






图谱检索增强生成的新篇章:LEGO-GraphRAG框架深入解读
本篇博客首发于本人掘金 https://juejin.cn/post/7445957275204272138
导读:在人工智能领域,大型语言模型(LLMs) 的快速发展带来了处理复杂查询和特定领域任务的能力。然而,LLMs在处理特定领域查询和复杂上下文时存在局限性,尤其是在准确性和事实一致性方面。为了解决这些问题,图谱检索增强生成(GraphRAG) 技术应运而生。最近,一篇名为《LEGO-GraphRAG: Modularizing Graph-based Retrieval-Augmented Generation for Design Space Exploration》的论文,为我们提供了一个全新的视角和解决方案。
11月6号的论文,目前仍是初步版本 [Preliminary Version]
https://arxiv.org/abs/2411.05844
评价:内部的图比较多(看得有点费劲),但是实验的模块化思想和一些实践结论适合我们了解。故分享。

研究背景与挑战
LEGO-GraphRAG 框架的提出,旨在解决GraphRAG中的两个主要挑战:缺乏统一框架来系统地分类和评估现有解决方案,以及缺乏对GraphRAG过程的模块化分解。这些挑战限制了GraphRAG在实际应用中的性能和可扩展性。
LEGO-GraphRAG框架
LEGO-GraphRAG 框架通过将GraphRAG的检索过程分解为三个相互连接的模块:子图提取、路径过滤和路径细化,提供了一个系统化的设计空间。这种模块化设计不仅提高了系统的灵活性和可扩展性,还使得研究者能够针对每个模块优化算法和模型,从而提高整体性能。
