



|
主机角色 |
地址 | |
|
master01 nginx+keepalibed |
192.168.20.102 | |
|
master02nginx+keepalibed |
192.168.20.103 | |
|
master03nginx+keepalibed |
192.168.20.104 | |
|
node01 |
192.168.20.105 |
# 1、修改主机名
hostnamectl set-hostname k8s-master01
hostnamectl set-hostname k8s-master02
hostnamectl set-hostname k8s-master03
hostnamectl set-hostname k8s-node01
# 2、三台机器添加host解析
cat >> /etc/hosts << "EOF"
192.168.20.101 k8s-master01
192.168.20.102 k8s-master02
192.168.20.103 k8s-master03
192.168.20.104 k8s-node01
192.168.20.200 api-server
EOF
关闭一些服务
# 1、关闭selinux
sed -i 's#enforcing#disabled#g' /etc/selinux/config
setenforce 0
# 2、禁用防火墙,网络管理,邮箱
systemctl disable --now firewalld NetworkManager postfix
# 3、关闭swap分区
swapoff -a
# 注释swap分区
cp /etc/fstab /etc/fstab_bak
sed -i '/swap/d' /etc/fstab
sshd优化
# 1、加速访问
sed -ri 's@^#UseDNS yes@UseDNS no@g' /etc/ssh/sshd_config
sed -ri 's#^GSSAPIAuthentication yes#GSSAPIAuthentication no#g' /etc/ssh/sshd_config
grep ^UseDNS /etc/ssh/sshd_config
grep ^GSSAPIAuthentication /etc/ssh/sshd_config
systemctl restart sshd
# 2、密钥登录(主机点做):为了让后续一些远程拷贝操作更方便
ssh-keygen
ssh-copy-id -i root@k8s-master-01
ssh-copy-id -i root@k8s-node-01
ssh-copy-id -i root@k8s-node-02
增大文件打开数量
cat > /etc/security/limits.d/k8s.conf <<'EOF'
* soft nofile 65535
* hard nofile 131070
EOF
ulimit -Sn
ulimit -Hn
所有节点配置模块自动加载,此步骤不做的话(kubeadm init直接失败)
modprobe br_netfilter
modprobe ip_conntrack
cat >>/etc/rc.sysinit<<EOF
#!/bin/bash
for file in /etc/sysconfig/modules/*.modules ; do
[ -x $file ] && $file
done
EOF
echo "modprobe br_netfilter" >/etc/sysconfig/modules/br_netfilter.modules
echo "modprobe ip_conntrack" >/etc/sysconfig/modules/ip_conntrack.modules
chmod 755 /etc/sysconfig/modules/br_netfilter.modules
chmod 755 /etc/sysconfig/modules/ip_conntrack.modules
lsmod | grep br_netfilter
# =====================》chrony服务端:服务端我们可以自己搭建,也可以直接用公网上的时间服务器,所以是否部署服务端看你自己
# 1、安装
yum -y install chrony
# 2、修改配置文件
mv /etc/chrony.conf /etc/chrony.conf.bak
cat > /etc/chrony.conf << EOF
server ntp1.aliyun.com iburst minpoll 4 maxpoll 10
server ntp2.aliyun.com iburst minpoll 4 maxpoll 10
server ntp3.aliyun.com iburst minpoll 4 maxpoll 10
server ntp4.aliyun.com iburst minpoll 4 maxpoll 10
server ntp5.aliyun.com iburst minpoll 4 maxpoll 10
server ntp6.aliyun.com iburst minpoll 4 maxpoll 10
server ntp7.aliyun.com iburst minpoll 4 maxpoll 10
driftfile /var/lib/chrony/drift
makestep 10 3
rtcsync
allow 0.0.0.0/0
local stratum 10
keyfile /etc/chrony.keys
logdir /var/log/chrony
stratumweight 0.05
noclientlog
logchange 0.5
EOF
# 4、启动chronyd服务
systemctl restart chronyd.service # 最好重启,这样无论原来是否启动都可以重新加载配置
systemctl enable chronyd.service
systemctl status chronyd.service
# =====================》chrony客户端:在需要与外部同步时间的机器上安装,启动后会自动与你指定的服务端同步时间
# 下述步骤一次性粘贴到每个客户端执行即可
# 1、安装chrony
yum -y install chrony
# 2、需改客户端配置文件
mv /etc/chrony.conf /etc/chrony.conf.bak
cat > /etc/chrony.conf << EOF
server 192.168.20.101 iburst
driftfile /var/lib/chrony/drift
makestep 10 3
rtcsync
local stratum 10
keyfile /etc/chrony.key
logdir /var/log/chrony
stratumweight 0.05
noclientlog
logchange 0.5
EOF
# 3、启动chronyd
systemctl restart chronyd.service
systemctl enable chronyd.service
systemctl status chronyd.service
# 4、验证
chronyc sources -v
更新yum源
# 1、清理
rm -rf /etc/yum.repos.d/*
yum remove epel-release -y
rm -rf /var/cache/yum/x86_64/6/epel/
# 2、安装阿里的base与epel源
curl -s -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
