




 本文介绍了使用 Pandas 进行高效数据处理的方法,包括行列之间的转换、数据重塑、索引操作及排序等实用技巧。
本文介绍了使用 Pandas 进行高效数据处理的方法,包括行列之间的转换、数据重塑、索引操作及排序等实用技巧。
行列间的转化与拼接
一、将index 和每一列的数值相互转化
df.set_index(["Column"], inplace=True)
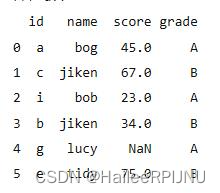
1. 将a列转为index列: set_index
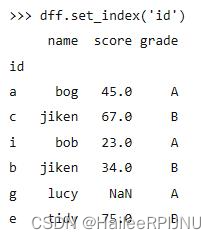
2. 将index 转为列a:
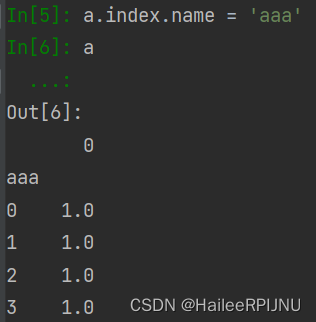
使用之前可以将index重命名:df.index.name = 'aaa'
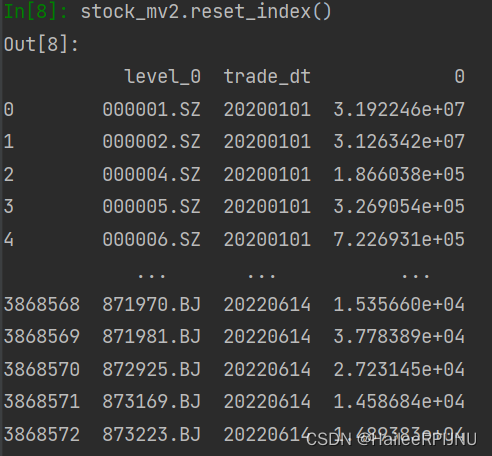
reset_index()
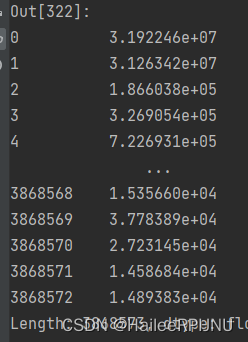
3. 使用drop参数设置去掉原索引
reset_index(drop=True)
2. 重命名
(1)在构造变量的时候进行命名。
dt = pd.DataFrame(t1), index = [```'], columns = [```])
创造DataFrame:
a = pd.DataFrame(np.ones(2), index = ['a1', 'a2'], columns = ['bbb'])
b = pd.Series(np.ones(2), index = ['a1', 'a2'])

(2) 对index的名称进行命名
方法一:
a.index.name = 'aaa'
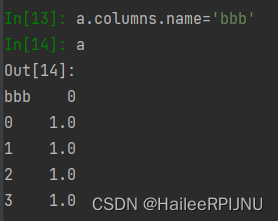
a.columns.name='bbb'
方法二:
a.columns =a.columns.rename("bbb")
a.index =a.index.rename("aaa")
创造DataFrame: a = pd.DataFrame(np.ones(4))
(2)对特定的行列进行命名
方法一:
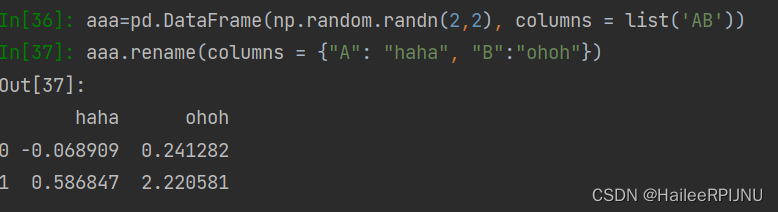
dataframe.rename(columns = {"old1": "new1", "old2":"new2"}, inplace=True)
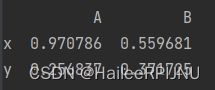
dataframe.rename(index={0: "x", 1: "y"})
dataframe.rename(index={0: "x"})
方法二:
DataFrame.index = [newName]
DataFrame.columns = [newName]
(3) 创造DataFrame, 并直接定义index,columns
pd.DataFrame(history_data.Data,index=history_data.Fields,columns=history_data.Times).T
(4) rename的高级用法:
DataFrame.rename(mapper = None,index = None,columns = None,axis = None,copy = True,inplace = False,level = None )
其中dict可以进行简写
h = dict(zip(aaa.columns, aaa.index))
df = df.rename(columns=h)

