




 本文详细介绍了Python字典的实现机制,包括开放式寻址、C结构、字典初始化、添加和移除键值对的过程。字典通过哈希表存储,使用哈希函数确保键的均匀分布,解决冲突主要依赖于探测序列。在添加键值对时,如果达到一定填充比例,字典会自动调整大小以保持效率。
本文详细介绍了Python字典的实现机制,包括开放式寻址、C结构、字典初始化、添加和移除键值对的过程。字典通过哈希表存储,使用哈希函数确保键的均匀分布,解决冲突主要依赖于探测序列。在添加键值对时,如果达到一定填充比例,字典会自动调整大小以保持效率。
python字典是使用哈希表实现的。它是一个数组,其索引是使用键上的哈希函数获得的。
哈希函数的目标是将键均匀分贝在数组中。
假设我们用字符串作为键,哈希函数可以定义成下面这种:
arguments: string object
returns: hash
function string_hash:
if hash cached:
return it
set len to string's length
initialize var p pointing to 1st char of string object
set x to value pointed by p left shifted by 7 bits
while len >= 0:
set var x to (1000003 * x) xor value pointed by p
increment pointer p
set x to x xor length of string object
cache x as the hash so we don't need to calculate it again
return x as the hash如果使用大小为x的数组存储键/值对,则我们使用等于x-1的掩码来计算该对在数组中的插槽索引。这使得时隙索引的计算快速。由于下面描述的调整大小机制,找到空插槽的可能性很高。这意味着在大多数情况下进行简单的计算是有意义的。如果数组的大小为8,则'a'的索引为:hash('a')&7 =0。'b'的索引为3,'c'的索引为2, “ z”为3,与“ b”相同,这里有一个碰撞。
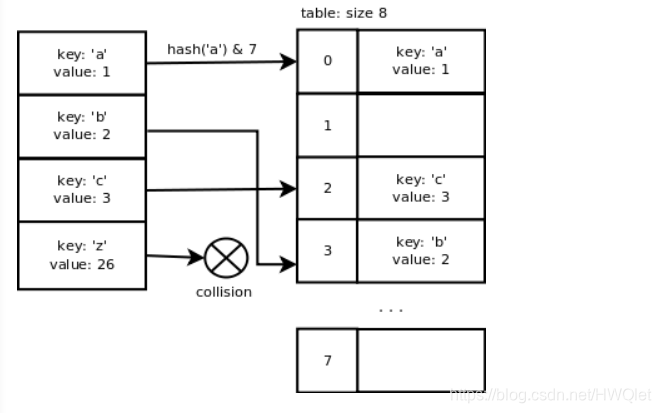
当键是连续的时,哈希函数可以很好的我完成工作,添加‘z'之后就发生了冲突,因为不够连续。当然我们可以用链表的形式在处理冲突,但是查找时间会增加
开放式寻址
开放式寻址是使用探测的冲突解决方法。在“ z”的情况下,插槽索引3已在阵列中使用,因此我们需要探查其他索引以查找尚未使用的索引。添加一个键/值对也将平均O(1)和查找操作。
二次探测序列用于找到空闲时隙。代码如下:伪代码
j = (5*j) + 1 + perturb;
perturb >>= PERTURB_SHIFT;
use j %2**i as the next table index;重复执行5 * j + 1会迅速放大不影响初始索引的位中的微小差异。变量“ perturb”使哈希码的其他位起作用。
让我们看一下表大小为32且j = 3时的探测顺序。3-> 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