下面的思维导图还包含论文的实验得出的优缺点结论。
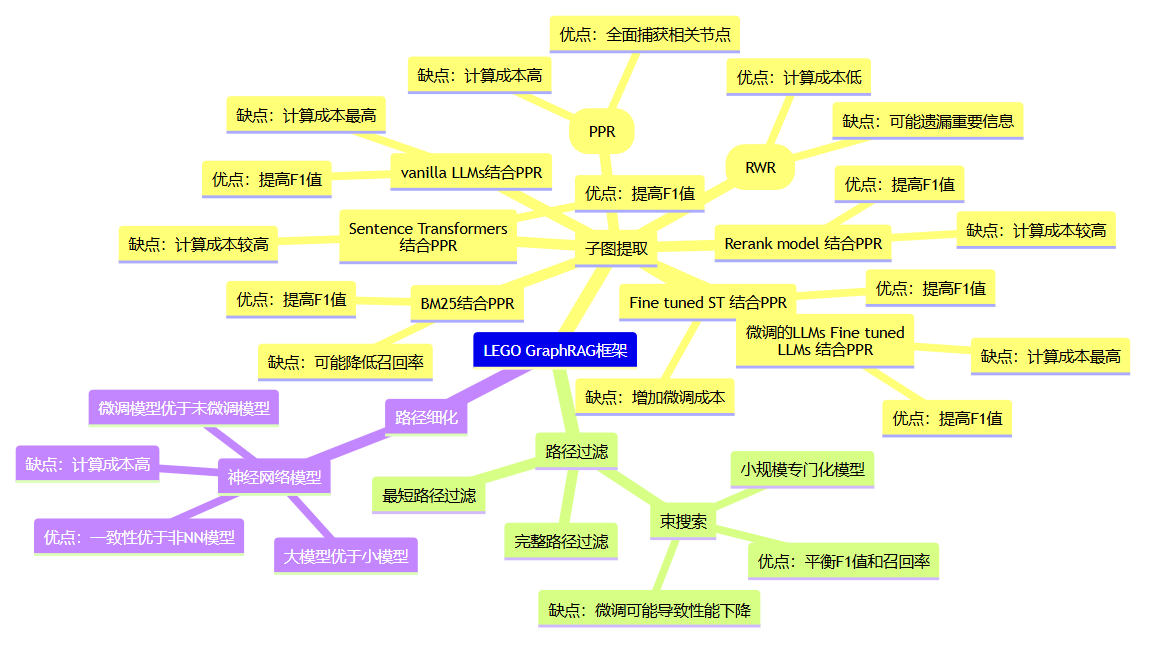
子图提取模块(Subgraph-Extraction)
- 目标:将整个图的搜索空间缩小到一组与查询相关的子图。
- 定义: S E ( G , ϵ q , q ) → ⋃ v i ( q ) ∈ ϵ q g ( q , v i ( q ) ) → g q SE(G, \epsilon_q, q) \rightarrow \bigcup_{v_i^{(q)} \in \epsilon_q} g_{(q, v_i^{(q)})} \rightarrow g_q SE(G,ϵq,q)→⋃vi(q)∈ϵqg(q,vi(q))→gq
其中, G G G表示图, ϵ q \epsilon_q ϵq表示从查询 q q q中提取的实体和关系集合, g q g_q gq表示查询相关的子图。
子图提取模块的目标是将整个图的搜索空间缩小到一组与查询相关的子图。这一模块采用了多种方法,包括个性化PageRank(PPR)和随机游走与重启(RWR),以及结合统计方法和神经网络模型的方法。
路径过滤模块(Path-Filtering)
- 作用:从提取的子图中检索推理路径。
- 定义: P F ( g q , ϵ q , q ) → { P i } → P PF(g_q, \epsilon_q, q) \rightarrow \{P_i\} \rightarrow \mathcal{P} PF(gq,ϵq,q)→{Pi}→P
其中,
g
q
g_q
gq表示子图,
