




在 AI 辅助编程(AI Coding)的浪潮中,大多数 Copilot 类产品都能出色地完成“补全一行代码”或“生成一个脚本”的任务。然而,当面临真实的软件工程挑战——比如在一个包含数千个文件、核心逻辑长达万行的大型遗留项目中修复一个隐蔽的 Bug 时,许多 Agent 往往会陷入“上下文溢出”或“幻觉修改”的泥潭。这就好比让一个初级实习生在没有导师指导的情况下,直接去修改核心架构,结果往往是修复了一个 Bug,却引入了三个新 Bug。
通过深入分析字节跳动 Trae Agent 的开源代码(核心逻辑位于 trae_agent/tools/),我们发现它并未盲目依赖大模型的生成能力,而是通过一套确定性的工具链设计,解决了长文件编辑与精准代码检索这两大难题。Trae Agent 不仅仅是一个聊天机器人,它更像是一个配备了精密手术刀和高精度扫描仪的资深工程师,能够在不破坏系统整体稳定性的前提下,精准地进行修复和重构。
本文将从源码层面,为您解密 Trae Agent 的底层工程哲学,探讨它是如何通过一系列精巧的工具设计,将大模型的不确定性关进“笼子”里,从而实现工业级的代码生成与修改。
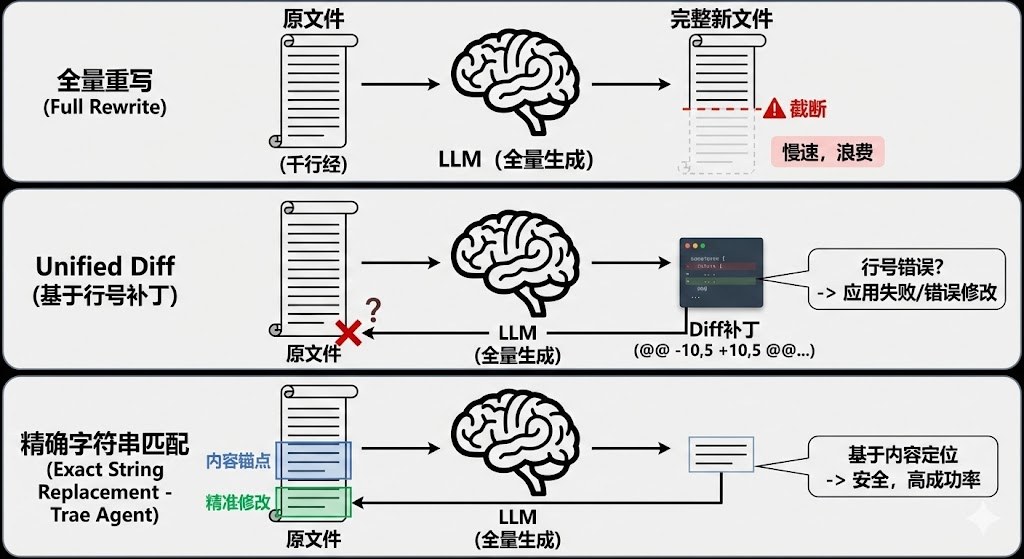
一、 精准操刀:告别 Unified Diff 的“微创手术”
在传统的 AI 编程中,让 LLM 修改文件通常有两种做法,但它们在处理长文件时都存在明显的局限性:
-
全量重写:输出整个新文件。
-
原理:LLM 读取整个文件内容,修改后输出完整的新文件。
-
缺点:这在小脚本中可行,但对于几千行的大文件来说是灾难性的。首先,它极其浪费 Token,推高了成本。其次,LLM 的输出长度有限制,长文件很容易在中间被截断,导致文件损坏。最后,全量生成速度慢,用户体验极差。
-
-
Unified Diff:生成
@@ -10,5 +10,5 @@格式的补丁。-
原理:LLM 尝试像 git diff 那样,只输出修改前后的差异块。
-
缺点:这对 LLM 的数学计算能力提出了极高要求。LLM 很难精准算对行号(Line Number),尤其是在文件经历了多次修改后。一旦生成的补丁中行号偏移(比如 LLM 认为是第 10 行,实际是第 12 行),补丁应用就会失败,或者更糟糕的是,错误地修改了无关的代码。
-
Trae Agent 在 edit_tool.py 中通过 str_replace_based_edit_tool 实现了一种**基于精确字符串匹配(Exact String Replacement)**的第三种路径。这种方法摒弃了脆弱的行号依赖,转而使用“内容锚点”来定位修改位置,大大提高了修改的成功率和安全性。
1. 核心机制:唯一性匹配(Verbatim Match)
Trae Agent 不依赖行号,而是依赖“内容”。它要求 LLM 必须精准复述想要修改的旧代码片段(Old String)。这不仅是一个定位机制,更是一个强制性的“理解验证”过程。
源码逻辑解析
在 trae_agent/tools/edit_tool.py 中,str_replace 函数执行了严格的校验。以下是对其核心逻辑的深度拆解:
# 伪代码逻辑演示
def str_replace(self, path, old_str, new_str):
# 1. 读取目标文件内容
content = read_file(path)
# 2. 核心风控:检查 old_str 在全文中出现的次数
# 这是一个关键的安全阀,防止 LLM "闭眼" 修改
count = content.count(old_str)
# 情况 A: 幻觉检测
if count == 0:
