




 本文详述了使用sharding-jdbc与seata实现数据库的分库分表及分布式事务处理,通过整合到SpringBoot项目中,展示了从理论到实践的全过程。包括工程搭建、配置、执行流程解析及源码跟踪。
本文详述了使用sharding-jdbc与seata实现数据库的分库分表及分布式事务处理,通过整合到SpringBoot项目中,展示了从理论到实践的全过程。包括工程搭建、配置、执行流程解析及源码跟踪。
sharding-jdbc+seata实现分库分表和分布式事务
sharding-jdbc 的相关理论&使用文档参考官网(https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/)
seata 的相关理论&使用文档参考官网(https://github.com/seata/seata)
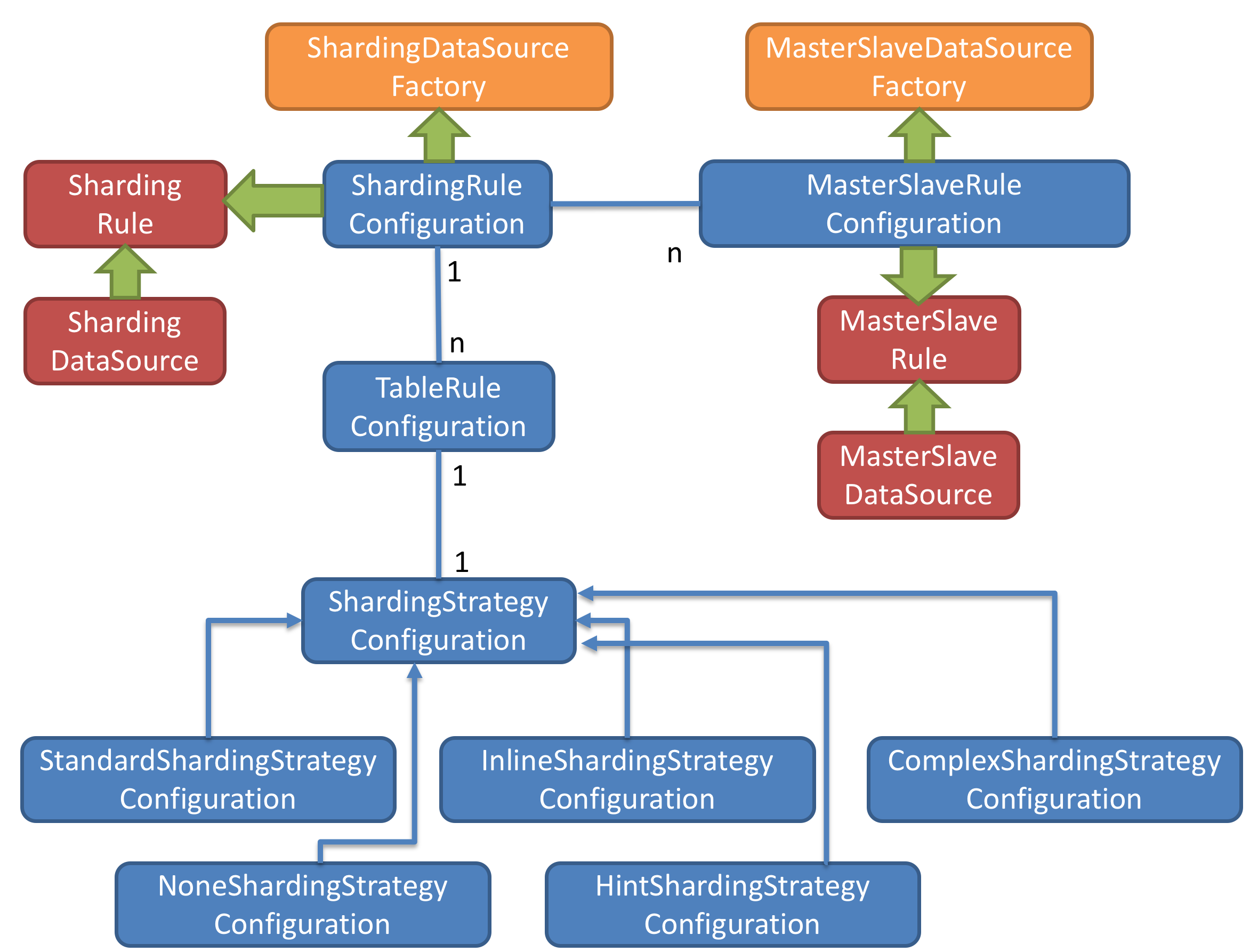
sharding-jdbc可以理解为增强版的驱动,用户可以通过对图中的蓝色部分类进行创建,然后向上使用黄色工厂来进行创建满足规则的jdbc驱动,实现分库分表和读写分离。
