




范围覆盖:java基础,集合框架,jvm,spring,redis。(无序,后期整理)
在北京做Java开发如何月薪达到两万,需要技术水平达到什么程度?
https://www.zhihu.com/question/39890405redis,那我说下自己被面过的问题:--begin--(以下是一些需要把这里大部分问题都搞清楚融汇贯通之后才能答的,烧脑,烧脑,加油吧!)
39、redis有序队列实现,跳表的实现,
redis源码分析之有序集SortedSethttps://www.jianshu.com/p/75ca5a359f9f |
| Redis SortedSet实现原理及跳表:https://blog.youkuaiyun.com/linyu19872008/article/details/72403962 |
40、map各种底层数据结构实现的优劣(哈希表,红黑树,跳表等)。
| 红黑树、B(+)树、跳表、AVL等数据结构,应用场景及分析,以及一些英文缩写:https://www.cnblogs.com/charlesblc/p/5987812.html |
| https://blog.youkuaiyun.com/moneyshi/article/details/50593243 |
41、redis的key过期的实现,用的什么数据结构,定期机制具体操作过程,为什不用定时器?redis定时器怎么实现的,实现支持百万级定时器你有什么好的设计思路?
| 回答同问题1: |
42、还有就是问些跟集群相关的。分片为啥不用一致性hash?和redis方案比有啥优劣。
43、数据迁移的具体过程,假如迁移过程中迁出节点挂了会怎样?
| 数据迁移:https://blog.youkuaiyun.com/liaokailin/article/details/47670895 |
迁移过程中的问题:http://www.360doc.com/content/16/0425/23/16915_553797555.shtml |
44、java smart client实现原理。(不知道,应该不会问吧)
45、如何实现节点的高可用,一致性怎么保证?raft协议怎么设计的?
| 自己好好想想吧http://blog.51cto.com/anyisalin/1739115 |
46、redis事务怎么实现的,了解mysql事务实现吗?计算机本身实现事务的原理?有了解过分布式事务怎么做吗?
| 好好想想再答 |
47、阿里的tcc和mysql的xa了解吗?两段提交协议是啥?
48、有了解过zookeeper吗?如果要你实现分布式事务你怎么做?
工作四年经验问的,可能针对某个点一直问下去,问到你不会为止(CTO)。
| 回复鲁肃:
大神平常用到的东西都会研究原理甚至自己实现一遍吗,萌新刚毕业一年,只对消息队列原理清楚 |
| 回复潘璋[2]:
一般都是先看下别人资料或者文档研究下原理,然后再去看代码,逼着自己去实现一个简单的。其实数据库设计这方面是我不咋熟的,自己只写过简单的只在本地k/v数据库,而且持久化特性的事务还没实现,就是原理可能了解一点,因为写的过程中会反过来加深理解。 |
| 回复鲁肃:
我目前也是类似,自己写了一个消息队列,研究了主流的几个,刚毕业有点浮躁,总感觉时间不够用 |
| 回复潘璋[2]:
那你比我要厉害的多,我在你这个时期还没这个动手的意识。 |
---end---
1.如何实现redis的key失效
| redis key失效的话,如果是代码层面,用setNx设置key的有效时间;如果问的是底层策略的话,redis保存了起始和有效时间,有三种策略,一个是在get时检查当前时间是否满足,二是启动定期检查,三是淘汰,应该就不算如何实现了 |
| 问:主动失效的流程,如何保证下一轮可以继续上一轮的检测,默认的通过检验的比例是多少,让你来实现,你打算怎么做 |
| 这个知识我忽略了,下来补补,三克油先。如果让我来实现的话,我会用hash值来做,不管是单机的,还是高可用的集群形式,数据的安放都是在一个固定的范围内的,检测比率不应该太大,redis是单线程的,影响读写性能,比如把这个范围分N份,每次扫一份这样,然后同步删除持久化文件,我想到的大概是这样吧 |
redis的key失效机制(自己整理,从源码角度。) https://blog.youkuaiyun.com/Happy_wu/article/details/79695415 |