curl -s -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum clean all;yum makecache
# 或者用华为的也行
# curl -o /etc/yum.repos.d/CentOS-Base.repo https://repo.huaweicloud.com/repository/conf/CentOS-7-reg.repo
# yum install -y https://repo.huaweicloud.com/epel/epel-release-latest-7.noarch.rpm
更新系统内核
yum update -y --exclud=kernel*
安装基础常用软件
yum -y install expect wget jq psmisc vim net-tools telnet yum-utils device-mapper-persistent-data lvm2 git ntpdate chrony bind-utils rsync unzip git bash-comepletion
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@localhost ~]# una
unalias uname
[root@localhost ~]# uname -r
3.10.0-1160.71.1.el7.x86_64
三个节点操作
#安装
yum localinstall -y /root/kernel-lt*
#调到默认启动
grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg
#查看当前默认启动的内核
grubby --default-kernel
#重启系统
reboot
三个节点安装ipvs
# 1、安装ipvsadm等相关工具
yum -y install ipvsadm ipset sysstat conntrack libseccomp
# 2、配置加载
cat > /etc/sysconfig/modules/ipvs.modules <<"EOF"
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in ${ipvs_modules};
do
/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe ${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
安装 containerd(三台节点都要做)
制这里
rpm -e libseccomp-2.3.1-4.el7.x86_64 --nodeps先卸载
wget https://mirrors.aliyun.com/centos/8/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm
rpm -ivh libseccomp-2.5.1-1.el8.x86_64.rpm
cd /etc/yum.repos.d
wget http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install containerd* -y
复制这里
mkdir -pv /etc/containerd
containerd config default > /etc/containerd/config.toml
替换默认pause镜像地址:这一步很重要
grep sandbox_image /etc/containerd/config.toml
sed -i 's/registry.k8s.io/registry.cn-hangzhou.ailiyuncs.com\/google_containers/' /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
请务必确认新地址是否可用:sandbox_image="registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6"
配置systemd作为容器的cgroup driver
grep SystemdCgroup /etc/containerd/config.toml
sed -i 's/SystemdCgroup \= false/SystemdCgroup \=true/' /etc/containerd/config.toml
grep SystemdCgroup /etc/containerd/config.toml
配置加速器(必须配置,不然后续安装cni插件无法从不docker。io下载)
sed -i 's/config_path\ =.*/config_path = \"\/etc\/containerd\/certs.d\"/g' /etc/containerd/config.toml
mkdir -p /etc/containerd/certs.d/docker.io
cat > /etc/containerd/certs.d/docker.io/hosts.toml << EOF
server = "https://docker.io"
[host."https://dockerproxy.com"]
capabilities = ["pull", "resolve"]
[host."https://docker.m.daocloud.io"]
capabilities = ["pull", "resolve"]
[host."https://docker.agsv.top"]
capabilities = ["pull", "resolve"]
[host."https://registry.docker-cn.com"]
capabilities = ["pull", "resolve"]
EOF
配置开机自启动conrainerd
systemctl daemon-reload && systemctl restart containerd
systemctl enable --now containerd
systemctl status containerd
测试拉取没问题
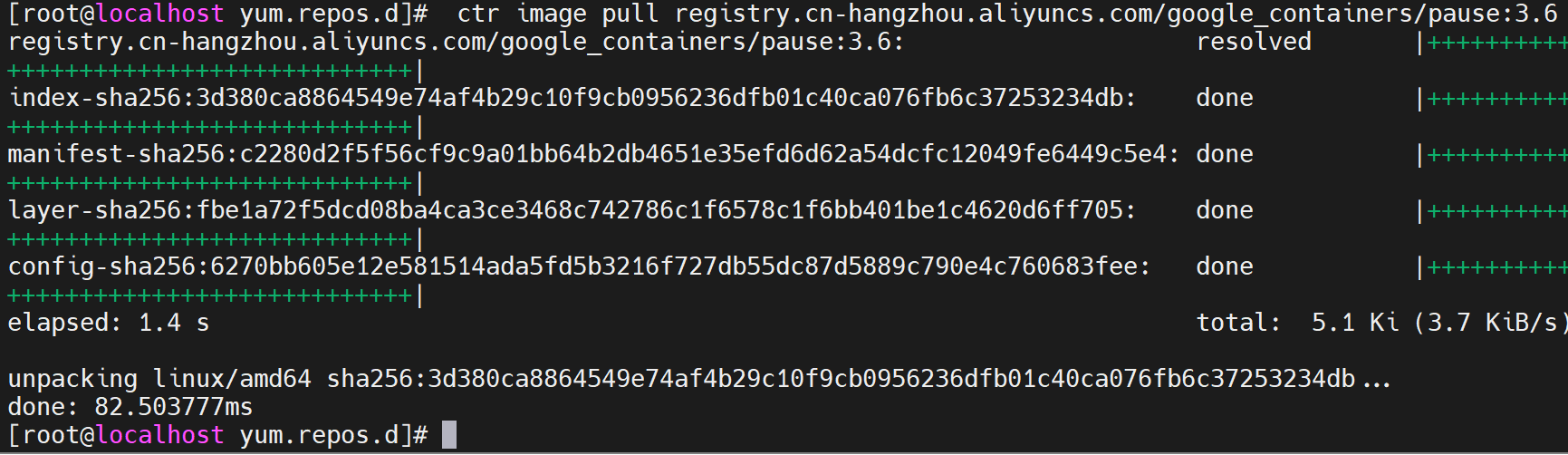
ctr image pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9
安装keepalibed加nginx
# 1、添加repo源
cat > /etc/yum.repos.d/nginx.repo << "EOF"
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
EOF
# 2、安装
yum install nginx -y
# 3、配置
cat > /etc/nginx/nginx.conf <<'EOF'
user nginx nginx;
worker_processes auto;
events {
worker_connections 20240;
use epoll;
}
error_log /var/log/nginx_error.log info;
stream {
upstream kube-servers {
hash $remote_addr consistent;
server k8s-master01:6443 weight=5 max_fails=1 fail_timeout=3s;
server k8s-master02:6443 weight=5 max_fails=1 fail_timeout=3s;
server k8s-master03:6443 weight=5 max_fails=1 fail_timeout=3s;
