



 本文详细介绍了哈里斯鹰优化算法(HHO),一种受哈里斯鹰捕猎策略启发的优化算法。HHO分为全局搜索、全局搜索向局部开发转变及开发三个阶段,模拟了哈里斯鹰的寻找、跟踪和捕猎过程。在不同阶段,算法运用不同的策略进行位置更新,以求找到最佳解决方案。
本文详细介绍了哈里斯鹰优化算法(HHO),一种受哈里斯鹰捕猎策略启发的优化算法。HHO分为全局搜索、全局搜索向局部开发转变及开发三个阶段,模拟了哈里斯鹰的寻找、跟踪和捕猎过程。在不同阶段,算法运用不同的策略进行位置更新,以求找到最佳解决方案。
哈里斯鹰是一种著名的猛禽,其独特之处在于它与生活在同一稳定群体中的其他家庭成员一起进行独特的合作觅食活动,而其他猛禽通常独自攻击,发现和捕获猎物。哈里斯鹰捕捉猎物的主要策略是“突袭”,也被称为“七杀”策略。在这种聪明的策略中,几只鹰试图从不同的方向进行合作攻击,同时聚集在被发现的正在掩体外逃跑的兔子身上。攻击可以在几秒钟内迅速完成,捕获受惊的猎物,但偶尔,考虑到猎物的逃跑能力和行为,七杀可能包括几分钟内在猎物附近多次短距离快速俯冲。哈里斯鹰会根据环境的动态性质和猎物的逃跑模式表现出各种各样的追逐风格。
2019 年 Ali Asghar Heidari 等人提出哈里斯鹰优化算法(Harris Hawk Optimization, HHO),分为三个阶段,搜索阶段,搜索向开发转变的阶段,开发阶段。
1.全局搜索阶段
在这一部分中,提出了HHO的探索机制。如果我们考虑哈里斯鹰的本性,它们可以通过强有力的眼睛追踪和发现猎物,但偶尔猎物不容易被发现。因此,鹰等待,观察和监视沙漠地点,以发现猎物可能需要几个小时。
在HHO中,哈里斯鹰是候选解,每一步的最佳候选解作为目标猎物或近似最优解。
在HHO中,哈里斯鹰随机地栖息在一些地点,并根据两种策略等待发现猎物。
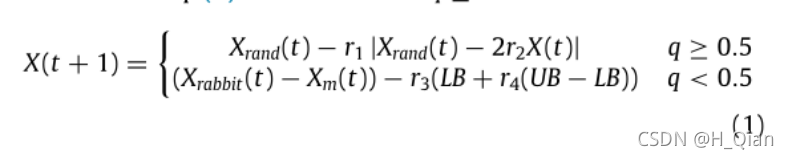
X (t)是鹰群的当前位置,X (t + 1)是鹰群在下一次迭代中的位置,t为迭代次数,Xrabbit (t)是兔子的当前位置(适应度值最好,即值最小), Xrand(t)是当前种群中随机选取的个体的位置,Xm(t)是当前种群中鹰的平均位置(公式2),r1, r2, r3、r4、和q是随机数字(0,1)内,在每一次迭代更新,UB LB显示搜索空间变量的上下界。