如何保证下一轮可以继续上一轮的检测http://blog.sina.com.cn/s/blog_48c95a190101e5hv.html 代码段五给出了函数activeExpireCycle的实现及其详细描述,其主要实现原理就是遍历处理Redis服务器中每个数据库的expires字典表中,从中尝试着随机抽样REDIS_EXPIRELOOKUPS_PER_CRON(默认值为10)个设置了失效时间的主键,检查它们是否已经失效并删除掉失效的主键,如果失效的主键个数占本次抽样个数的比例超过25%,Redis会认为当前数据库中的失效主键依然很多,所以它会继续进行下一轮的随机抽样和删除,直到刚才的比例低于25%才停止对当前数据库的处理,转向下一个数据库。这里我们需要注意的是,activeExpireCycle函数不会试图一次性处理Redis中的所有数据库,而是最多只处理REDIS_DBCRON_DBS_PER_CALL(默认值为16),此外activeExpireCycle函数还有处理时间上的限制,不是想执行多久就执行多久,凡此种种都只有一个目的,那就是避免失效主键删除占用过多的CPU资源。代码段五有对activeExpireCycle所有代码的详细描述,从中可以了解该函数的具体实现方法。 |
| 默认的通过检验的比例是多少https://blog.youkuaiyun.com/wwd0501/article/details/51900063 |
| 处理定时任务:https://blog.youkuaiyun.com/orangleliu/article/details/52038092 |
2spring里对aop的扩展。(昨天写的都丢了,好心痛,csdn再这样我就不用你了。)
| https://isudox.com/2017/05/24/spring-aop-guide/ |
| https://www.cnblogs.com/hq-123/p/6008695.html |
| https://www.cnblogs.com/wangzheand/p/5939618.html |
| http://www.cnblogs.com/zrtqsk/p/3735273.html |
3.gc执行原理 snap,card,为什么并发标记会使full加一。基础点的吧,怎么看哪个对象占内存太大。(接着问题1)
GC执行原理。用不同的策略,用到的GC方法不一样,这个应该分情况说,比如我现在用的parNew+cms,从root向下遍历,所有没有被引用的对象被视为垃圾对象,其他视为存活对象,当young区满时,回收垃圾对象,释放空间,移动存活对象到s区,设置年代,控制进入看年代的时机,大致原理就是这个样子吧 notify()呢,这么重要的方法 |
| 能聊清楚GC和G1就可以了:https://blog.youkuaiyun.com/renfufei/article/details/41897113 |
| http://www.importnew.com/23035.html |

4.object类有哪几个方法?
| object这个。作为顶级类,实现了一些重要的方法,具体几个忘了,最常见也常用的hashcode equals clone tostring 还有析构函数,还有线程启停相关的通知等待?常用的记得,不常用的记不清 |
| 1,构造函数 2,hashCode和equale函数用来判断对象是否相同, 3,wait(),wait(long),wait(long,int),notify(),notifyAll() 4,toString()和getClass, 5,clone() 6,finalize()用于在垃圾回收 |
5.hashmap底层数据结构?
| HashMap这个。1.7的版本,是数组加单向链表的形式,初始大小16,初始阈值0.75,超过容量会扩容,1.8版本用红黑树优化了链表结构。 |
| https://www.cnblogs.com/holyshengjie/p/6500463.html |
6.悲观锁和乐观锁?
| 悲观锁和乐观锁。主要是乐观锁的实现吧我觉得,采用CAS操作,比较内存内的值和预期原值是否一样,一样则替换内存值为新值。不一样则自旋等待下次资源抢占。 |
乐观参考此处乐观的并发策略——基于CAS的自旋https://www.kancloud.cn/seaboat/java-concurrent/117870 |
| 悲观锁和乐观锁存在的问题:https://www.cnblogs.com/qjjazry/p/6581568.html |
7.分布式架构中,如果优雅的下线一个服务?
| 分布式架构下线实例。分为两类吧,一类是web服务,一类是内部rpc服务。web服务的话,要在vip层或者说是ngix层,删除当前实例,断掉当前实例的流量。然后在下实例。rpc服务的话,其实也是一样, |
聊聊微服务的架构与应用:http://www.cnblogs.com/binyue/p/3430204.html分布式服务框架原理(一)设计和实现:https://www.cnblogs.com/binyue/p/5312193.html
分布式调用跟踪系统的设计和应用:
http://www.cnblogs.com/binyue/p/5703812.html
|
8.rocketmq 消息中间件,消息生产者发送消息失败怎么办?消费端消费失败怎么办?消息是如何持久化的?
| 我接触的是kafkaMQ |
阿里RocketMQ:http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/ |
9.Redis怎么持久化到磁盘上?
