




 本文详细解析了C++和C中字符串的定义方式及其内部实现机制,强调了字符串与字符数组的区别,以及在内存中如何存储和访问字符串。
本文详细解析了C++和C中字符串的定义方式及其内部实现机制,强调了字符串与字符数组的区别,以及在内存中如何存储和访问字符串。
记得大一在学习c++的时候,讲字符串的时候感觉听的还行,但老师讲到和c中字符串的区别的时候就懵逼了。~~~
C++中:
字符串可以通过#include <string>来直接定义字符串,给我们带来很大的方便,比如我们可以直接 string str1=“jflkasjh”;
C可以认为是C++的子集,就是C中有的,C++都可以通过#include <libname>来包含相应的头文件。所以在C++中有两种处理字符串的方式,一种是string类库中的方法,还有一种就是C风格的字符串。
首先我们看两个例子:
char str[8]={'a','b','c','d','e','f','g','w'}; //这只是单纯的字符数组而不是字符串
char str2[8]={'a','b','c','d','e','f','g','\0'}; //这是字符数组也是字符串
所以不难看出,字符串一定是字符数组(就是以'\0'结尾的字符数组),而字符数组不一定是字符串
所以按照以上的输出,如果我们cout<<str<<endl;将会可能出现意想不到的现象:
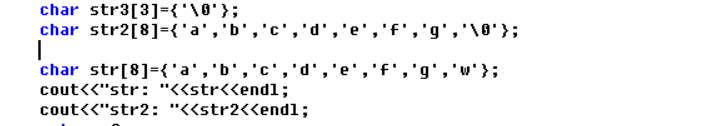

然后我们在看一下调整str3的代码位置出现的现象:
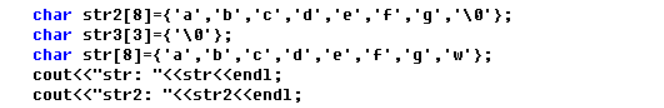

大家看到这里可能就很迷惑了,为什么会出现上述的情况呢。其实这和内存空间分配有关,我们这里采用的不是动态创建数组的方法,所以变量都在 栈 空间里面,而动态创建的变量在堆空间里面。这里大家可以去了解堆和栈两种内存空间的分配机制。
总之,上述现象输出就是要碰到'\0'才会停止输出,然后又因为是栈空间中,所以读取了str的8个字符后没有读到'\0'就继续往下面读然后输出。栈空间是从低地址往高地址读的,越靠后的变量在栈空间的越低的地址,所以上述两种情况大家应该就明白了吧。
所以在C中为了方便定义字符串我们可以这样:char c[]="fjakdsjfkahgz",这样的话既不用关心字符串的长度,另外还隐式的包括了字符串结尾的'\0'空字符,所以我们在定义缓冲的时候需要数组长度减一就是为了给末尾的'\0'腾个位置出来
字符和字符串的区别:字符在内存中存的是一个8位整数,而字符串在内存中存的是字符串首元素的地址。所以我们才能够用cout<<strname;来输出字符串,因为找到了字符串的首地址,然后cout就不断地址+1+1+1来往下读取数据。
“S”和‘S'有区别吗:很明显是有的,“S”实际是’S',‘\0’(也是字符数组,包含'S'和'\0'两个字符),而‘S'就是字符S(存在形式为8位整数)

















 2726
2726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