# 如果 LLM 记错了代码(例如变量名拼错,或者缩进不对),这里会直接拦截。
# 错误信息会明确提示 LLM 检查空格或缩进,因为 Python 对缩进敏感。
raise Error(f"找不到该代码片段 `{old_str}`。请检查空格、缩进是否与源文件完全一致。")
# 情况 B: 歧义检测
if count > 1:
# 如果 LLM 提供的上下文太少,导致匹配到了多处(例如只提供了 'return True'),
# 工具会拒绝执行,并要求 LLM 提供更多周边的代码行来消除歧义。
raise Error(f"该代码片段出现了 {count} 次,操作被拒绝。请提供更多上下文行(如函数定义头、上方注释等)以确保唯一性。")
# 3. 执行替换
# 只有当 count == 1 时,才认为是安全的,执行字符串替换
write_file(path, content.replace(old_str, new_str))
这种设计的精妙之处在于:
-
抗幻觉(Anti-Hallucination):LLM 有时会“臆造”代码,或者记错变量名。传统的 Diff 可能会因为模糊匹配而错误地修改了相似的代码。而 Trae 的精确匹配机制要求
old_str必须与文件内容**逐字逐句(Verbatim)**一致。如果 LLM 记错了缩进(例如把 4 个空格记成了 2 个),或者把user_id记成了uid,count == 0的检查会直接拦截这次操作,保护源文件不被破坏。 -
强制上下文(Forced Contextualization):这是一种通过工具限制来引导 LLM 行为的设计。如果 LLM 偷懒,只想修改一个常见的
return True,工具会报错count > 1。这不仅阻止了错误的修改(可能改了错误的函数),还反向强迫 LLM 去“阅读”并提供return True上方的def check_status():,从而确保 LLM 在修改前真正定位到了正确的函数。这种机制实际上是在迫使 LLM 建立更强的局部上下文感知。
2. 实战演示:如何修改 5000 行的长文件?
面对长文件,Agent 无法一次性读取全文放入 Context Window。Trae Agent 模拟了人类工程师在 IDE 中工作的行为模式:先概览,再定位,最后聚焦修改。
-
分页查看 (
view):LLM 不会一次性读取整个文件。它首先使用view(path, view_range=[100, 200])查看可能包含 Bug 的区域(例如第 100 到 200 行)。这不仅节省了 Token,也避免了无关信息的干扰。 -
定位与复制:LLM 在返回的片段中发现了 Bug(例如在第 150 行)。它会“复制”包含 Bug 的那几行代码,作为
old_str。 -
构造工具调用:
{
"command": "str_replace",
"path": "/src/core/huge_logic.py",
"old_str": " if user.is_active:\n return True",
"new_str": " if user.is_active and not user.is_banned:\n return True"
}
注意,LLM 不需要知道这几行代码具体在第 150 行,它只需要知道这几行代码的内容。即便在 LLM 思考期间,文件的第 10 行被同事插入了新代码(导致第 150 行变成了第 160 行),上述 str_replace 依然能成功执行,因为它是基于内容锚点而非行号锚点的。这种鲁棒性对于多人协作的动态代码库尤为重要。
二、 全局透视:CKG 与 Bash 的混合检索
当面对陌生的代码库时,Agent 需要回答两个核心问题:
-
Definition(定义):“
OrderProcessor类是怎么实现的?它的__init__方法接受什么参数?” -
Reference(引用):“
calculate_total函数在哪些地方被调用了?修改它会影响哪些模块?”