式(1)中,当q≥0.5时,此时还没有任何一只鹰发现猎物的位置,因此随机选择种群中的个体,q < 0.5时,哈里斯鹰发现目标,因此根据其家庭成员的位置和兔子的位置盘旋,并更新位置。

鹰的平均位置可以通过Eq.(2)得到:
其中Xi(t)表示迭代t中第i个鹰的位置,N表示鹰的总数。
2.全局搜索向局部开发阶段转变
HHO算法可以根据猎物的逃逸能量,实现从探索到利用的转换,进而改变不同的利用行为。

式中,E为猎物的逃逸能量,T为最大迭代次数,E0为猎物能量的初始值。
在HHO中,E0在每次迭代时在区间(−1,1)内随机变化。当E0值从0降低到−1时,兔子处于“身体越加疲乏”;当E0值从0增加到1时,兔子处于“恢复能量阶段”。动态逃逸能量E在迭代过程中有减小的趋势。当逃逸能量|E|≥1时,哈里斯鹰在不同区域搜索兔子位置,因此,HHO执行全局搜索阶段,当|E| <1时,哈里斯鹰算法对相邻的解进行局部搜索,对应局部开发阶段。总之,当|E|≥1时进行全局搜索,当|E| <1时进行后期开采(局部)。图4也显示了E的随时间变化的行为。
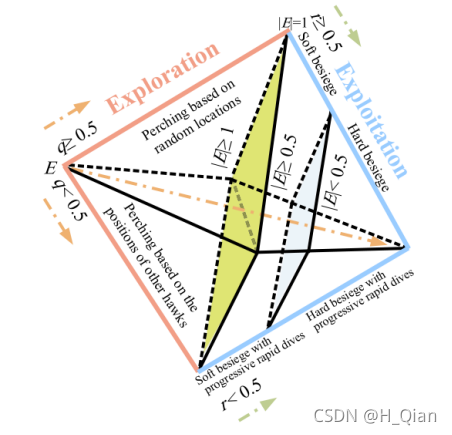
图三 HHO的不同阶段
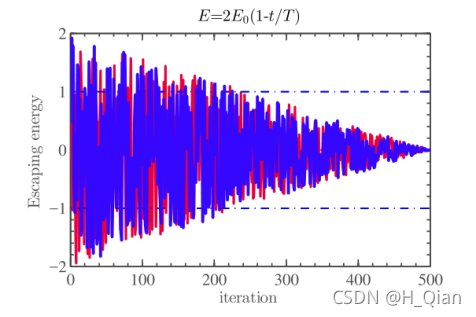
图四 在两次运行和500次迭代条件下E的迭代曲线。
3.开发阶段
哈里斯鹰通过攻击在前一阶段发现的目标猎物来执行突袭,根据猎物的逃跑行为和哈里斯鹰的追逐策略,在HHO中提出了四种可能的策略来模拟攻击阶段。
设r为兔子逃脱的概率(也可看为鹰能否包围兔子的概率),在突袭前兔子成功逃脱或鹰未能成功包围(r < 0.5),兔子失败逃脱或鹰已成功包围(r≥0.5)。无论猎物做什么,鹰都会根据猎物所保留的能量选择从不同的方向实施硬包围或软包围来捕获猎物。在现实生活中,鹰会越来越接近目标,通过突袭来增加合作杀死兔子的机会。几分钟后,逃跑的猎物会失去越来越多的能量;然后,鹰加强包围过程,毫不费力地抓住筋疲力尽的猎物。为了对该策略进行建模,并使HHO能够在软和硬包围过程之间切换,我们使用了逃逸能量E。因此,当|E|≥0.5时,发生软包围;当|E| <0.5时,发生硬包围。
3.1软包围