工程搭建
本文不引入注册中心等其他组件。
seata-server
参考:https://github.com/seata/seata-workshop
下载解压seata,这里不需要做任何配置修改,因为这里只针对分库分表且多数据源的项目进行分布式事务实现,整合到微服务不是重点。如有需要,参考官网改一下配置就行了。
启动seata-server:指定事务操作记录的存储模式为file
seata-server.sh -p 8091 -m file
整合到springboot项目
springboot项目地址:https://github.com/yangzhouhu/shardingsphere-springboot 用得着的话点个star啊
不论是已有项目,还是新项目。除了引入jar依赖外,还需要引入几个配置文件,参考官网
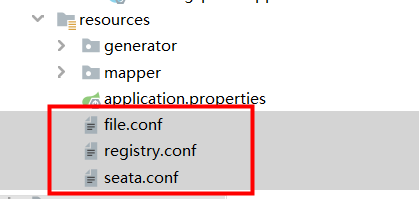
参数说明可以参考https://seata.io/zh-cn/docs/user/configurations.html
sharding-jdbc在数据源创建时的流程
在配置好实际数据源后,调用ShardingDataSourceFactory.createDataSource()方法,流程是这样的
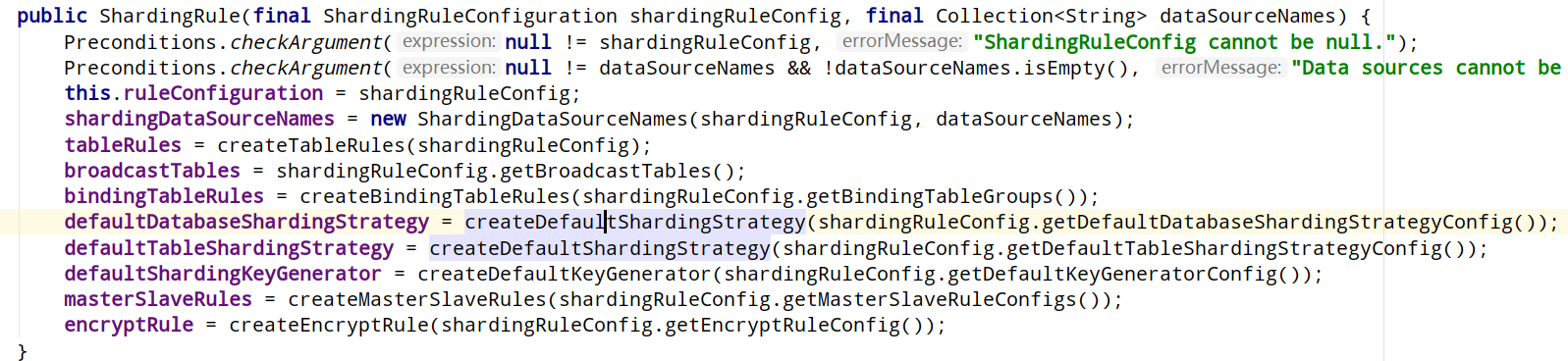
这里的shardingDataSourceNames初始化,会去掉master和slave的数据库名。
ShardingDataSource.java
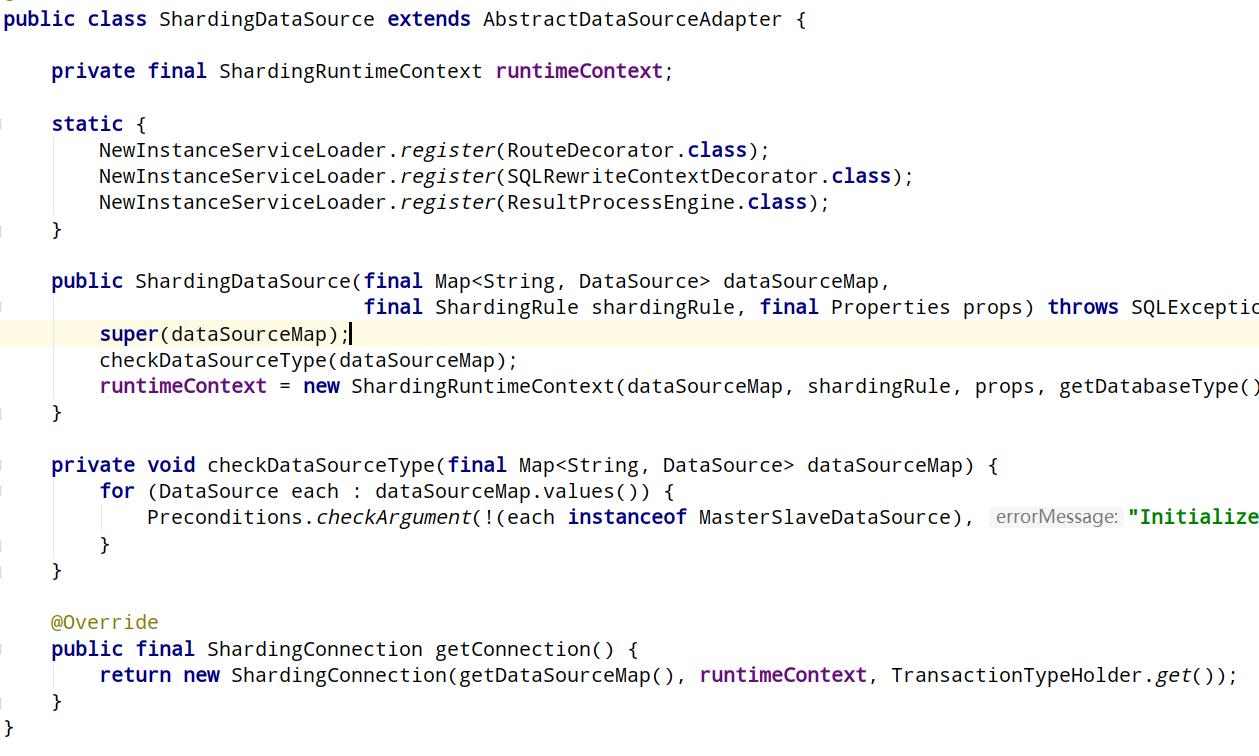
注册了路由,sql改写,结果集处理器,会初始化对应的配置的引擎,然后初始化了sharing的运行时上下文shardingRuntimeContext
shardingRuntimeContext里边主要是缓存了datasourceMetaData,以及初始化了sharding的事务引擎信息。
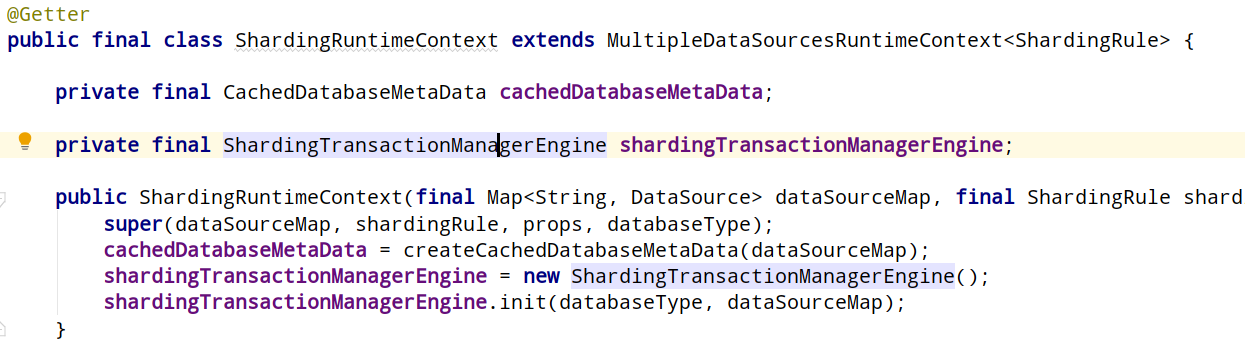
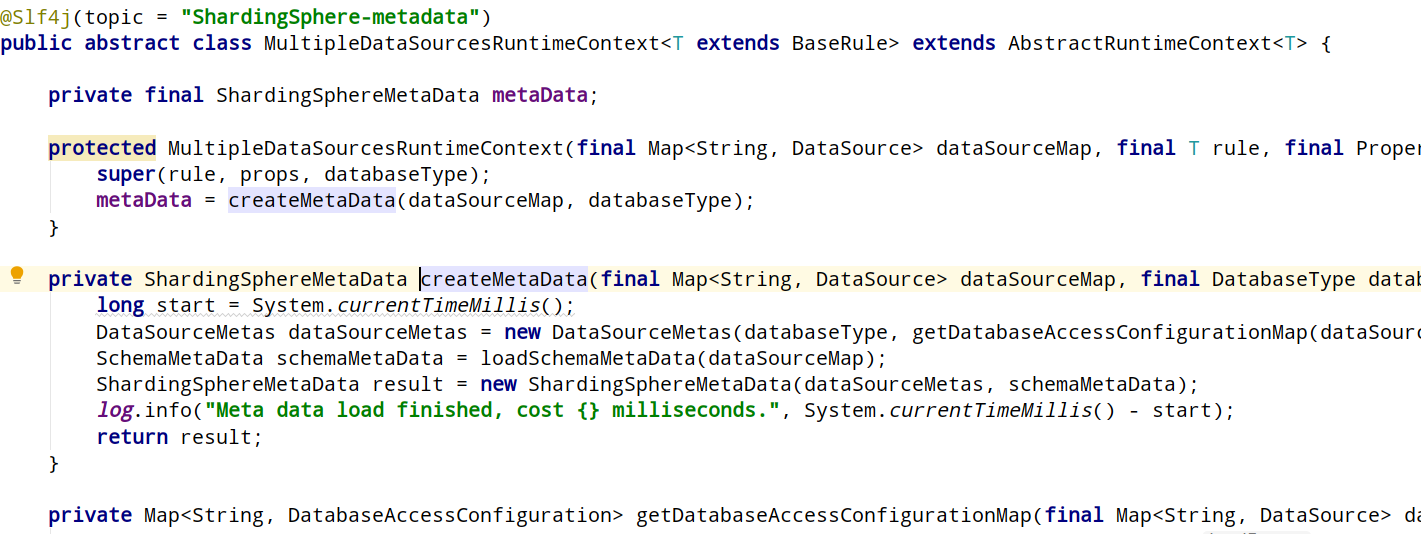
他的顶级父类是个抽象类,有多数据源和单数据源两种实现,这里使用到了多数据源实现