许多 Agent 试图用向量数据库(Vector RAG)一站式解决,但在代码场景下,向量搜索往往不够精确。例如,搜索 "User" 可能会返回 User 类、user 变量、UserFactory 类,甚至注释里的 "user experience"。这种低精度的检索会给 Agent 带来巨大的噪声。Trae Agent 采用了一套**“结构化 + 文本化”的混合检索策略**,将代码检索的精度提升到了 IDE 级别。
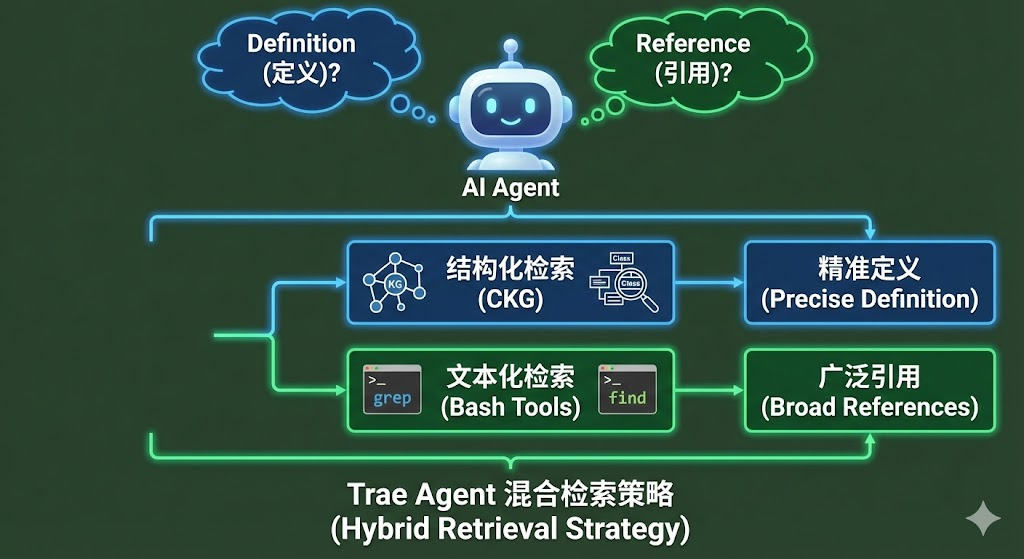
1. 结构化检索:代码知识图谱 (CKG)
Trae Agent 内置了一个轻量级的 AST 分析引擎(位于 trae_agent/tools/ckg/),专门用于精准查找定义。这是一个典型的“以空间换时间、以算力换精度”的设计。我们深入 ckg_database.py 来看看它是如何工作的。
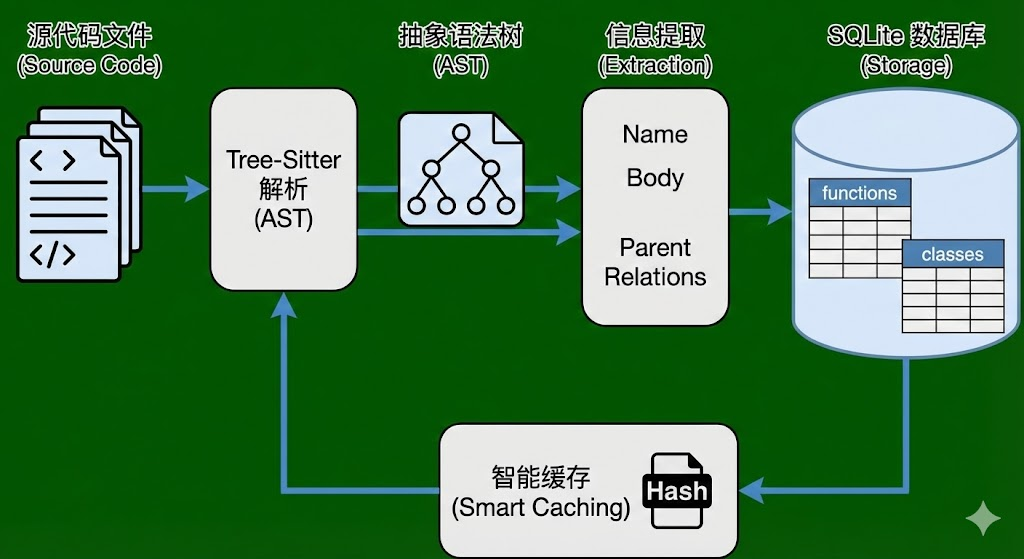
A. 构建过程 (Construction):Tree-Sitter 解析
CKG 的构建并非基于简单的文本分割(Chunking),而是基于严谨的语法解析。它使用 tree-sitter 库来生成代码的抽象语法树(AST)。
-
多语言支持:
ckg_database.py中定义了针对不同语言(Python, Java, C++, JS/TS 等)的递归访问器(Visitor),例如_recursive_visit_python。这意味着 Trae Agent 能够理解不同编程语言的语法结构,而不仅仅是把它们当作文本处理。 -
节点遍历:它遍历 AST 节点,精准识别出具有语义价值的节点,如
function_definition(函数定义)和class_definition(类定义)。它会自动忽略注释、空行等无关信息,聚焦于代码骨架。 -
信息提取:
-
标识符 (Name):提取函数名或类名,作为检索的索引键。
-
完整代码体 (Body):这是最关键的一步,它通过
root_node.text.decode()直接捕获了该函数或类的完整源代码。这意味着检索结果不仅告诉你“在哪里”,还告诉你“是什么”。 -
关系提取:它会记录
parent_function(父函数)和parent_class(父类),从而保留代码的层级结构(例如,知道run方法是属于Engine类的,而不是Car类的)。
-
# ckg_database.py 中的 Python 解析逻辑片段
def _recursive_visit_python(self, root_node, file_path, ...):