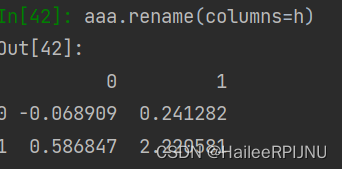
position_stock_pct.rename(lambda x: x + '_pct', axis='columns')
二、双重索引:矩阵的index与columns 重新排列相互转化
stack 与 unstack
columns转为index:
df
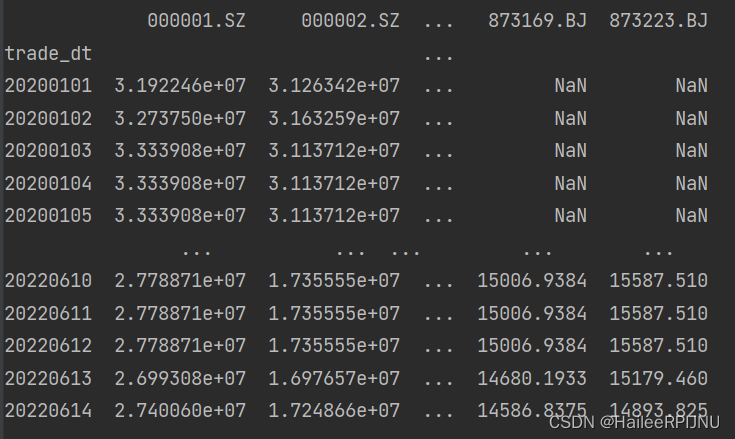
df1 = df.stack()
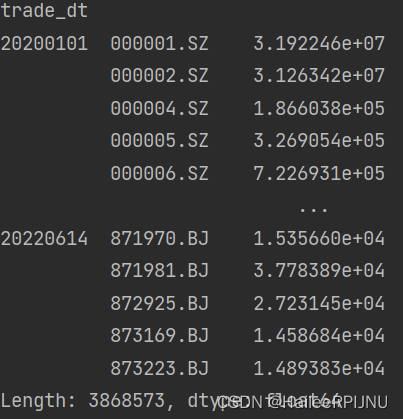
双index 拆分转为columns
df1. unstack()
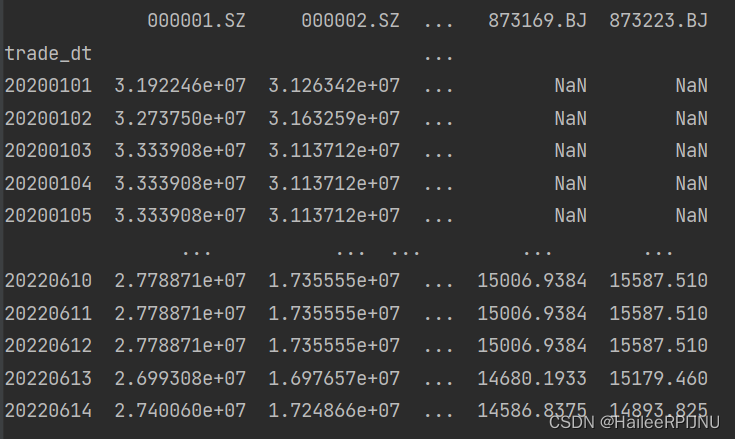
设置双索引,并针对特定索引进行转化
df1 = df.set_index(['trade_dt','s_info_windcode' ])
df2 = df1.unstack('s_info_windcode')
将双轴变为拆分:
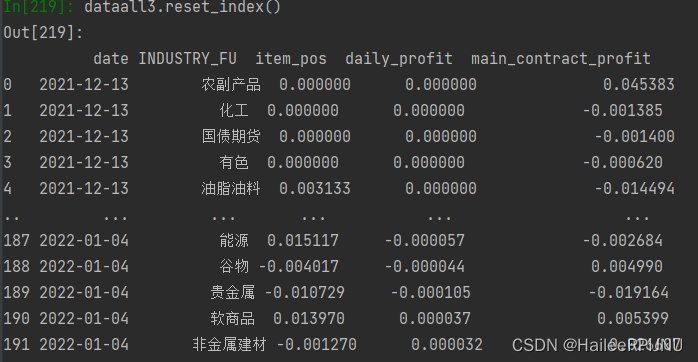
dataall3.reset_index()
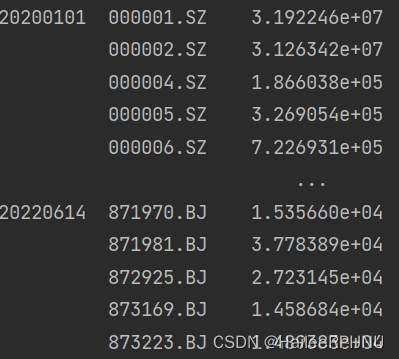
查看第一个索引:ind=rawdata2.index.levels[0]
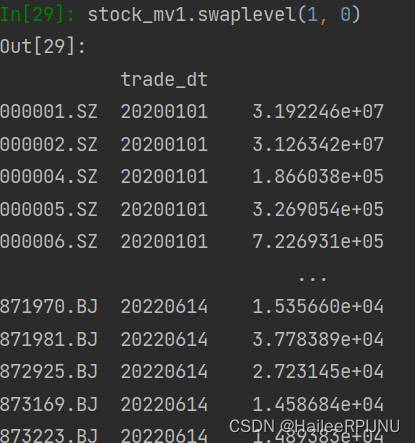
将双轴进行相互转化/填充:swaplevel
stock_mv1.swaplevel(1, 0)
三、重新排列分类:用其中的数据定义index/columns
pivot
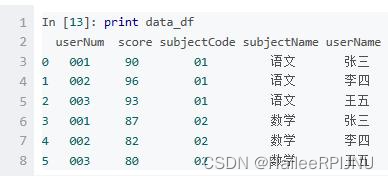
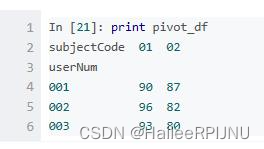
data_df.pivot(index='userNum', columns='subjectCode', values='score')
# index: 可选参数。设置新dataframe的行索引,如果未指明,就用当前已存在的行索引。
# columns:必选参数。用来设置作为新dataframe的列索引。
# values:可选参数。在原dataframe中选中某一列/几列的值,使其在新dataframe的列里显示。如果不指定,则默认将原dataframe中所有的列都显示,这里需要注意:为了将所有的值都显示出来,就会出现多层行索引的情况。
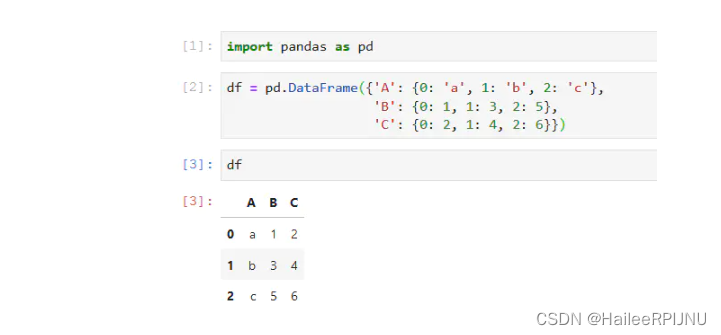
pd.melt
将columns变为一个维度