当r≥0.5,1>|E|≥0.5时,兔子未成功突破包围,并仍然有足够的能量逃脱,它将尝试一些误导性移动来迷惑捕猎者,此时哈里斯鹰若是霸王硬上弓则势必得不偿失。因此,哈里斯鹰在兔兔身边盘旋,消耗其体力使其疲惫,进而突袭:在这些尝试中,哈里斯鹰轻轻地包围它,让兔子筋疲力尽,然后进行突然袭击。使用公式(4)、(5)更新当前位置
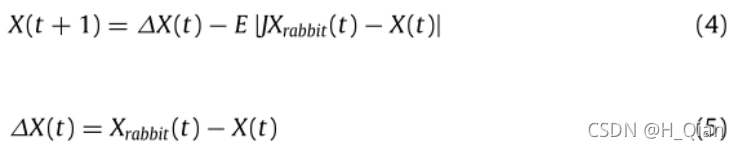
其中,∆X(t)为迭代t中兔子的位置向量与鹰当前位置的差值,r5为(0,1)中的一个随机数,
J = 2(1−r5)为兔子在整个转逃过程中的随机跳跃强度。J值(0-2间)在每次迭代中随机变化,以模拟兔子运动的本质及其移动强度。
3.2硬包围
当r≥0.5,|E| <0.5时,猎物未成功突破包围,且筋疲力尽,逃逸能量低。此时,哈里斯鹰硬包围目标猎物,并最终实施突袭。在这种情况下,使用公式(6)更新当前位置:
![]()
该攻击模式的模拟图:
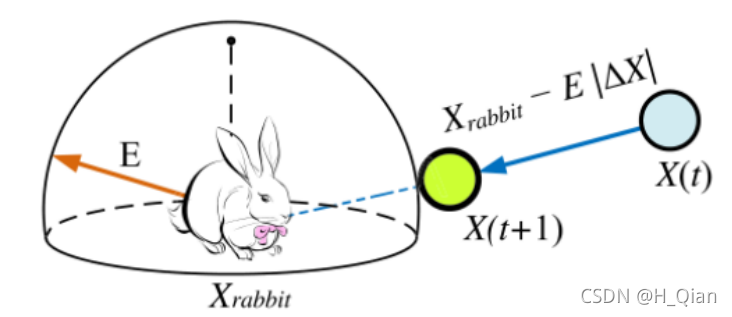
图5 硬包围
3.3.3 渐进式快速俯冲的软包围
r < 0.5时,当1>|E|≥0.5,兔子成功突破鹰群包围,且有足够的能量成功逃脱,针对这种情况,哈里斯鹰需要在进攻前形成一个渐进式快速俯冲的软围攻方式。
为了对猎物的逃逸模式和前期全局搜索时的跳蛙运动进行数学建模,HHO算法采用了levy flight (LF)概念。该算法模拟了猎物(特别是兔子)在逃逸阶段的真实锯齿形欺骗动作和老鹰在逃逸猎物周围的不规则、突然和快速俯冲。事实上,鹰会围绕着兔子进行几次团队快速俯冲,并试图根据兔子的欺骗性动作逐步纠正自己的位置和方向。
为了进行软围攻,我们假设鹰可以根据公式(7)来评估(决定)自己的下一步行动:
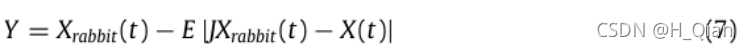
然后,他们将得到的F(Y)与当前位置适应度值进行比较,以检测它是否是一次良好的突袭。
如果是一次不成功的突袭(当它们看到猎物在做更多的欺骗动作时),它们也会在接近兔子时开始不规则、突然和快速地俯冲。我们假设它们将进行基于LF的模式俯冲,使用以下策略:
![]()
式中,D为问题的维数,S为大小为1 × D的随机向量,LF为levy flight函数,计算公式为公式 (9):
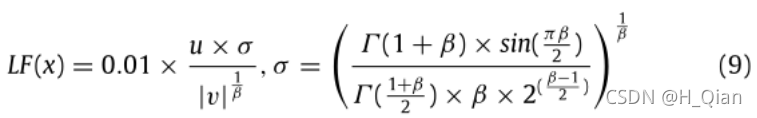
其中u, v是(0,1)中的随机值,β是设置为1.5的默认常量。