}
server {
listen 8443 reuseport; # 监听8443端口
proxy_connect_timeout 3s;
proxy_timeout 3000s;
proxy_pass kube-servers;
}
}
EOF
# 4、启动
systemctl restart nginx
systemctl enable nginx
systemctl status nginx
三台部署master部署keepalived
yum -y install keepalived
修改keepalive的配置文件(根据实际环境,interface eth0可能需要修改为interface ens33)
# 编写配置文件,各个master节点需要修改router_id和mcast_src_ip的值即可。
# ==================================> master01
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id 192.168.20.101
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_port.sh 8443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface ens36
virtual_router_id 100
priority 100
advert_int 1
mcast_src_ip 192.168.20.101
# nopreempt # 启用抢占模式,高优先级节点出现时会接管VIP
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_nginx
}
virtual_ipaddress {
192.168.20.200
}
}
EOF
# ==================================> master02
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id 192.168.20.102
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_port.sh 8443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface ens36#端口注意替换自己的
virtual_router_id 100
priority 100
advert_int 1
mcast_src_ip 192.168.20.102
# nopreempt # 这行注释掉,否则即使一个具有更高优先级的备份节点出现,当前的 MASTER 也不会
被抢占,直至 MASTER 失效。
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_nginx
}
virtual_ipaddress {
192.168.20.200
}
}
EOF
# ==================================> master03
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id 192.168.20.103
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_port.sh 8443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface ens36
virtual_router_id 100
priority 100
advert_int 1
mcast_src_ip 192.168.20.103
# nopreempt # 这行注释掉,否则即使一个具有更高优先级的备份节点出现,当前的 MASTER 也不会
被抢占,直至 MASTER 失效。
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_nginx
}
virtual_ipaddress {
192.168.20.200
}
}
EOF
所有master节点上创建健康检查脚本
vim /etc/keepalived/check_port.sh
#!/bin/bash
# 设置环境变量,确保所有必要的命令路径正确
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
CHK_PORT=$1
if [ -n "$CHK_PORT" ]; then
PORT_PROCESS=$(/usr/sbin/ss -lt | grep ":$CHK_PORT" | wc -l)
if [ $PORT_PROCESS -eq 0 ]; then
echo "Port $CHK_PORT Is Not Used,End."
exit 1
fi
else
echo "Check Port Cant Be Empty!"
exit 1
fi
启动
systemctl restart keepalived
systemctl enable keepalived
systemctl status keepalived
动态查看keepalived日志
journalctl -u keepalived -f
安装k8s的管理工具
降本增效
三台机器准备k8s源
cat > /etc/yum.repos.d/kubernetes.repo << "EOF"
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm/repodata/repomd.xml.key
EOF
yum install -y kubelet-1.30* kubeadm-1.30* kubectl-1.30*
systemctl enable kubelet && systemctl start kubelet && systemctl status kubelet
主节点操作(node节点不执行)
仅在master节点执行
kubeadm config images list
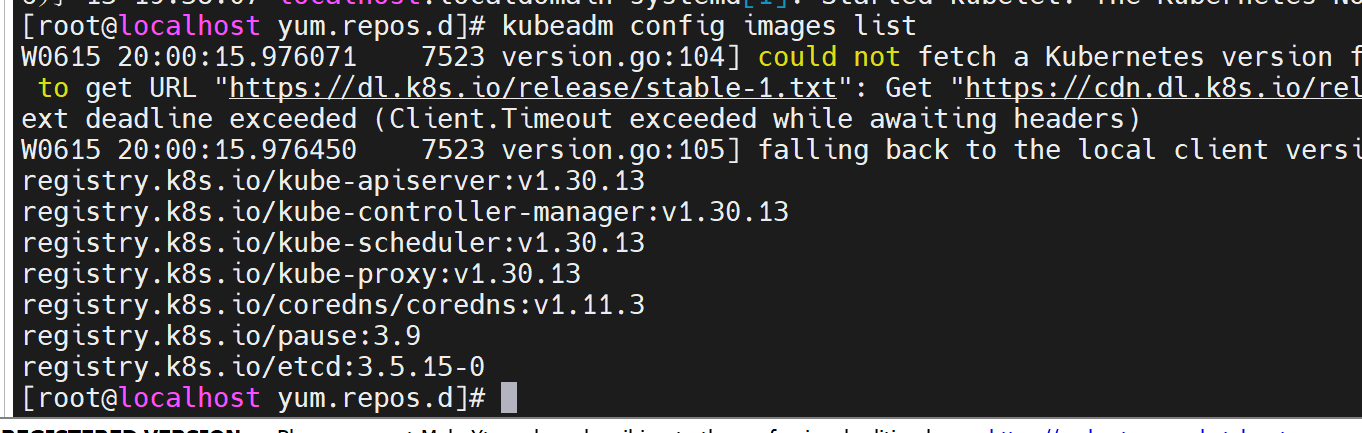
kubeadm config print init-defaults > kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
localAPIEndpoint:
advertiseAddress: 0.0.0.0
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: k8s-master01
taints: null
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
apiServer:
timeoutForControlPlane: 4m0s
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kubernetesVersion: 1.30.3
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
多个master节点加入集群
上传证书
将集群控制平面所需的证书上传到集群中,并存储在一个叫做 kubeadm-certs 的 Secret 中
root@master01 ~]# kubeadm init phase upload-certs --upload-certs # 你也可以在安装
的时候kubeadm init的默认加上选项--upload-certs来上传证书,那这一步就不需要了
输出结果
...