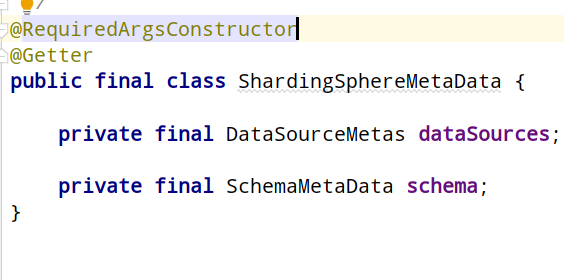
shardingSphereMetaData里边主要是数据源信息和库信息
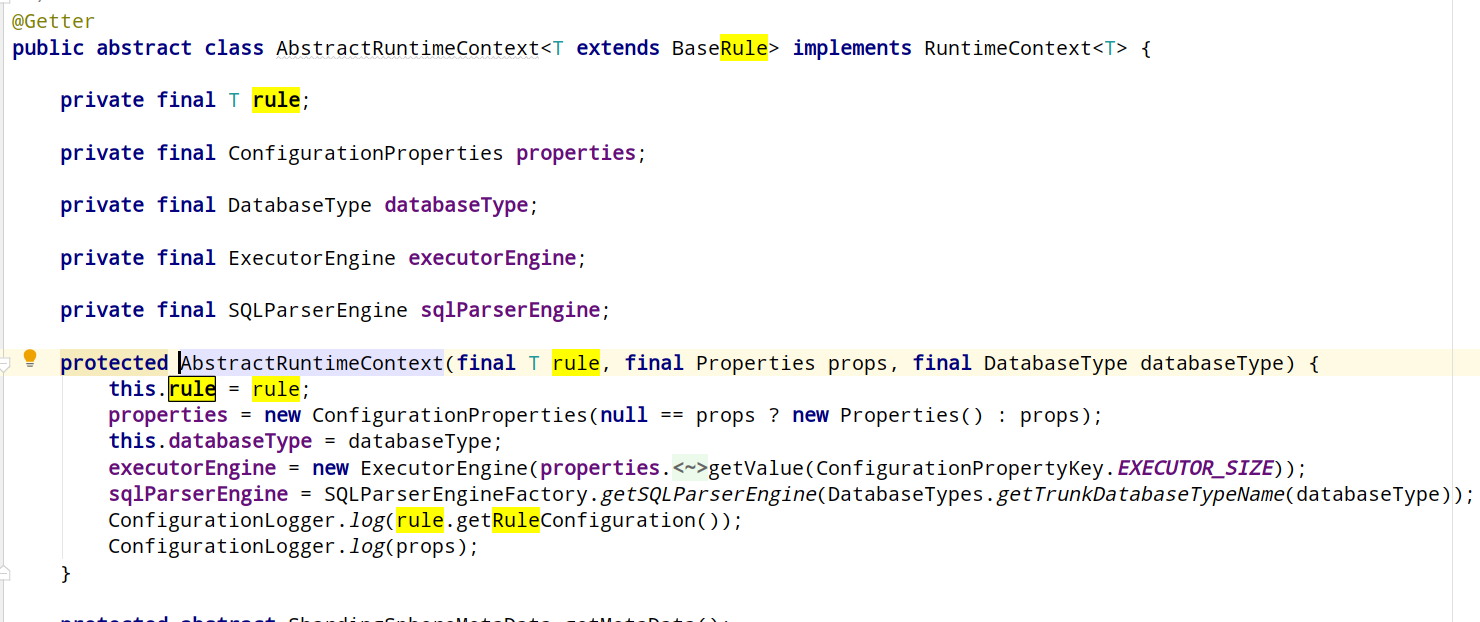
这里会初始化执行引擎和sqlparser引擎。
sharding-jdbc在执行insert语句调用时的流程
本项目使用的orm框架为mybatis,在mybatis的PreparedStatementHandler执行sql时,会调用PreparedStatement这个接口的excute()方法,这时,会调用到实现类ShardingPreparedStatement对PreparedStatement这个接口的具体实现(具体实现类的生成则是由AbstractShardingPreparedStatementAdapter来适配的)
ShardingPreparedStatement执行写的一个方法:
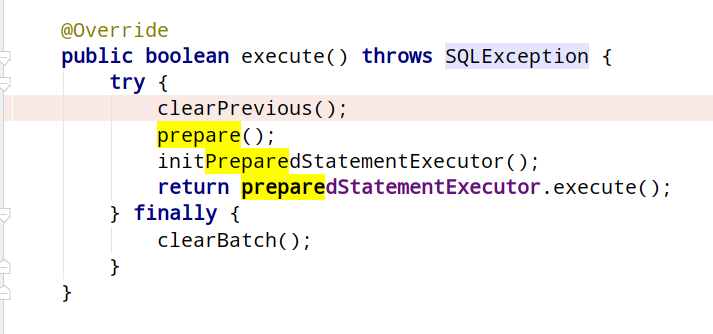
先清理干净prepareStatementExcutor,然后调用