Redis如何做持久化的? bgsave做镜像全量持久化,aof做增量持久化。因为bgsave会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要aof来配合使用。在redis实例重启时,会使用bgsave持久化文件重新构建内存,再使用aof重放近期的操作指令来实现完整恢复重启之前的状态。 对方追问那如果突然机器掉电会怎样?取决于aof日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。 对方追问bgsave的原理是什么?你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行bgsave操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。 |
https://www.jianshu.com/p/bedec93e5a7b |
aof由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。 |
10.创建线程池有几种方法?其中一个最大线程数参数是做什么的?
| 聊聊并发(三)Java线程池的分析和使用:http://ifeve.com/java-threadpool/ |
| Java-线程池专题 (美团面试题):https://www.cnblogs.com/aspirant/p/6920418.html |
创建线程池的几种方法:
①newSingleThreadExecutor
单个线程的线程池,即线程池中每次只有一个线程工作,单线程串行执行任务
②newFixedThreadExecutor(n)
固定数量的线程池,没提交一个任务就是一个线程,直到达到线程池的最大数量,然后后面进入等待队列直到前面的任务完成才继续执行
③newCacheThreadExecutor(推荐使用)
可缓存线程池,
当线程池大小超过了处理任务所需的线程,那么就会回收部分空闲(一般是60秒无执行)的线程,当有任务来时,又智能的添加新线程来执行。
④newScheduleThreadExecutor
大小无限制的线程池,支持定时和周期性的执行线程
|
11.nignx 负载均衡策略有哪几种?
轮询:将请求依次轮询发给每个服务器。 最少链接:将请求发送给持有最少活动链接的服务器。 ip哈希:通过哈希函数决定请求发送给哪个服务器。 权重: 务器的权重越高,处理请求的概率越大。 服fair(第三方):按后端服务器的响应时间来分配请求,响应时间短的优先分配。 |
| http://www.jb51.net/article/106158.htm |
12、集合在迭代时候进行删除操作,抛了异常,怎么处理?
| 循环外部删啊 |
| 嗯 集合迭代时,我和上个哥们也是一样认为,在写代码的时候就要避免迭代时候改变集合本身,应该无法预料到会发生什么吧 |
https://www.cnblogs.com/goody9807/p/6432904.html https://blog.youkuaiyun.com/cmder1000/article/details/73865815 |
| 在第一种情况下编译和运行都是可以的,第二种和第三种则会抛出 java.util.ConcurrentModificationException 的异常,这是为什么呢? 这种情况一般是出现了用迭代器的同时发生了list.remove(a)造成了Arraylist与Iterator本身状态的不一致。 基本上ArrayList采用size属性来维护自已的状态,而Iterator采用cursor来来维护自已的状态。 当size出现变化时,cursor并不一定能够得到同步,除非这种变化是Iterator主动导致的。 从上面的代码可以看到当Iterator.remove方法导致ArrayList列表发生变化时,他会更新cursor来同步这一变化。但其他方式导致的ArrayList变化,Iterator是无法感知的。ArrayList自然也不会主动通知Iterator们,那将是一个繁重的工作。Iterator到底还是做了努力:为了防止状态不一致可能引发的无法设想的后果,Iterator会经常做checkForComodification检查,以防有变。如果有变,则以异常抛出,所以就出现了上面的异常。如果对正在被迭代的集合进行结构上的改变(即对该集合使用add、remove或clear方法),那么迭代器就不再合法(并且在其后使用该迭代器将会有ConcurrentModificationException异常被抛出). 如果使用迭代器自己的remove方法,那么这个迭代器就仍然是合法的。 |
13、反射在jvm中是如何实现的? 说说你对jvm调优的理解,说说你最得意的项目,说说内置群的底层实现原理是什么
| 我也调过jvm,有个原来tp99 200多ms,调到了90多等等。 |
| 类加载机制:https://blog.youkuaiyun.com/u014470581/article/details/51350679 |
java反射在jvm实现:http://www.58maisui.com/2016/08/20/123/ 反射使程序代码能够接入(已经在jvm中的)类的内部信息,允许在编译与执行时,而不是源代码中选定的类协作的代码。 反射在Java中可以直接调用,只不过最终调用的仍是native方法。 |