[upload-certs] Using certificate key:
75fb3ae07478f5777b187e45cd5e85cdf9f3bd8dbeeaf5919416e9022b394dea # 得到该值,后续
添加master需要用到它
上述指令做了3件事
1. 上传证书到集群:将已经生成的控制平面证书上传到 Kubernetes 集群,使得这些证书可以在多个
Master 节点之间共享。
2. 生成证书密钥:生成一个唯一的密钥用于加密和保护这些证书。
3. 输出证书密钥:在终端输出这个证书密钥,后续添加新的 Master 节点时需要使用。
上述指令目的是:
方便其他 Master 节点在加入集群时能够共享这些证书。这个步骤极大简化了多 Master 节点的配
置过程,确保所有 Master 节点使用相同的证书。
是否一定要做这一步?
不一定。如果你没有这一步骤,那么每一个新加入的 Master 节点会自己生成一份新的证书,这样
可能导致集群内的证书不一致,增加管理复杂度。使用
kubeadm init phase upload-certs --
upload-certs 可以确保所有控制平面节点使用相同的证书,简化管理并且提高安全性和一致性。
因此,尽管这一步不是绝对必要的,但强烈推荐使用它。
(2)添加master节点到集群
所有master节点加入集群,需要用到上面的token信息,需要使用"--certificate-key"选项指定。(你的
环境要替换!)
master02节点上
kubeadm join 192.168.20.101:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:ce75317e5c7b888e761adbdbbc10bae617add4f420996f243bb980f5265ceb95 \
--control-plane \
--certificate-key 12124c6c0ae362a19a73eae3b60b6315fdf73fbb0e3c16610a9a970306c86f97
yaml文件拉起集群
kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerification --ignore-preflight-errors=Swap
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#~/.kube/config 是 kubectl 的配置文件,里面包含了访问 Kubernetes 集群所需的身份信息、API Server 地址、证书等内容。
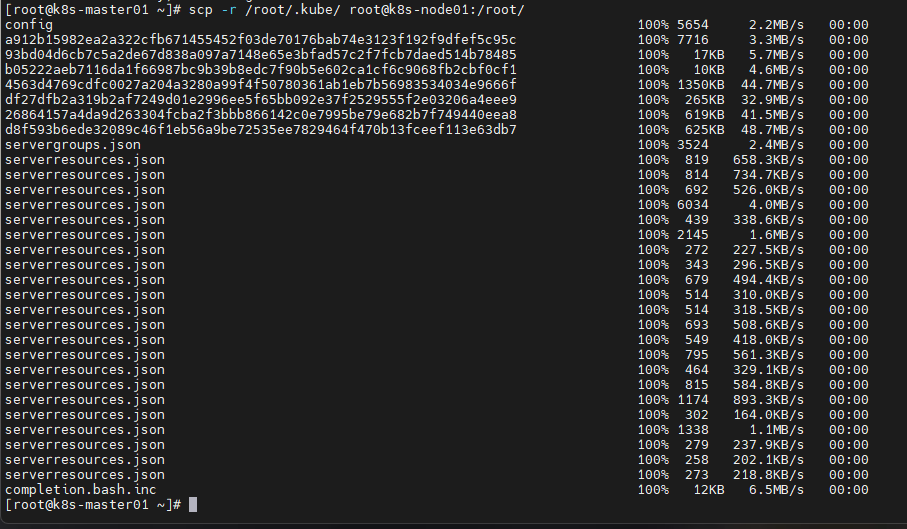
#没有这个文件是访问不到api server的,scp拷贝到node节点
scp -r /root/.kube root@worker01:/root/
scp -r /root/.kube root@worker02:/root/
#可选
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> vi /etc/profile
source /etc/profile
#自动补齐命令
source <(kubectl completion bash) # set up autocomplete in bash into the current shell, bash-completion package should be installed first.
echo "source <(kubectl completion bash)" >> ~/.bashrc # add autocomplete permanently to your bash shell.
alias k=kubectl
complete -o default -F __start_kubectl k
#持久化生效
echo "alias k=kubectl" >> ~/.bashrc
echo "complete -o default -F __start_kubectl k" >> ~/.bashrc
master加入集群
kubeadm join api-server:8443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:25791614a45d7b9acdaf8b3ccce172340f47a2be67adf095848b0c19d4f6a854 \
--control-plane \
--certificate-key 1d1649f3ac26e27034cbabe8f818526157414c262abcf67c0716abb514fdf40b
node加入集群
kubeadm join 192.168.68.110:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:ba98a530c894883ad7e6a22056e2e163db26b25571a8187a2b2c9c10163b6155
安装网络插件
wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
grep -i image kube-flannel.yml #查看flannel版本
[root@master01 flannel]# vim kube-flannel.yml
apiVersion: v1
data:
...