BasePrepareEngine.prepare,根据路由规则来解析sql的逻辑表,以及参数信息,得到该路由映射的真实的库表信息,然后改写sql,然后初始化prepareStatementExcutor,执行prepareStatementExcutor的excute,操作数据库,返回结果集,然后清理结果集对象。
如果是查询操作
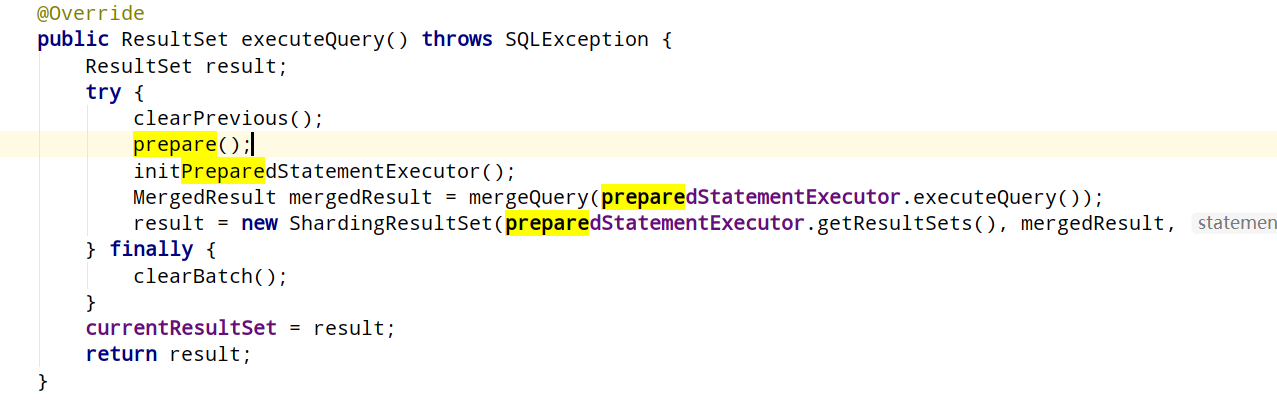
会多一步归并结果集的操作。
这个项目只是提供了简单的整合demo,有兴趣深入的可以跟下源码,或者根据业务场景来拓展其他使用。
springboot项目地址:https://github.com/yangzhouhu/shardingsphere-springboot 用得着的话点个star啊
另一篇基于sharding-proxy和sharding-scaling不停服数据迁移可以看这里:https://blog.youkuaiyun.com/HTslide/article/details/108258562

















 3050
3050




 到【灌水乐园】发言
到【灌水乐园】发言