ϵ
q
\epsilon_q
ϵq表示查询实体集合,
P
\mathcal{P}
P表示推理路径集合。
路径过滤模块的作用是从提取的子图中检索推理路径。这一模块同样采用了结构化方法和基于统计的方法,以及结合束搜索的神经网络模型。
路径精炼模块(Path-Refinement)
- 用途:精炼推理路径,确保只有与查询最相关的路径被用于LLMs的推理过程中。
- 定义: P R ( P , q , ϵ q ) → P ^ PR(\mathcal{P}, q, \epsilon_q) \rightarrow \hat{\mathcal{P}} PR(P,q,ϵq)→P^
其中, P \mathcal{P} P表示推理路径集合, q q q表示查询内容, ϵ q \epsilon_q ϵq表示查询实体集合, P ^ \hat{\mathcal{P}} P^表示精炼后的推理路径集合。
路径细化模块用于精炼推理路径,确保只有与查询最相关的路径被用于LLMs的推理过程中。这一模块主要依赖于神经网络模型,以提高路径的相关性和准确性。
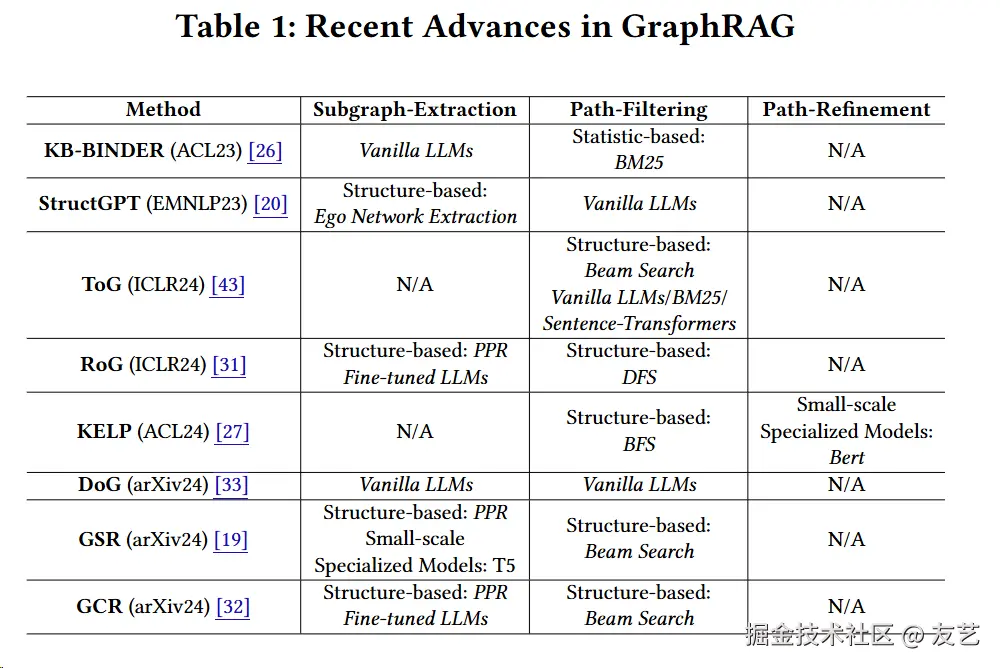
论文也给出最近的GrahRAG按照这种模块化拆解的对比:
-
子图提取(Subgraph-Extraction) :描述了每种方法在从大型图谱中提取与查询相关的小图谱(子图)时所采用的技术。
- Vanilla LLMs:使用通用的大型语言模型。
- Structure-based:基于图谱结构的方法,如自我网络提取(Ego Network Extraction)和个性化PageRank(PPR)。