net-conf.json: |
{
"Network": "10.244.0.0/16", # 与--pod-network-cidr保持一致
"Backend": {
"Type": "vxlan"
}
}
阿里云镜像
grep -i image kube-flannel.yml #查看flannel版本和镜像,一共有三个镜像
image: ghcr.io/flannel-io/flannel:v0.26.7
image: ghcr.io/flannel-io/flannel-cni-plugin:v1.6.2-flannel1
#这两个个镜像在国内用阿里云的容器镜像服务做一个镜像仓库得到两个地址
#registry.cn-shanghai.aliyuncs.com/egon-k8s-test/flannel:v0.26.7
#registry.cn-shanghai.aliyuncs.com/egon-k8s-test/flannel-cni-plugin:v1.6.2-flannel1
#然后修改flannel.yml里的镜像地址
安装时错误的解决方法
kubeadm reset -f
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
选做项
yum clean all
yum remove kube*
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
etcd使用(补充)
补充:etcdctl的官网下载地址:https://github.com/etcd-io/etcd/releases
ETCDCTL_API=3 etcdctl \
--endpoints=https://192.168.71.103:2379,https://192.168.71.101:2379,https://192.168.71.102:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member list
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member list
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
get / --prefix --keys-only
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
get /registry/deployments/default/mynginx
etcd数据中存放的不是json原文,而是protocol buffer序列化之后的数据
二、k8s版本升级方案与实践(1.31.0)(******)
背景:k8s没有一个LTS长期稳定版本
注意:
1、升级前最好备份所有组件及数据---》etcd(/var/lib/etcd)
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save etcdbackupfile.db # 把当前节点的etcd数据导出为快照
mv /var/lib/etcd /var/lib/etcd_bak
mkdir /var/lib/etcd
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot restore etcdbackupfile.db --data-dir=/var/lib/etcd
升级方案
背景:k8s没有一个LTS长期稳定版本
(1)升级前最好备份所有组件及数据,例如etcd
(2)不要跨两个大版本进行升级,可能会存在版本bug,如:
1.19.4-->1.20.4 通常ok
1.19.4-->1.21.4 慎重
跨多个版本的可以逐个版本依次进行升级,因为下一个版本通常会考虑到针对上一个版本的升级兼容性
例如
1.19.4-->1.21.4
可以先从1.19.4 升级到1.20.4
然后再从1.20.4 升级到 1.21.4
(3)升级前要在测试环境进行充分的演练,充分考虑到回滚方案(事先将回滚动作制作成脚本,方便生