14、内置锁的实现原理synchronized
| synchronized 是如何实现的:https://blog.youkuaiyun.com/zhanghaor/article/details/64519043 |
15、redis的io模型是什么,解释下,
| https://zhuanlan.zhihu.com/p/24252862?refer=belief |
| redis的io模型。传统的阻塞io肯定是无法满足要求,因为会被读写请求堵住,无法直接返回,影响效率,redis应该采用的是多路复用io,具体c代码没看,我觉得大概上和NIO差不多吧,用选择器,管道,这些东西实现快速高效返回。到底是不是,不太清楚,求指点 |
| 问:另外多路复用还有个事件分发,reactor 去了解下,还有proactor,问道reactor一般都会继续问到 |
| 问:基础还是不扎实,多看看吧,面试官一般会深入,比如你提到io多路复用,肯定后续问select poll epll区别,以及如何实现的,epoll有没有bug 以及怎么解决 |
16、spring循环依赖是怎么解决的,说说源码怎么实现的,spring的异常机制说一下
17、redis的io模型是什么,解释下,spring循环依赖是怎么解决的,说说源码怎么实现的,spring的异常机制说一下这些都是基础,大厂1-2面,后续更多是匹配你的项目去问,问你怎么实现,有什么缺点,如何优化,比如服务高可用,redis集群有几种分片方式,各有什么优缺点
| 问:主要看面试官对redis熟悉不熟悉,上面提到redis集群分片有哪些方式,redis中有没有gc 怎么实现gc,这些,光是redis就能问你一小时,所以不是特别了解就别写到简历中去 |
| 回复问:
redis能了解到线程模型,底层数据结构,一些命令的实现方式,同步模型,客户端分片就差不多了。再往下,就算不会,我觉得面试官也算过了 |
| 回复:
是的,但是面试官会考验你的深度,你都写熟悉redis了,结果还浮于表面,可想其他技术 |
| 问:上面基本都是基础,其实最重要还是你自己的项目,挖掘项目中的亮点,而且2面之后大部分集中在你项目中,可能捎带项目问一些基础知识,不过硬问你基础的 |
| 回复:
2面以后都是考核对当前项目的了解,发掘项目的亮点和自己平时的工作想法。往往经验不足都是这里体现出来的,每次我都说不出来遇到什么技术挑战,就是一个业务狗 |
| Redis 和 I/O 多路复用:https://zhuanlan.zhihu.com/p/24252862?refer=belief |
spring循环依赖是怎么解决的: Spring循环依赖的三种方式:https://blog.youkuaiyun.com/u010644448/article/details/59108799 从源码角度:https://blog.youkuaiyun.com/a1548178885/article/details/51744891 |
spring的异常机制: Spring MVC异常统一处理的三种方式:https://www.cnblogs.com/junzi2099/p/7840294.html |
redis 集群的分片: https://www.cnblogs.com/houziwty/p/5167075.html https://blog.youkuaiyun.com/ai2713165/article/details/50513974 https://blog.youkuaiyun.com/weijiaxiaobao/article/details/51311747 |
20、spring是如何解决循环依赖的?
spring循环依赖。这个问题比较恶心,因为spring也没有真的解决循环依赖,即使解决也是限制了单例bean的前提下,我觉得,写代码的时候避免才是最好的解决办法 |
| 问:对不了解的,干脆就别说,不要不了解还硬去说,面试官印象会不好,你自己了解下spring是如何循环依赖的,以及什么时候无法解决 |
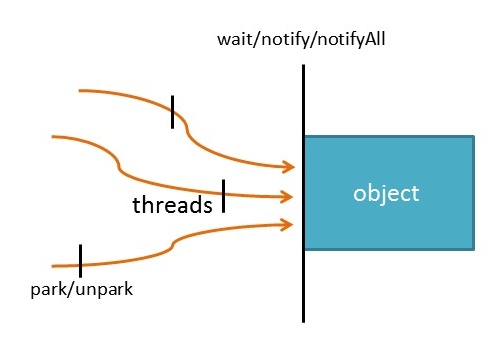
18、notify的实现原理是什么?跟park unpark有什么区别
通常,多线程之间需要协调工作。例如,浏览器的一个显示图片的线程displayThread想要执行显示图片的任务,必须等待下载线程 downloadThread将该图片下载完毕。如果图片还没有下载完,displayThread可以暂停,当downloadThread完成了任务 后,再通知displayThread“图片准备完毕,可以显示了”,这时,displayThread继续执行。 以上逻辑简单的说就是:如果条件不满足,则等待。当条件满足时,等待该条件的线程将被唤醒。在Java中,这个机制的实现依赖于wait/notify。等待机制与锁机制是密切关联的。例如: |
|
作者:阔宁