因此,软围攻阶段哈里斯鹰位置更新的最终决策可由式(10)执行:
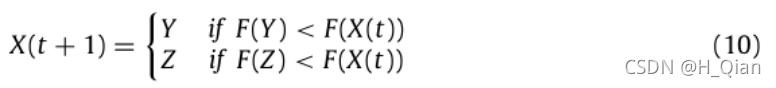
其中Y和Z是通过公式获得的。(7)、(8)。F()为适应度函数。
图6展示了这一步骤对一只鹰的简单说明。在每一步中,只有较好的位置Y或Z会被选为下一个位置。此策略适用于所有搜索代理。
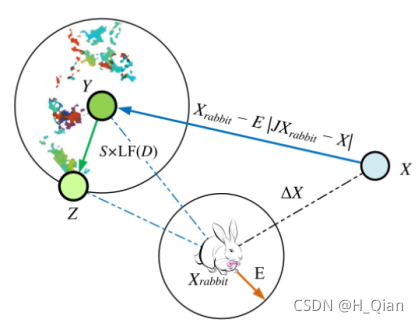
图6 渐进式快速俯冲的软包围总体矢量示例图
3.3.4渐进式快速俯冲的硬包围
r <0.5时,当|E| <0.5,兔子成功逃出包围圈,但没有足够的能量逃跑,鹰群在突袭捕获并杀死猎物之前,形成了一个坚硬的围攻。在被捕食方这一步的情况与渐进式俯冲软围攻时相似,但这一次,鹰试图减少它们与逃跑的猎物的平均位置的距离。因此,在硬围困条件下执行以下规则:
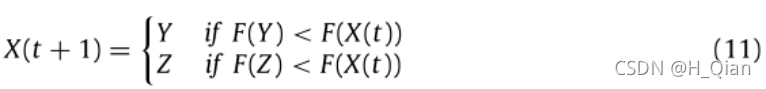
其中Y和Z是使用公式(12)和(13)中的新规则获得的。 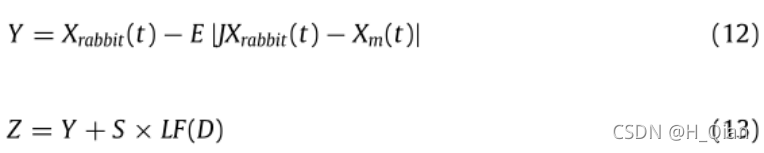
其中Xm(t)鹰的平均位置是通过Eq.(2)得到的。
这一步的一个简单示例如图7所示。请注意,彩色点是一次试验中基于LF的模式的位置足迹,只有Y或Z将是新迭代的下一个位置。
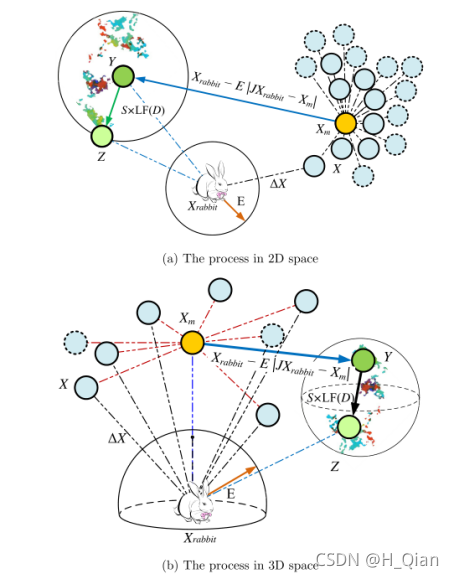
图7 在2D和3D空间中,连续快速俯冲的硬包围情况下的总体矢量示例。
综上所述,
步骤 1:种群初始化。根据搜索空间每一维的上界和下界,初始化每个个体。
步骤 2:计算初始适应度。将适应度最优的个体位置设为当前猎物位置。
步骤 3:位置更新。先通过更新猎物逃逸能量,然后根据逃逸能量和生成的随机数执行搜索或开发行为中对应的位置更新策略。
步骤 4:计算适应度。计算位置更新后的个体适应度,并与猎物适应度值进行比较,若位置更新后的个体适应度值优于猎物,则以适应度值更优的个体位置作为新的猎物位置。
重复步骤 3 和步骤 4,当算法迭代次数达到最大迭代次数时。输出当前猎物位置作为目标的估计位置。

















 3473
3473


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