产环境遇到问题时快速响应)
前提注意(etcd备份)
注意:
1、升级前最好备份所有组件及数据---》etcd(/var/lib/etcd)
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save etcdbackupfile.db # 把当前节点的etcd数据导出为快照
升级方案
对于线上环境,升级k8s需要做到不中断当前业务容器的灰度升级,常见方案有如下两种
(1)方案一:蓝绿方式
仿照现有k8s集群,部署一套新环境,在新环境里部署指定版本的k8s,然后把业务应用也部署到新环
境。然后将流量切换到新环境
(2)方案二:先更新master上的k8s服务版本,再逐个批量更新Node上的k8s服务版本(高版本
的master通常可以管理更低版本的node,但版本差异过大也会有问题)
蓝绿的方式没啥没说的(就是部署一套全新环境,然后切流量即可),我们直接看方案二吧
我主要安装k8s的方案二,针对kubeadm方式升级
1
为了考虑到资源最大化,把master节点也进行调度,污点去掉(但是不建议,为了降本增效,这里做了测试环境去做)
[root@k8s-master01 ~]# kubectl taint node k8s-master01 node-role.kubernetes.io/control-plane:NoSchedule-
node/k8s-master01 untainted
[root@k8s-master01 ~]#kubectl taint node k8s-master02 node-role.kubernetes.io/control-plane:NoSchedule-
[root@k8s-master01 ~]#kubectl taint node k8s-master03 node-role.kubernetes.io/control-plane:NoSchedule-
查看
[root@k8s-master01 ~]# kubectl describe node k8s-master01 | grep -i taint
Taints: <none>
[root@k8s-master01 ~]# kubectl describe node k8s-master02 | grep -i taint
Taints: <none>
升级过程中发现报错

从错误信息来看,Kubernetes 节点 k8s-master03 上的 kubelet 无法为 Pod 创建网络沙箱,原因是找不到 loopback CNI 插件
解决方案
1. 登录到问题节点
首先需要登录到 k8s-master03 节点执行后续操作:
ssh k8s-master03
2. 检查 CNI 插件目录
确认 /opt/cni/bin 目录下是否缺少 loopback 插件:
ls -l /opt/cni/bin | grep loopback
如果没有输出,说明确实缺少该插件。
3. 安装 CNI 基础插件
从官方下载并安装 CNI 基础插件包(包含 loopback 插件):
# 创建 CNI 目录(如果不存在)
sudo mkdir -p /opt/cni/bin
# 下载 CNI 插件包(选择合适的版本,这里使用 v1.3.0)
sudo curl -L "https://github.com/containernetworking/plugins/releases/download/v1.3.0/cni-plugins-linux-amd64-v1.3.0.tgz" -o /tmp/cni-plugins.tgz
# 解压到 /opt/cni/bin 目录
sudo tar -zxvf /tmp/cni-plugins.tgz -C /opt/cni/bin
# 验证 loopback 插件是否安装成功
ls -l /opt/cni/bin | grep loopback
应该看到类似以下输出:
-rwxr-xr-x 1 root root 9886720 Jul 1 16:30 loopback
4. 检查 CNI 配置文件
确保 /etc/cni/net.d/ 目录下有网络配置文件(例如 Flannel、Calico 等):
