



1、前言
在当今信息爆炸的时代,知识的获取、整理和应用显得尤为重要。随着个人职业发展和学习需求的不断提升,搭建一个个人知识库已成为提升竞争力的关键一环。个人知识库不仅是一个信息的存储库,更是一个思维的工具箱,它能够帮助我们系统地整理各类知识,形成自己的知识体系,并在需要时快速准确地找到所需信息。
通过搭建个人知识库,我们可以更好地管理自己的学习资源,避免信息过载和遗忘的困扰。同时,个人知识库还能促进知识的深化和拓展,让我们在学习的过程中不断发现新的知识点和关联,形成更加完整的认知结构。此外,个人知识库还具有很高的实用性,它可以成为我们工作和学习中的得力助手,帮助我们在面对复杂问题时能够迅速找到解决方案,提高工作效率和学习成果。
因此,搭建个人知识库对于个人成长和职业发展具有重要意义。通过不断地积累和整理知识,我们可以不断提升自己的综合素质和能力水平,为未来的挑战和机遇做好充分的准备。
2、reference介绍
今天要介绍的内容 reference,就是来帮我们解决这个问题。该项目是一个开源的速查表项目,旨在为开发人员提供便捷的知识查询和参考工具。该项目包含了各种技术领域的常用知识点、代码片段和最佳实践,旨在帮助开发人员快速回顾和查找关键信息,提高开发效率。
项目地址:
https://github.com/jaywcjlove/reference
项目特点:
-
内容丰富:该项目涵盖了前端开发、后端开发、数据库、算法与数据结构等多个领域的知识点,几乎覆盖了开发人员在日常工作中可能遇到的各种问题。
-
易于查询:项目中的知识点按照主题和关键词进行了分类和索引,方便用户快速定位所需信息。
-
