



 本文解析了一道关于字符串中字母最后一次出现位置的贪心算法题目,通过实例说明了如何利用last数组和end变量更新策略来解决。关键在于理解'更新最远边界'的概念,以及如何根据字母表顺序和最后一次出现位置截取临时片段。
本文解析了一道关于字符串中字母最后一次出现位置的贪心算法题目,通过实例说明了如何利用last数组和end变量更新策略来解决。关键在于理解'更新最远边界'的概念,以及如何根据字母表顺序和最后一次出现位置截取临时片段。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
刷题菜鸡是我本人没错了。。
提示:以下是本篇文章正文内容,所截图片均取自力扣
零、题目

一、整体思路
贪心有什么思路呢。。就本题来说,乍一看我都是懵的,憋了半天想不出思路后去看官方解法:
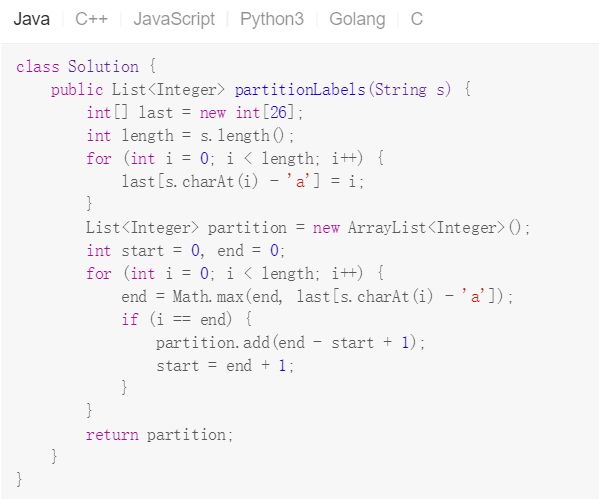
整体思路是,将字符串s中每个字母最后一次出现的下标放进last数组中,并对字符串中字母进行循环,然后。。我就看不懂了=_=b
start和end截取了循环所使用的临时片段,last数组按照字母表顺序排位。
但我始终想不通为什么截取片段的条件是 i == end,即为什么当前字母下标(i),与,当前临时片段末尾下标(end),相等时,就将该临时片段截取。直到我看到了更直白地图文解释(感谢“代码随想录”大佬!):
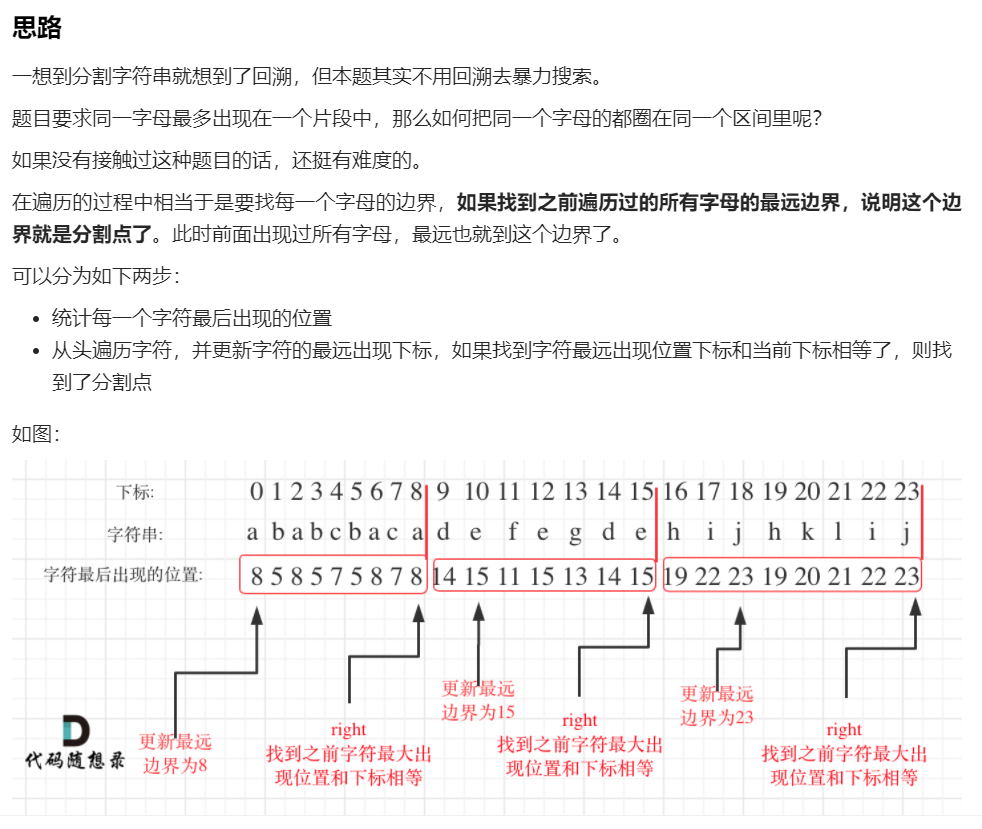
啊~原来如此,果然还是视觉冲击更带劲儿一些。“更新最远边界”,即为解题核心,每循环一次,进行临时片段最远边界end的更新:
end = Math.max(end, last[s.charAt(i) - 'a']);
对于字符串s中每一个字母c:
①如果c最后一次出现在字符串s中的下标,比,当前临时片段最远边界end,大,那么就更新end为该下标。
②当前c的下标与end相等时,即,当前c即为字母c的最后一次出现,就截取该临时片段,并将临时片段的start设为end+1(最后一次出现字母c的下一个字母),往复循环即可。
除了第一次循环,end是临时片段中某字母的在s中最后一次出现的下标。其实这就是最后一次出现晚的字母包含最后一次出现早的字母。
总结
仅供自己参考,十分欢迎指出错误和逻辑不通顺~
贪心嘛,总是贯穿于不经意间的日常解题。
所有解法都好妙,妙到我什么都想不到~

















 376
376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