ls -l /etc/cni/net.d/
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
5. 重启 kubelet 服务
sudo systemctl restart kubelet
# 检查 kubelet 状态
sudo systemctl status kubelet
6. 验证问题是否解决
# 在控制节点上执行
kubectl get nodes k8s-master03
# 检查之前失败的 Pod 是否重新创建成功
kubectl get pods -A
如果仍有 Pod 处于 Terminating 或 Pending 状态,可以尝试删除它们让 Kubernetes 重新创建:
kubectl delete pod <pod-name> -n <namespace> --force --grace-period=0
检查一下我的pod服务
apiVersion: apps/v1
kind: Deployment
metadata:
name: mynginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-test
image: crpi-c3mxuhf0d0v0fwpq.cn-beijing.personal.cr.aliyuncs.com/wyz-123/nginx:v1
command: ["tail", "-f", "/dev/null"]
ports:
- containerPort: 80
一切正常

继续升级
配置新的yum源,版本为1.30->>>1.31
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/rpm/repodata/repomd.xml.key
更新
yum clean all;yum makecache
升级节点步骤综述
升级节点步骤综述
下面说的node包括master node与worker node
整体顺序是:先升master再升级worker
升级或更新节点步骤:(其他node节点如果要升级,则采用一样的步骤)
1、先隔离Node节点的业务流量,备份好数据(如果是master节点则记着备份/var/lib/etcd目录)
2、cordon禁止新pod调度到当前node # kubectl cordon node master01
3、对关键服务创建PDB保护策略,确保下一步的排空时,关键服务的pod至少有1个副本可用(在
当前节点以外的节点上有分布)
4、drain排空业务pod(静态pod不可能被排空,我们要升级的就是静态pod及kubelet等组件)
5、升级当前node上的软件
6、uncordon当前nod
添加PDB保护策略:(虽然我们建议一个关键的不可中断服务通常应该至少两副本,但实际情况可能
不会这么规范,此时如果你们部门的小弟执行了上面的步骤排空了pod导致了过程中服务不可用这个锅
就是你的了,我们可以添加PDB策略来对一些关键服务进行硬性限制,加了之后再去drain排空的时候,
如果存在一些受PDB保护的应用,则会drain失败,此时会硬性要求你先扩容副本,因为你已经cordon
过了,再启新副本一定是在新节点上
开始升级--升级master节点
注意在你的负载中,先把master01的负载先摘掉,业务流量别打过去
备份etcd
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save etcdbackupfile.db
还原
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot restore etcdbackupfile.db --data-dir=/xxx
禁止调度了,我要升级,pod不影响,知识迁移到别的pod了
kubectl cordon k8s-master01
对关键服务创建PDB保护策略(无则略)
drain排空业务pod(静态pod不可能被排空,我们要升级的就是静态pod及kubelet等组件
kubectl drain k8s-master01 --delete-local-data --ignore-daemonsets --force