- Small-scale Specialized Models:小型的专门化模型,如T5。
-
路径过滤(Path-Filtering) :介绍了在提取的子图中筛选相关路径的方法。
- Statistic-based:基于统计的方法,如BM25算法。
- Structure-based:基于图谱结构的方法,如深度优先搜索(DFS)和广度优先搜索(BFS)。
- Beam Search:束搜索,一种启发式搜索算法,用于在图中找到最优路径。
现在,我们再来了解本论文的框架:由于提出了模块化拆解,所以本身的三部分框架也是可以拼凑的。其中Non-NN Models代表非神经网络模型。
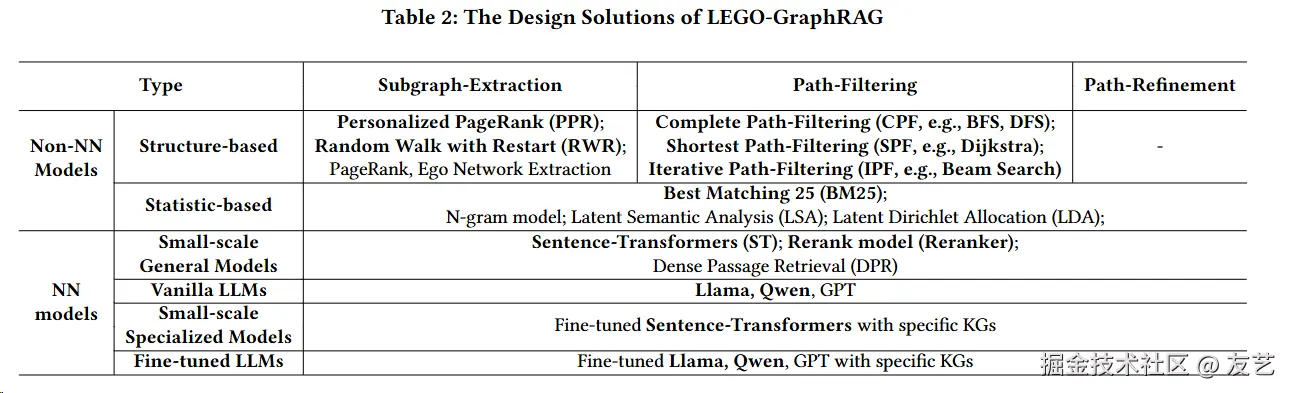
实验设计
为了验证LEGO-GraphRAG框架的有效性,研究者构建了21个不同的LEGP-GraphRAG实例(排列组合一波),并进行了广泛的实证研究。
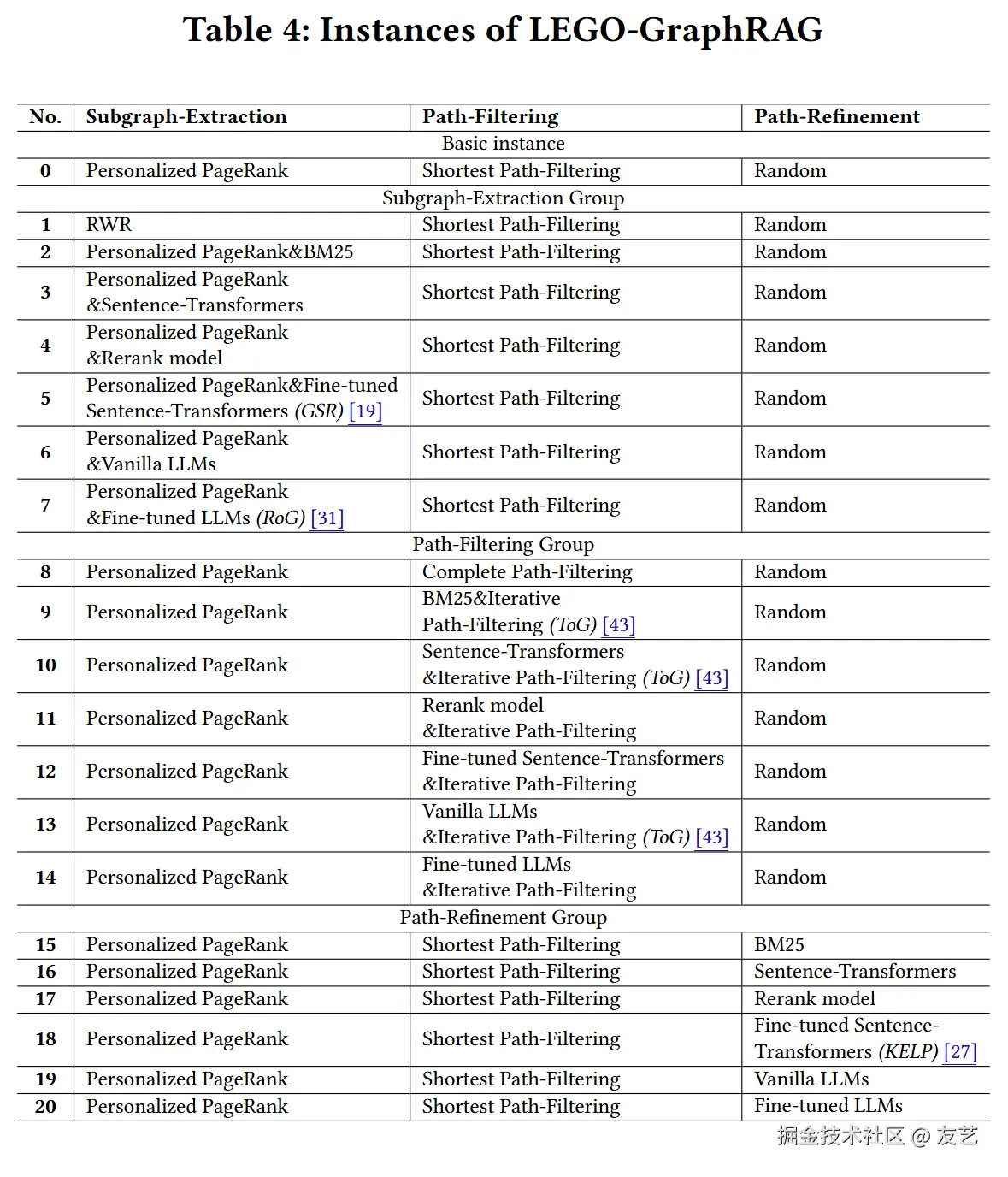
实验设计数据集使用了四个广泛使用的KBQA数据集:WebQSP、CWQ、GrailQA和WebQuestions。
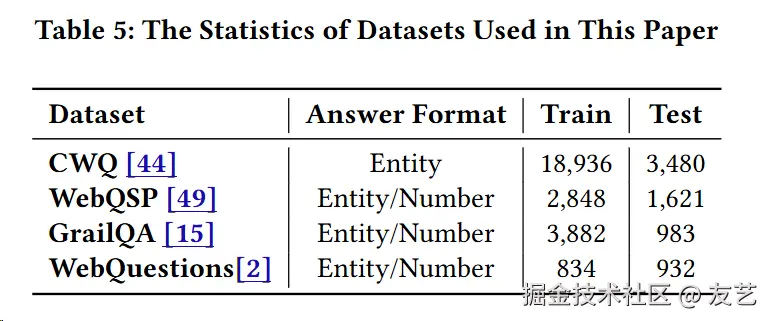
实验采用了以下评估指标来衡量模型性能:
- 精确率(Precision):衡量检索到的路径中与查询相关的准确性。
- 召回率(Recall):衡量检索到的路径中覆盖所有相关路径的完整性。
- F1值(F1):精确率和召回率的调和平均值,综合衡量模型的准确性和完整性。
- 命中率(Hit Ratio, HR):衡量模型生成的答案与真实答案的匹配程度。
实现细节