链接:https://www.zhihu.com/question/26471972/answer/343611736 JDK1.8后,ReentrantLock及ReentrantReadWriteLock是基于AQS实现的,AQS内部使用了unsafe类进行操作;LockSupport也是基于unsafe类操作。可以说LockSupport也是阻塞的,但是不会发生Thread.suspend 和 Thread.resume所可能引发的死锁问题。而AQS是非阻塞机制。 LockSupport.park()和unpark(),与object.wait()和notify()的区别? 主要的区别应该说是它们面向的对象不同。阻塞和唤醒是对于线程来说的,LockSupport的park/unpark更符合这个语义,以“线程”作为方法的参数, 语义更清晰,使用起来也更方便。而wait/notify的实现使得“阻塞/唤醒对线程本身来说是被动的,要准确的控制哪个线程、什么时候阻塞/唤醒很困难, 要不随机唤醒一个线程(notify)要不唤醒所有的(notifyAll)。
|
19、aqs, cas, volatile内存语义, happens before。。。
AQS构建锁和同步器的框架。是通过一个双向的FIFO 同步队列来完成同步状态的管理,当有线程获取锁失败后,就被添加到队列末尾,让我看一下这个队列。红色节点为头结点,可以把它当做正在持有锁的节点,由上可知,它把head和tail设置为了volatile,这两个节点的修改将会被其他线程看到,事实上,我们也主要是通过修改这两个节点来完成入队和出队. https://zhuanlan.zhihu.com/p/27134110
|
| CAS和volicate :https://blog.youkuaiyun.com/sinat_35512245/article/details/60325685 |

21、讲一下你对分布式事物的理解? 22、如何用zookeeper实现分布式锁的? 58、分布式一致性是啥?原理?几种实现的优缺点(未回答)
| 分布式锁。常见的分布式锁原理其实是一样的,比如redis的分布式锁,就是利用了redis的单线程,然后用存在则失败的原语设置flag。zk的分布式锁稍微有些不同,它允许所有的请求创建节点,但是,只有序号最小的一个才能获得锁,以此实现成功唯一 |
就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。 分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西,特别是在微服务架构中,几乎可以说是无法避免。 不过有一个知识点我们需要了解,就是假如数据库在提交事务的时候突然断电,那么它是怎么样恢复的呢? 为什么要提到这个知识点呢? 因为分布式系统的核心就是处理各种异常情况,这也是分布式系统复杂的地方,因为分布式的网络环境很复杂,这种“断电”故障要比单机多很多,所以我们在做分布式系统的时候,最先考虑的就是这种情况。这些异常可能有 机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的TCP、存储数据丢失、其他异常等等... 我们接着说本地事务数据库断电的这种情况,它是怎么保证数据一致性的呢?我们使用SQL Server来举例,我们知道我们在使用 SQL Server 数据库是由两个文件组成的,一个数据库文件和一个日志文件,通常情况下,日志文件都要比数据库文件大很多。数据库进行任何写入操作的时候都是要先写日志的,同样的道理,我们在执行事务的时候数据库首先会记录下这个事务的redo操作日志,然后才开始真正操作数据库,在操作之前首先会把日志文件写入磁盘,那么当突然断电的时候,即使操作没有完成,在重新启动数据库时候,数据库会根据当前数据的情况进行undo回滚或者是redo前滚,这样就保证了数据的强一致性。 CAP定理CAP定理是由加州大学伯克利分校Eric Brewer教授提出来的,他指出WEB服务无法同时满足一下3个属性:
具体地讲在分布式系统中,在任何数据库设计中,一个Web应用至多只能同时支持上面的两个属性。显然,任何横向扩展策略都要依赖于数据分区。因此,设计人员必须在一致性与可用性之间做出选择。 https://blog.youkuaiyun.com/mine_song/article/details/64118963 https://www.zhihu.com/question/64921387/answer/225784480 |
zookeeper实现分布式锁: https://segmentfault.com/a/1190000010895869 https://blog.youkuaiyun.com/sunfeizhi/article/details/51926396 |
23、b树和b+树有什么区别?https://www.cs.usfca.edu/~galles/visualization/Algorithms.html(各种数据结构的可视化)
| 答:B树和B+树。B树的创建,是为了优化二叉树深度过大,不利于磁盘检索的问题。所以B树一般都是又矮又胖,B+树是对B树的优化,它中间节点不存数据,只存索引,所以,每个磁盘能容纳更多的数据,降低检索消耗,mysql索性应该就是采用的B+树做索引的 |
| https://www.cnblogs.com/George1994/p/7008732.html |
| https://www.cnblogs.com/ivictor/p/5849061.html |
24、对一个链表进行排序?