迁移i成功
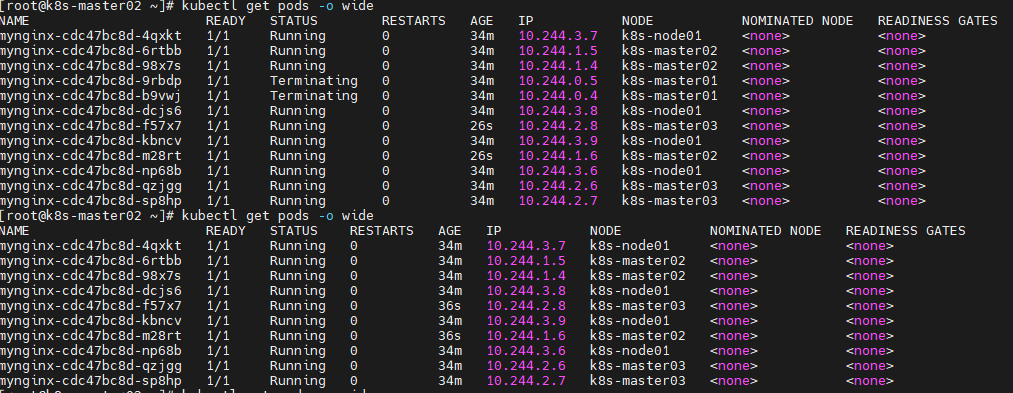
静态pod没有排掉,因为我们需要升级这些
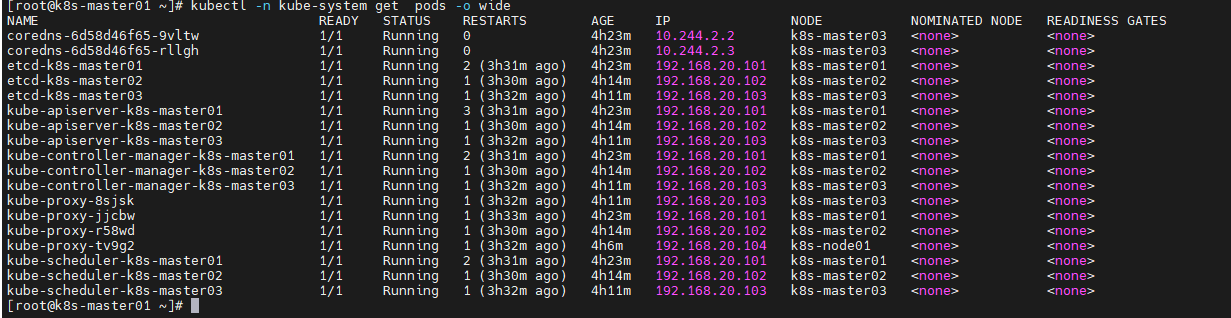
在master节点上,升级kubadm,对应版本必须一致1.31.0
yum install -y kubeadm-1.31.0 --disableexcludes=kubernetes
看一下升级计划
kubeadm upgrade plan
问题:发现在查看计划列表的时候,版本不兼容

找到合适的版本即可
kubectl -n kube-system set image deployment/coredns coredns=registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.11.1
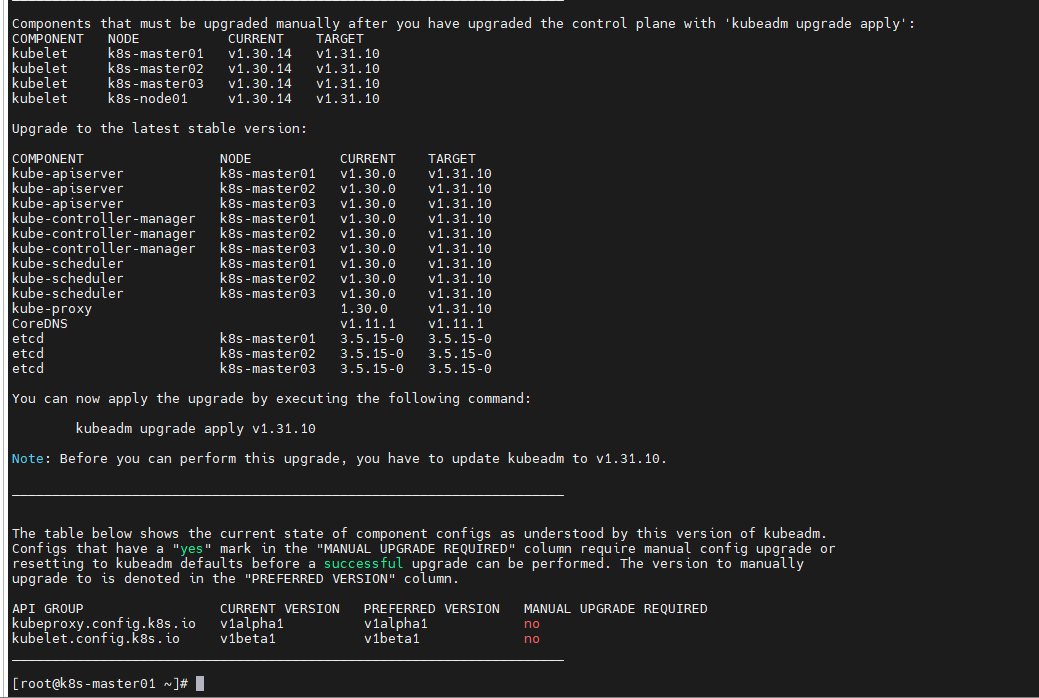
更新列表
kubeadm upgrade apply v1.31.0
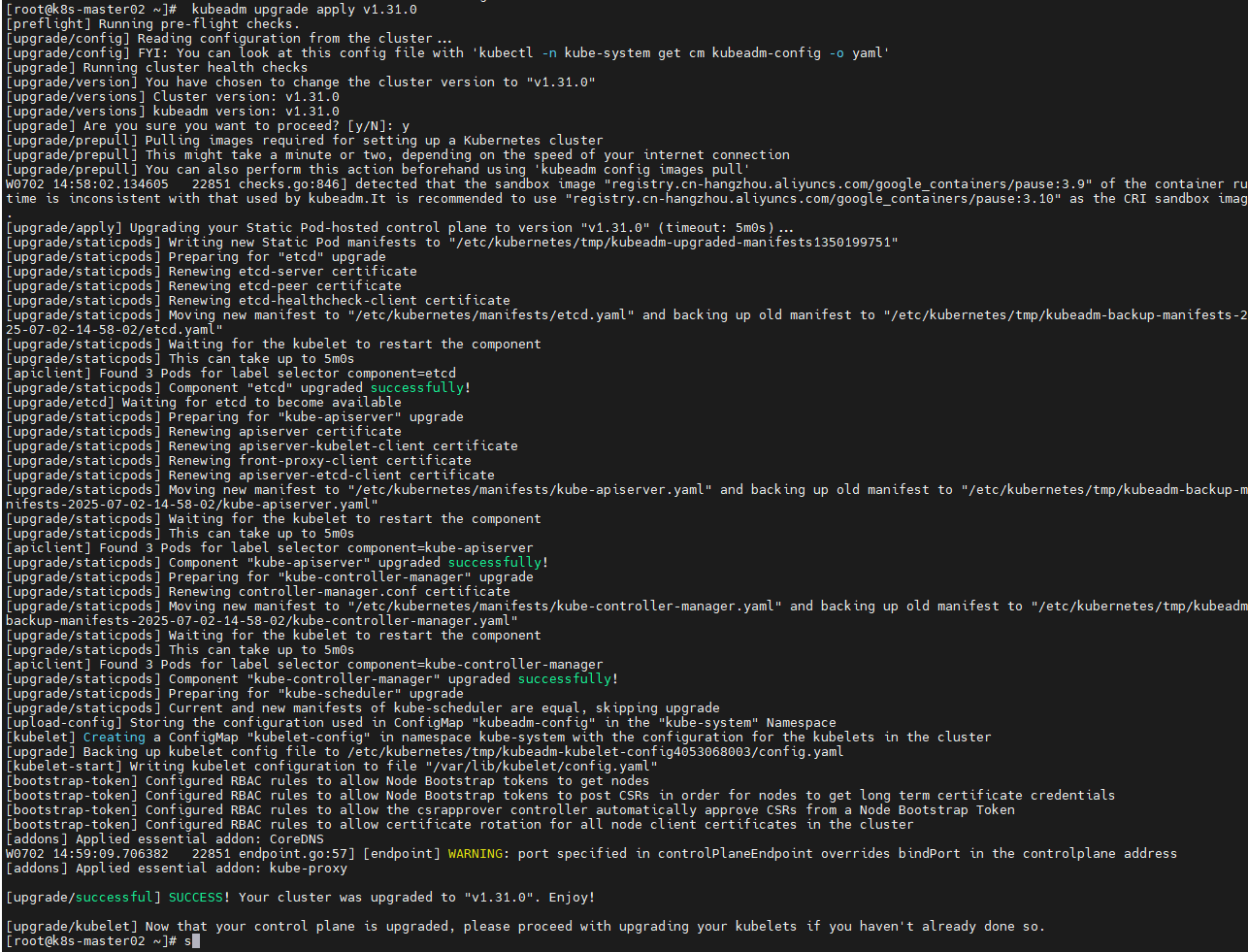
如果是高可用还需要在其他 master 节点上执行命令:(否则会导致其上的pod无法正确启动,如果你之 前没有做过cordon排空那该节点上的pod就会处于CreateContainerConfigError状态,执行下述命令才 可以恢复正常)
kubeadm upgrade node
在master节点上执行升级kubelet和kubectl
yum install -y kubelet-1.31.0 kubectl-1.31.0 --disableexcludes=kubernetes
重启
systemctl daemon-reload && systemctl restart kubelet

解除可以调度
kubectl uncordon k8s-master01
升级node节点(同理上述操作)
前提:升级节点的软件,或者是硬件例如增大内存,都会涉及到的节点的暂时不可
用,这与停机维护是一个问题,我们需要考虑的核心问题是节点不可用过程中,如何
确保节点上的pod服务不中断!
没权限
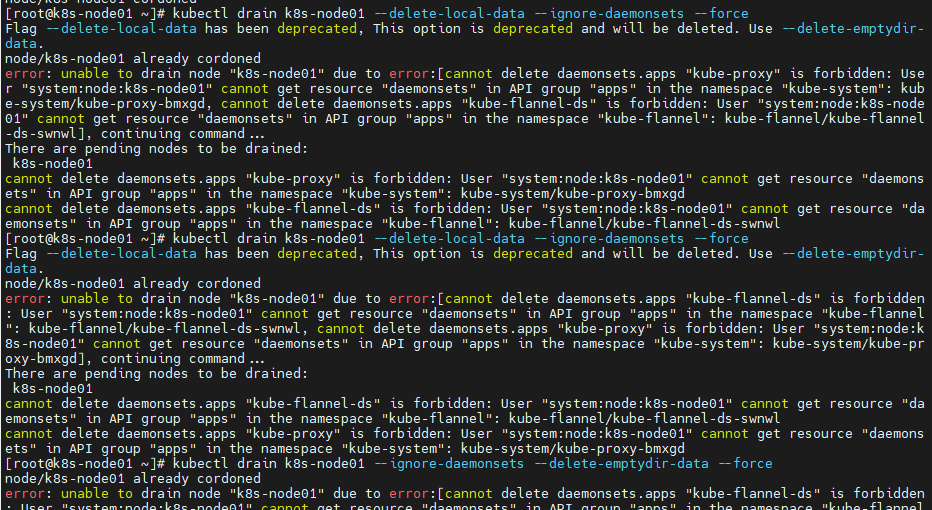
从k8s的master给一份

配置新的yum源,版本为1.30->>>1.31
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/rpm/repodata/repomd.xml.key
更新
yum clean all;yum makecache
禁止调度了,我要升级,pod不影响,知识迁移到别的pod了
kubectl cordon k8s-node01
对关键服务创建PDB保护策略(无则略)
drain排空业务pod(静态pod不可能被排空,我们要升级的就是静态pod及kubelet等组件
kubectl drain k8s-node01 --delete-local-data --ignore-daemonsets --force
在node节点上,升级kubadm,对应版本必须一致1.31.0
yum install -y kubeadm-1.31.0 --disableexcludes=kubernetes
因为node上没有api-server这种服务就不需要kubeadm apply
kubeadm upgrade node
在node节点上执行升级kubelet和kubectl
yum install -y kubelet-1.31.0 kubectl-1.31.0 --disableexcludes=kubernetes
重启
systemctl daemon-reload && systemctl restart kubelet
解除可以调度
kubectl uncordon k8s-node01

















 3104
3104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









