




 在RedHat7.2和CM/CDH 5.15.0环境下,Hive-On-Spark查询遇到失败,日志显示'Failed to create spark client'。原因可能包括:Hive超时设置过短、Yarn资源不足或队列拥堵。解决方案包括调整Hive超时参数和检查Yarn队列状态。
在RedHat7.2和CM/CDH 5.15.0环境下,Hive-On-Spark查询遇到失败,日志显示'Failed to create spark client'。原因可能包括:Hive超时设置过短、Yarn资源不足或队列拥堵。解决方案包括调整Hive超时参数和检查Yarn队列状态。
1 问题现象
- 测试环境
1.RedHat7.2
2.CM和CDH版本为5.15.0
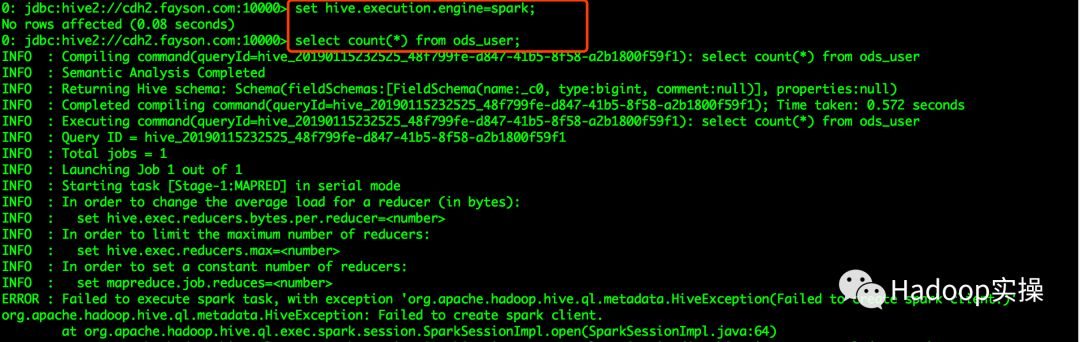
在集群中进行Hive-On-Spark查询失败,并在HiveServer2日志中显示如下错误:
ERROR : Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create spark client.)'
org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create spark client.
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:64)
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:114)
....
Caused by: java.lang.RuntimeException: java.util.concurrent.ExecutionException: java.util.concurrent.TimeoutException: Timed out waiting for client connection.
at com.google.common.base.Throwables.propagate(Throwables.java:156)
at org.apache.hive.spark.client.SparkClientImpl.<init>(SparkClientImpl.java:124)
2 原因分析
当Hive服务将Spark应用程序提交到集群时,在Hive Client会记录提交应用程序的等待时间,通过等待时长确定Spark作业是否在集群上运行。如果应用程序未在指定的等待时间范围内运行,则Hive服务会认为Spark应用程序已失败。
当Spark ApplicationMaster被分配了Yarn Container并且正在节点上运行时,则Hive认为Spark应用程序是成功运行的。如果Spark作业被提交到Yarn的排队队列并且正在排队,在Yarn为Spark作业分配到资源并且正在运行前(超过Hive的等待时长)则Hive服务可能会终止该查询并提示“Failed to create spark client”。
3 问题说明
1.可以通过调整Hive On Spark超时值,通过设置更长的超时时间,允许Hive等待更长的时间以确保在集群上运行Spark作业,在执行查询前设置如下参数
set hive.spark.client.server.connect.timeout=300000;
该参数单位为毫秒,默认值为90秒。要验证配置是否生效,可以通过查看HiveServer2日志中查询失败异常日志确定:

2.检查Yarn队列状态,以确保集群有足够的资源来运行Spark作业。在Fayson的测试环境通过多个并发将集群的资源完全占有导致Hive On Spark作业提交到集群后一直获取不到资源。
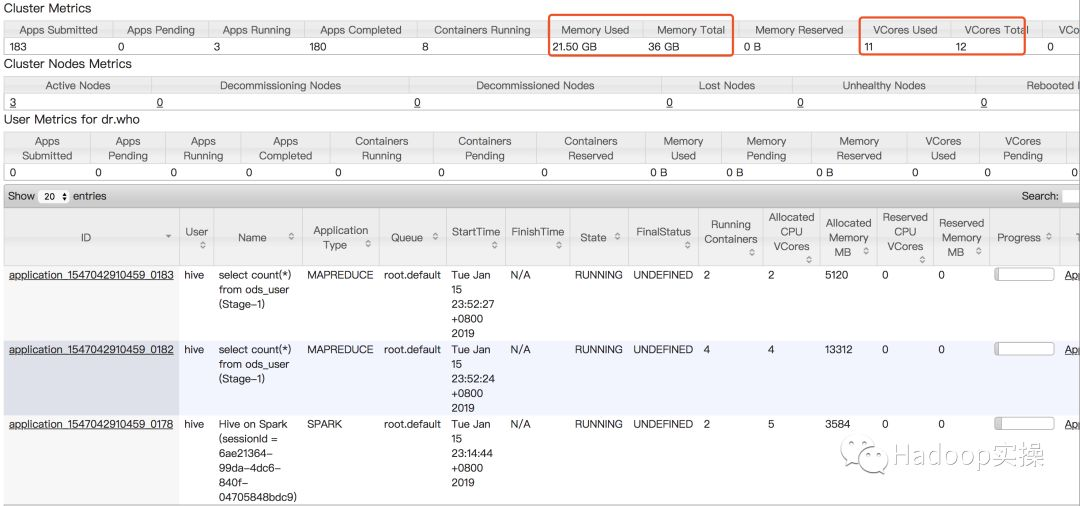
集群中没有足够的资源为Hive提交的Spark作业分配资源,同样也有可能是提交到Yarn队列作业过多导致无法分配到资源启动作业。
4 总结
1.当集群资源使用率过高时可能会导致Hive On Spark查询失败,因为Yarn无法启动Spark Client。
2.Hive在将Spark作业提交到集群是,默认会记录提交作业的等待时间,如果超过设置的hive.spark.client.server.connect.timeout的等待时间则会认为Spark作业启动失败,从而终止该查询。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。


















 3577
3577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