25、你看过哪些开源技术的源码?
| spring ,redis ,zookeeper, |
26、dubbo 和spring cloud 的区别?
| 一直在用dubbo,spring cloud从去年开始业界逐渐有很多公司在用,说下我的看法: 从框架目标来讲dubbo只是一个分布式服务调用的框架,而spring cloud所着眼的问题域是整个微服务体系,包含了分布式配置、服务注册与发现、服务路由、服务调用、服务跟踪、断路保护、消息总线、批量任务等等。dubbo本身只提供了服务治理的功能,而其他组件是第三方开源实现,而不像spring提供了一站式集成。 活跃度上dubbo已经很久没人理了,spring cloud一直活跃,如果用dubbo的话建议fork社区更活跃功能也更完善的dubbox。 文档质量上dubbo官网这块说明的还是挺详细的,spring cloud中国社区还在努力中。 | |||
37、dubbo和cloud区别怎么表述
| |||
27、谈谈你是如何解决高并发的?
| https://blog.youkuaiyun.com/qq_35522169/article/details/52572611 |
一个网站 High Scalability: All Time Favorites |
| https://www.zhihu.com/question/40609661 |
28、还有一个我万年也答不好问题,spring容器的启动过程?
| https://blog.youkuaiyun.com/caomiao2006/article/details/51290494 具体搜索总结,必要时看一遍源码 |
29、画一下比较拿手的项目的架构图吧
30、zk的选主过程,脑裂问题如何解决
选举流程简述(只是其中的一个清空,具体分类还很多)目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
|
https://www.cnblogs.com/ASPNET2008/p/6421571.html https://blog.youkuaiyun.com/qinghua9/article/details/22858033(源码分析) https://blog.youkuaiyun.com/liuyuehu/article/details/52136945(算法介绍,整体架构) |
| 脑裂及解决:https://blog.youkuaiyun.com/u010185262/article/details/49910301 |
31、说一下 jdk 6,7 intern方法的变化吧
| https://blog.youkuaiyun.com/bigtree_3721/article/details/74907670 |
32、current包下的所有类介绍一下
| https://blog.youkuaiyun.com/lh87522/article/details/45973373 |
33、thread在jvm里有几种状态
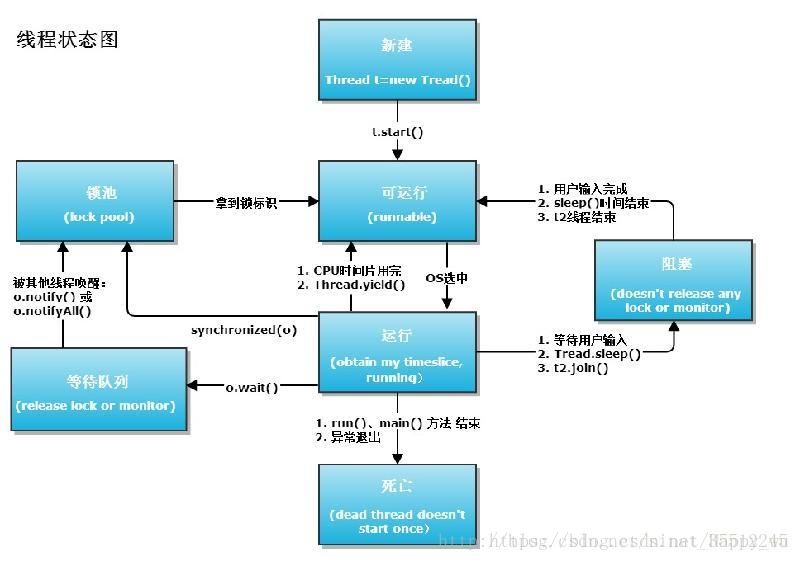 |
(一). 等待阻塞:运行(running)的线程执行o.wait()方法,JVM会把该线程放入等待队列(waitting queue)中。 (二). 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。 (三). 其他阻塞:运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
|
34、jit的机制是什么
| JIT是just in time,即时编译技术:https://blog.youkuaiyun.com/sunmenggmail/article/details/38655491 |
35、Markswap是以什么方式整理的
