测试结果①:
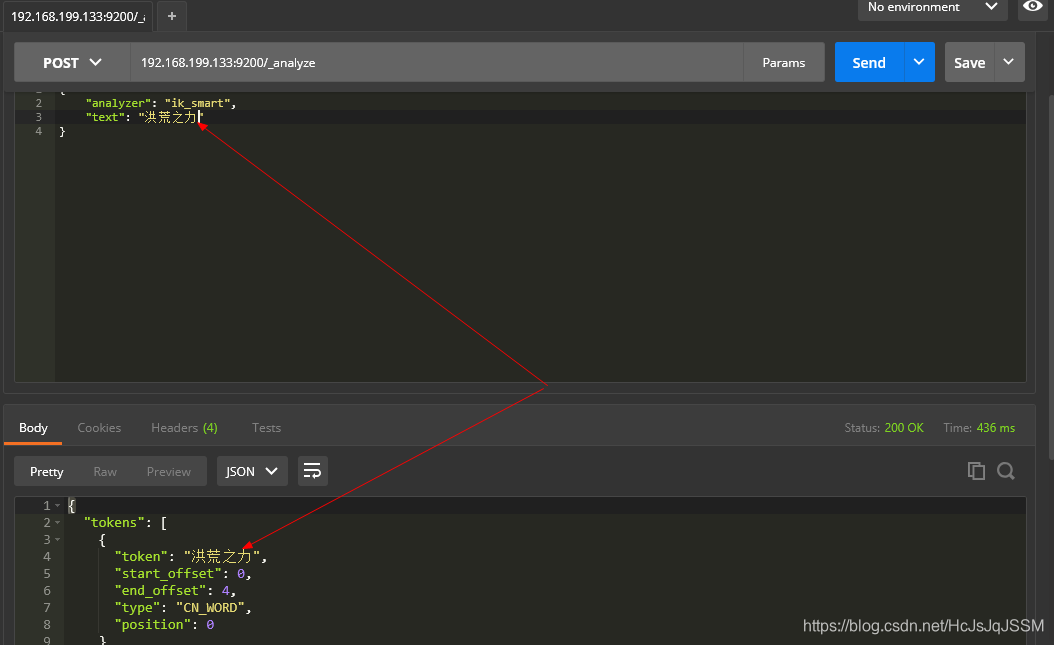
测试结果②
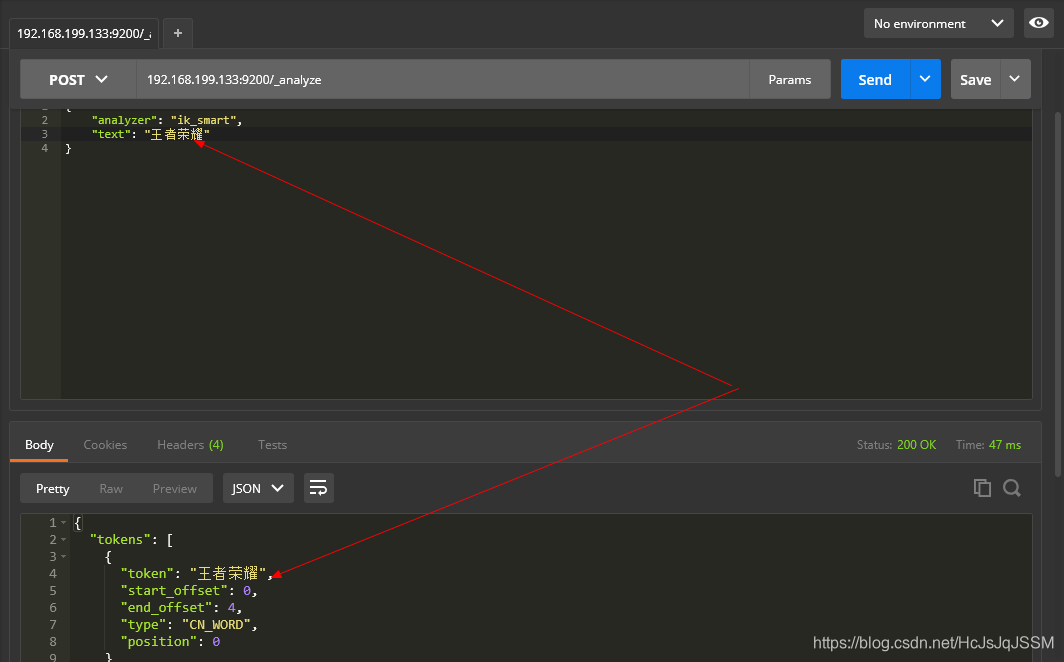
测试结果③

测试结果④

实质上就是作为一个整体,不进行切分,观察IK的那些词库,做了非常详细的切分词条.


















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