# 只有当节点类型是函数定义时才处理,过滤掉无关节点
if root_node.type == "function_definition":
# 提取函数名节点,这是检索的关键 Key
function_name_node = root_node.child_by_field_name("name")
# 提取完整源码,这是检索的 Value
body = root_node.text.decode()
# 创建结构化条目,包含语义层级信息
function_entry = FunctionEntry(
name=function_name_node.text.decode(),
file_path=file_path,
body=body,
parent_class=parent_class.name if parent_class else None, # 记录所属类
# ...
)
self._insert_entry(function_entry)
B. 存储机制 (Storage):SQLite 持久化
解析后的数据并不是只存在于内存中,而是被持久化到了本地的 SQLite 数据库中。这种设计使得 Trae Agent 能够处理甚至超过内存限制的大型项目。
-
Schema 设计:数据库包含两张核心表:
functions和classes。-
functions表存储:name,file_path,body,start_line,end_line,parent_class等。这使得我们可以执行复杂的 SQL 查询,比如“查找所有在utils.py文件中的函数”。 -
classes表额外存储:fields(字段列表) 和methods(方法列表)。这为 Agent 提供了类的概览视图。
-
-
智能缓存 (Smart Caching): 解析 AST 是一个计算密集型任务。为了避免每次启动都重新解析整个项目,CKG 实现了一套基于 Git Hash 或 文件元数据 Hash 的智能缓存机制。
-
系统会计算当前代码库的快照哈希(Snapshot Hash)。
-
如果发现本地已经存在对应哈希的
.db文件,则直接加载,实现秒级启动。 -
这种增量更新的策略,使得 Trae Agent 在大型项目中也能保持极快的响应速度。
-
C. 使用方式 (Usage):精准查询
当 LLM 调用 search_function(identifier="auth") 时,底层执行的是一个精准的 SQL 查询:
SELECT name, file_path, body, start_line, end_line
FROM functions
WHERE name = ?