| MarkSwap这个。标记清除算法,是其他回收算法的基础,都是根据它的优缺点改进得来,具体分为两个阶段,一个是标记阶段,停止所有活动,进行标记,因为慢,所以有了多线程版本和并行版本。二是清除阶段,把不存活对象回收,会产生大量空间碎片,所以有了复制版本和整理版本 |
38、垃圾回收,发展历程中,都有哪些进步?(按我以前的回答即可)
| GC发展这个。第一是对标记方法的改进,因为引用计数器不能辨别循环引用但又不被其他对象引用的情况,所以有了root遍历标记法。第二,由于对象的生命周期特点不同,于是有了分代回收机制。 |
49、rpc时,比如A调用B,但此时B在垃圾回收时,若果A的timeout时间小于B的gc时间会造成rpc失败,在A rpc超时时间不变的情况下,怎么调优jvm参数
| GC时间比超时时间都长?那这GC也太长了点吧,我觉得你是不是想问接口的响应时间由于GC变得过长,导致了请求超时吧,正好我之前遇到过这样的情况。 |
| 就个人经验,遇到接口响应时间慢,一般要从两个方向入手,一个是代码方面,有没有可以优化的地方,比如不相关的流程并行话,不需要实时的流程异步化。二是GC时间。先看gc策略,串行的效率高,但停顿时间长,一般要比并行的慢,关注吞吐量的会比关注响应的有可能花更多的GC时间,所以,像这种要求响应的服务端,我一般会采用parnew cms的组合,然后看gc发生的次数,要分代去看, |
50、讲一讲AQS(同问题19)
| AQS。这个队列同步器,几乎是整个并发组件的核心模块,如果把并发相关的看成是一个分层的结构,那么,最底层的是volitile,cas,中间就是AQS和无阻塞数据结构,再往上就是具体的应用,各种并发器。AQS通过对内部的一个volitile的状态属性,获取,释放,配合队列,从而达到并发下的多线程资源抢占,大概是这样 |
51、请问如何保证缓存地数据库是一致的!能列举具体的解决策略吗?
| 缓存和数据库的数据一致性。个人经验,不要去改了某个数据之后同时修改数据库和缓存,这样的方式产生不一致的几率要大些,我的解决办法是,比如修改商品库存,要先去修改数据库,带修改成功之后,再用数据库中的最新值异步发个mq。缓存那边实时监听mq,增量更新。同时,要有定时全量更新的缓存机制,消除一些不可预知的情况,离线跑脚本,定时任务都可以。 |
52、集群的redis 分布式锁,怎么保证高可用
| redis分布式锁高可用。这个我觉得要从两个角度去考虑吧。一个是锁实现本身,一个是redis载体。对于锁,要考虑锁的互斥,死锁释放,等这些问题,相对而言容易解决,无非是利用redis各种命令,原子性的获取锁,设置过期阈值等。二是在redis节点挂掉,产生故障的时候也要保证锁的可用性。这个感觉就比较麻烦了。也要看redis的部署情况,是主从复制,还是采用一致性hash方式来部署的 |
| 不管是哪种方法,都有可能会在数据写入内存但没有来得及持久化的时候挂掉,要想解决这种问题,我感觉就得引入更多的资源,比如多主,多活,双写什么的。但都需要付出更多的资源,还要开发相应的组件,势必造成锁获取的耗时增加等不可预知的情况,是不是值得有待商榷,而且,个人认为,用redis来做分布式锁的业务,也不应该是那种特别谨慎的业务,如果是提单,支付等核心业务,我宁愿慢一点也是不会用redis来上锁的 |
53、怎么保证redis事务
54、cpu过高、内存过高怎么排查
55、从源码层面说下Spring怎么实现aop的(同问题2)
56、Java8 hashmap相对于7有些什么变化,为什么
57、有没有遇到过close wait过高问题,遇到过又是怎么解决的
58、分布式一致性是啥?原理?几种实现的优缺点(同问题21,22)
59、cpu load过高怎么解决
60、leetcode刷完再过来

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