实验中使用了三种LLM模型:Llama-2-7b-chat-hf、Llama-3-8B-Instruct和Qwen2-7B-Instruct。对于Sentence-Transformers实例,使用all-MiniLM-L6-v2作为骨干模型。对于Rerank模型实例,使用bge-reranker-v2-m3作为重排模型。
参数设置
在子图提取模块中,设置最大实体数为2000,个性化PageRank的阻尼因子为0.8,随机游走重启次数为64。在路径过滤模块中,最短路径过滤和完全路径过滤不需要参数,迭代路径过滤的束宽设置为128。在路径精炼模块中,设置保留的推理路径数量为64。
结果与分析
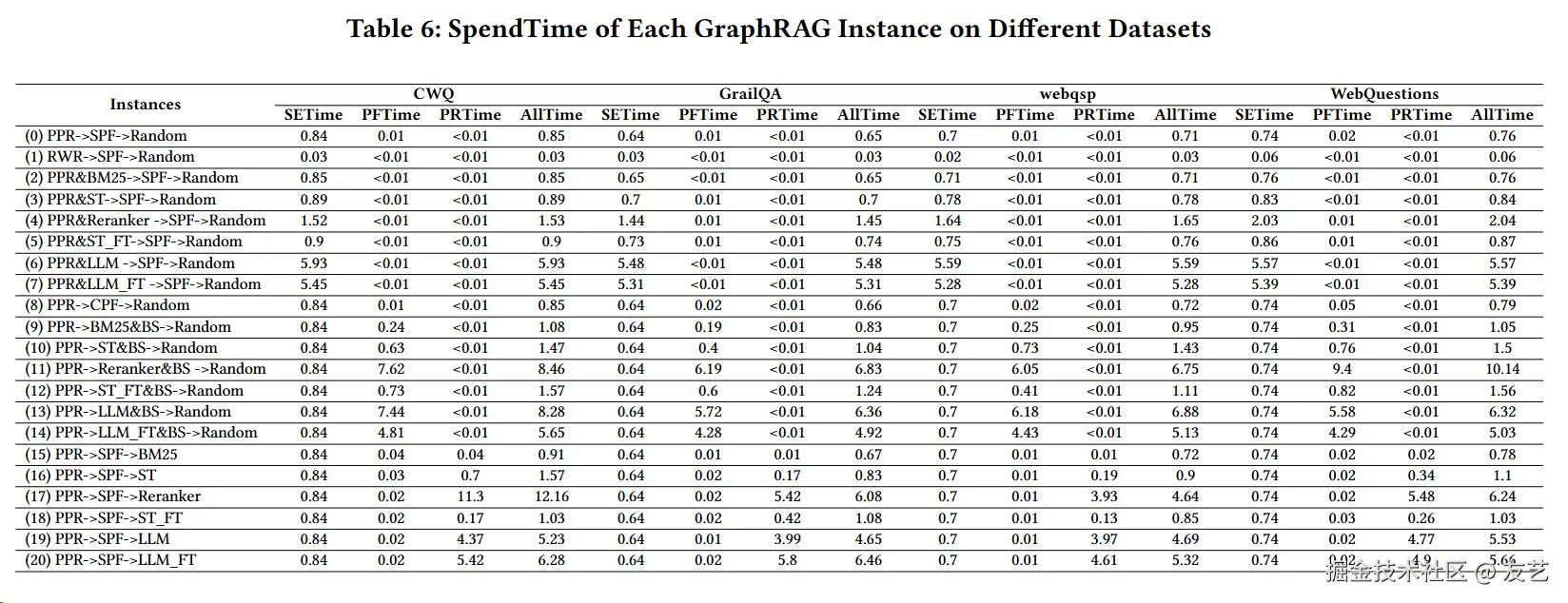
实验结果(居然没有加粗!)揭示了以下几个关键点:
子图提取模块
- Personalized PageRank(PPR) :在捕获相关节点方面表现优于Random Walk with Restart(RWR),尽管其F1分数较低,但召回率更高。
- 统计方法:不适合增强PPR算法,因为它们简化了语义考虑,可能导致关键推理信息的丢失。
- 基于(微调)LLM的方法:在保持PPR高召回率的同时,提高了F1分数,但执行时间最长。
路径过滤模块
- 完整路径过滤和最短路径过滤算法:表现相当。
- 结合束搜索的方法:小规模(专门化)模型表现最佳,但微调小规模模型的收益有限。
- (微调)LLM结合束搜索:性能不佳,主要由于所选LLM(llama3-8b)的能力有限。
路径细化模块
- 神经网络模型:一致优于非神经网络模型,且在NN模型类别中,较大模型比较小模型表现更好,微调模型比非微调模型表现更好。