四、对行、列重新排序
对列进行重新排序:
col_new = ['泛消费', '周期', '地产基建', '大制造', '科技成长', '金融']
indus_pos_collect_ranked = indus_pos_collect.loc[:, col_new]
以行重新排序:
indus_pos_new = indus_pos_new.sort_index()
五、改变类别标签
df['grade'] = df['grade'].cat.set_categories(['very bad', 'bad', 'medium', 'good', 'very good'])
df['grade'].cat.set_categories(['very bad', 'bad', 'medium', 'good', 'very good'], inplace=True)
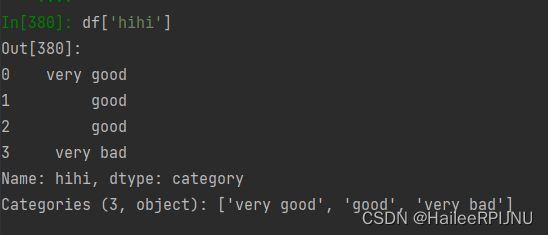
df = pd.DataFrame({"ohoh":[1,2,3, 4], "haha":['a', 'b', 'b', 'c']})
#将列转化为category类型
df["hihi"] = df["haha"].astype("category")
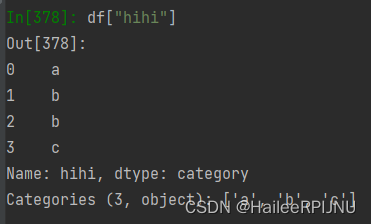
df['hihi'].cat.categories = ["very good", "good", "very bad"]
六、将index名称自动转为序号
time_chosen.reset_index(drop=True)
已完成


















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