简洁明了:每个知识点都用简洁明了的语言进行描述,避免了冗长和复杂的解释,使用户能够迅速理解并应用。
-
更新及时:随着技术的不断发展,该项目会定期更新内容,确保所提供的知识点和代码片段始终与最新技术保持同步。
3、安装、使用
我们可以通过docker来安装:
docker run --name reference -itd -p 9667:3000 wcjiang/reference:latest
接着,我们在浏览器访问 http://ip:9667即可查询你需要的各种命令了。如下:
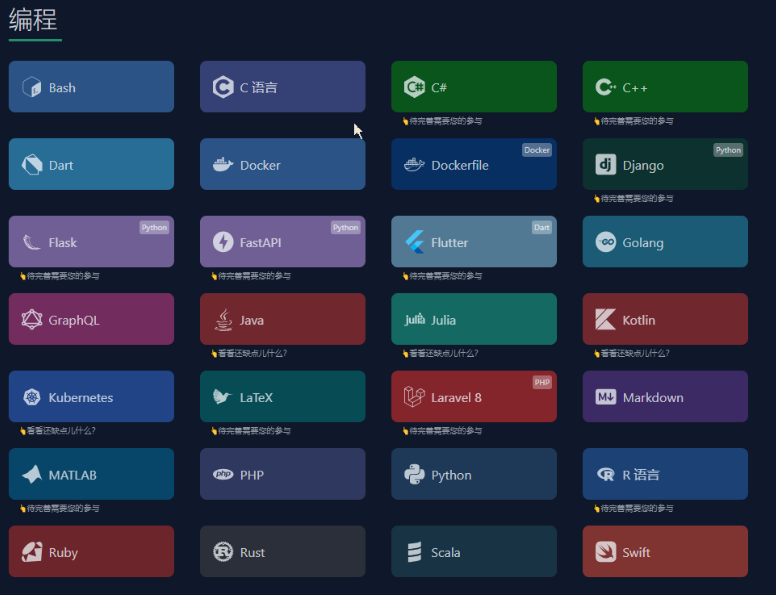
速查表地址如下:
https://wangchujiang.com/reference/
以django查找为例:
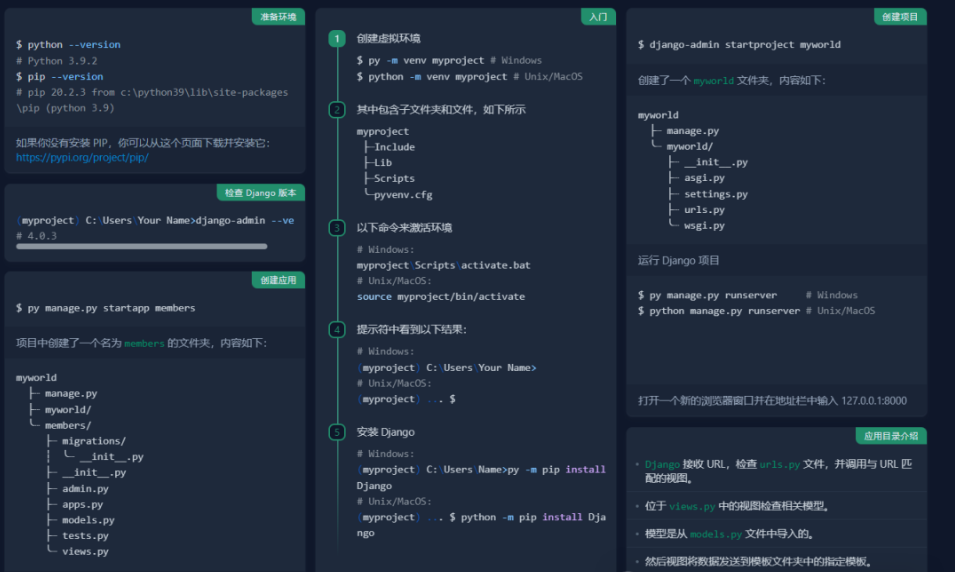
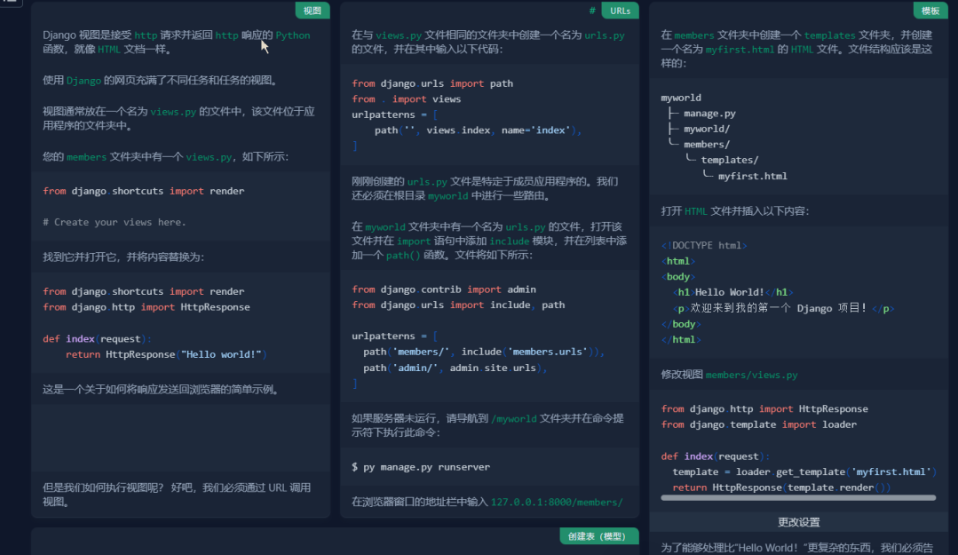
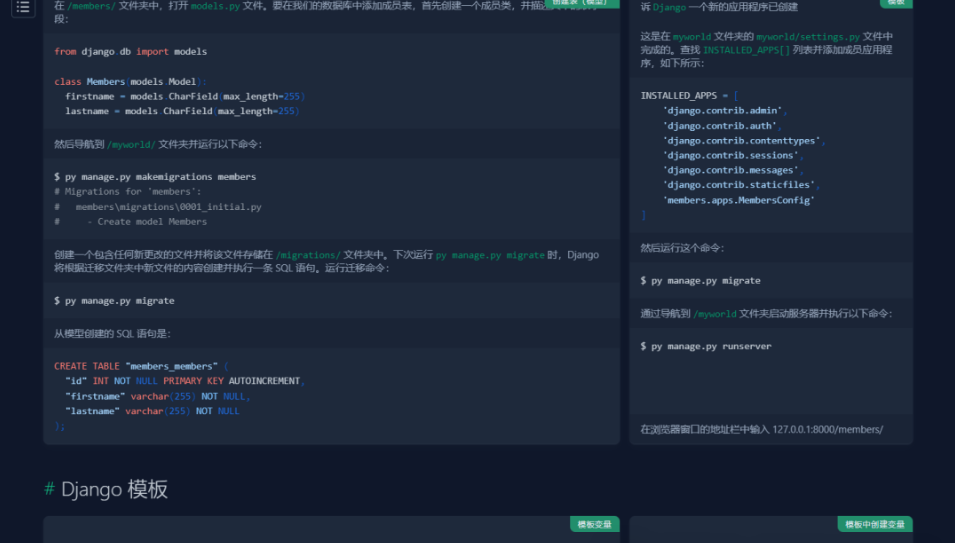
总之,https://github.com/jaywcjlove/reference 项目是一个方便实用的速查表工具,适用于广大开发人员在日常工作中快速查找和回顾知识点。通过浏览文档、搜索关键词和复制代码片段等操作,你可以轻松利用该项目提高开发效率。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。




















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