结果会直接返回给 Agent。这种“查询即所得”的体验,让 Agent 无需打开文件就能阅读代码实现。 相比于 RAG 返回的“可能相关的代码片段”,CKG 返回的是“确定的、完整的函数定义”,这对于代码理解至关重要。
2. 文本化检索:Bash 工具 (Grep & Find)
CKG 虽然强大,但它只能解决“定义”问题。它无法回答“这个常量在哪里被使用了?”或者“TODO 注释在哪里?”这类问题。对于这些“引用”查找和非结构化信息检索,Trae Agent 回归了 Linux 哲学:没有什么比 grep 更适合查找字符串引用。
在 agent_prompt.py 中,Trae 明确指示 Agent 在思考过程中使用 Bash 工具。这赋予了 Agent 极大的灵活性,使其能够像人类开发者在终端中那样探索代码。
-
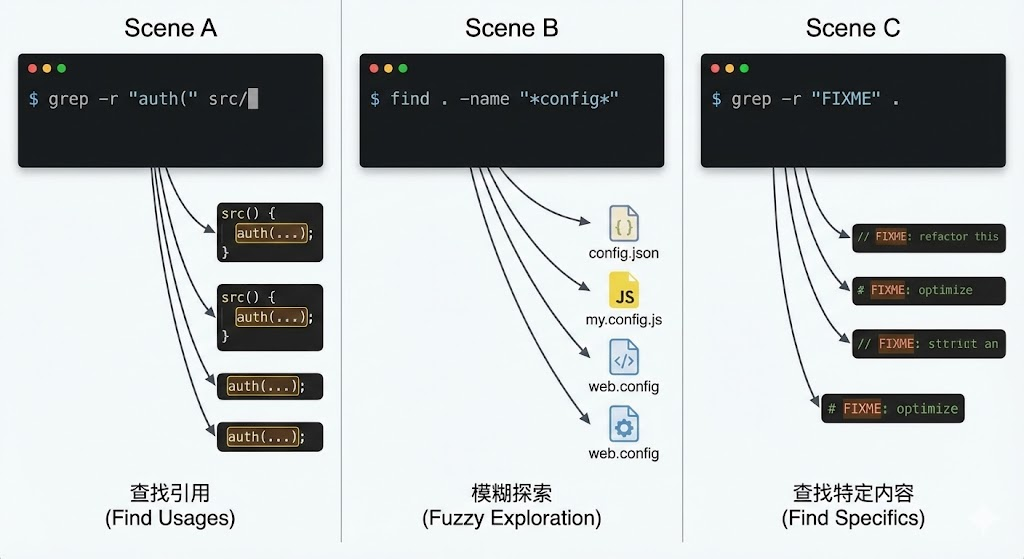
场景 A:查找引用 (Find Usages)。
-
命令:
grep -r "auth(" src/ -
作用:找出所有调用
auth函数的地方。这对于重构(Refactoring)或修改 API 签名非常重要,Agent 可以通过这个命令找到所有需要连带修改的调用点。
-
-
场景 B:模糊探索 (Fuzzy Exploration)。
-
命令:
find . -name "*config*" -
作用:寻找配置文件。当 Agent 不知道具体的配置文件名,只知道大概包含 "config" 时,这个命令非常有用。
-
-
场景 C:查找特定内容。
-
命令:
grep -r "FIXME" . -
作用:查找代码中遗留的待修复项。
-
3. 为什么不完全依赖 Embeddings?