关键发现
- 子图提取模块:PPR在捕获相关节点方面表现优于RWR,尽管其F1分数较低,但召回率更高。
- 路径过滤模块:结合束搜索的小规模(专门化)模型表现最佳,但微调小规模模型的收益有限。
- 路径细化模块:神经网络模型一致优于非神经网络模型,且在NN模型类别中,较大模型比较小模型表现更好,微调模型比非微调模型表现更好。
论文评价
优点与创新
- 模块化框架:提出了LEGO-GraphRAG,将GraphRAG的检索过程分解为三个相互连接的模块:子图提取、路径过滤和路径细化,提供了一个系统化的设计空间。
- 算法和模型分类:系统地总结了每个模块中可用的算法和神经网络(NN)模型,提供了对GraphRAG实例设计的清晰理解。
不足
- 计算成本高:NN模型,特别是大规模预训练语言模型和微调后的模型,在预训练和执行阶段需要显著的计算资源,这限制了其在实际应用中的可行性。
- 图耦合的影响:尽管小规模专用模型和微调后的模型在性能上表现优异,但它们通常需要对特定图进行微调,这可能导致在其他图上的泛化能力下降。
结语
LEGO-GraphRAG框架为我们提供了一个强大的工具,以应对GraphRAG在实际应用中的挑战。通过模块化设计和系统化的解决方案分类,LEGO-GraphRAG不仅提高了检索准确性和推理效果,还为未来的研究和应用指明了方向。随着技术的不断发展,我们期待LEGO-GraphRAG能够在更广泛的领域中发挥其潜力,推动基于知识图谱检索增强生成的发展。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