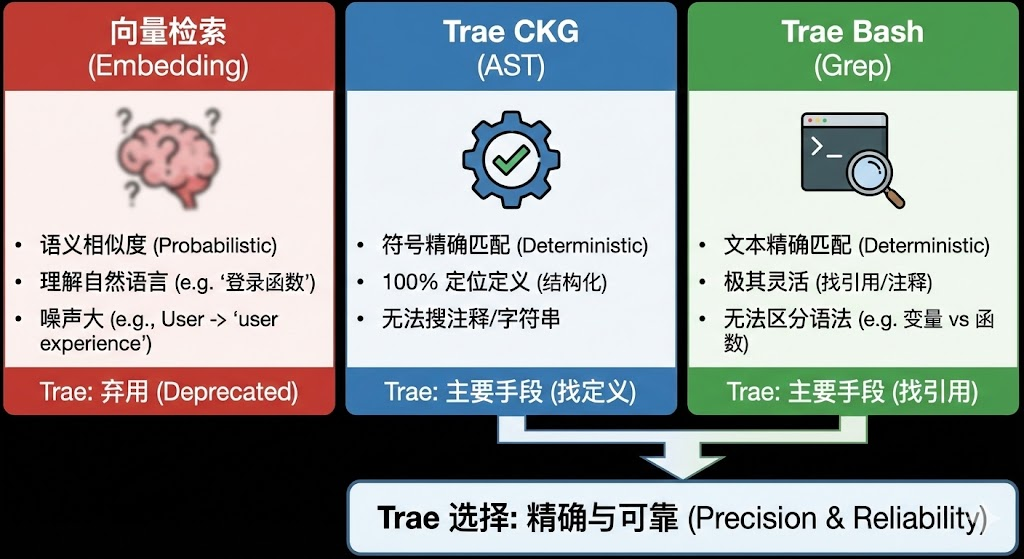
Embeddings(向量嵌入)在自然语言处理中表现优异,但在代码检索中存在局限性。Trae Agent 选择混合策略是基于对代码特性的深刻理解。
|
检索方式 |
向量检索 (Embedding) |
Trae CKG (AST) |
Trae Bash (Grep) |
|---|---|---|---|
|
匹配逻辑 |
语义相似度 (Probabilistic) |
符号精确匹配 (Deterministic) |
文本精确匹配 (Deterministic) |
|
优势 |
能理解自然语言查询(如“处理用户登录的函数”)。 |
100% 准确地定位定义,能够解析复杂的语法结构。 |
极其灵活,适用于查找引用、注释、字符串常量等。 |
|
典型失效场景 |
搜索 |
无法搜索注释或字符串内容。无法处理语法错误的代码。 |
无法区分 |
|
Trae 的选择 |
弃用 (在核心检索路径中) |
主要手段 (找定义) |
主要手段 (找引用) |
Trae Agent 的设计思路是:代码是结构化的逻辑,而不是模糊的自然语言。 因此,使用结构化的 AST 和精确的文本匹配,远比概率性的语义相似度更可靠。
三、 总结:确定性工程哲学的胜利
纵观 Trae Agent 的源码,我们可以看到一种明显的**“去 AI 化”**倾向。这听起来可能有些矛盾,但实际上是构建可靠 AI 系统的必经之路。
-
在编辑时,它不信任 LLM 的行号计算能力,而是强制使用全字匹配。它通过工具的限制,迫使 LLM 像人类一样通过“阅读上下文”来确认修改位置,而不是盲目地猜测行号。
-
在检索时,它不信任 LLM 的语义模糊搜索,而是强制建立AST 索引。它利用编译器级别的解析技术,为 LLM 提供最准确的代码导航图,确保每一次“跳转定义”都是准确无误的。
这种设计哲学将 LLM 从“执行者”降级为了“决策者”,而将繁琐、易错的执行环节交给了确定性的算法(AST 解析、字符串替换、Grep)。LLM 负责“思考”要做什么(比如“我需要修改 auth 函数”),而具体的“做”(找到 auth 函数的准确位置并替换文本)则由确定性的工具来完成。
这也正是 AI Agent 从“玩具”走向“生产力工具”的必经之路:用确定性的工具边界,去约束概率性的模型输出。 只有当我们将大模型的不确定性限制在可控范围内,才能真正发挥其强大的推理能力,解决复杂的软件工程问题。


















 2232
2232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











