







 本文介绍了集成学习中的两种决策树方法:随机森林和梯度提升回归树。随机森林通过自助采样和特征子集选择减少过拟合,而梯度提升回归树通过连续构造弱树并逐步纠正错误来提高性能。随机森林在高维稀疏数据上表现不佳,而梯度提升树因其预剪枝特性在内存和速度上有优势。
本文介绍了集成学习中的两种决策树方法:随机森林和梯度提升回归树。随机森林通过自助采样和特征子集选择减少过拟合,而梯度提升回归树通过连续构造弱树并逐步纠正错误来提高性能。随机森林在高维稀疏数据上表现不佳,而梯度提升树因其预剪枝特性在内存和速度上有优势。
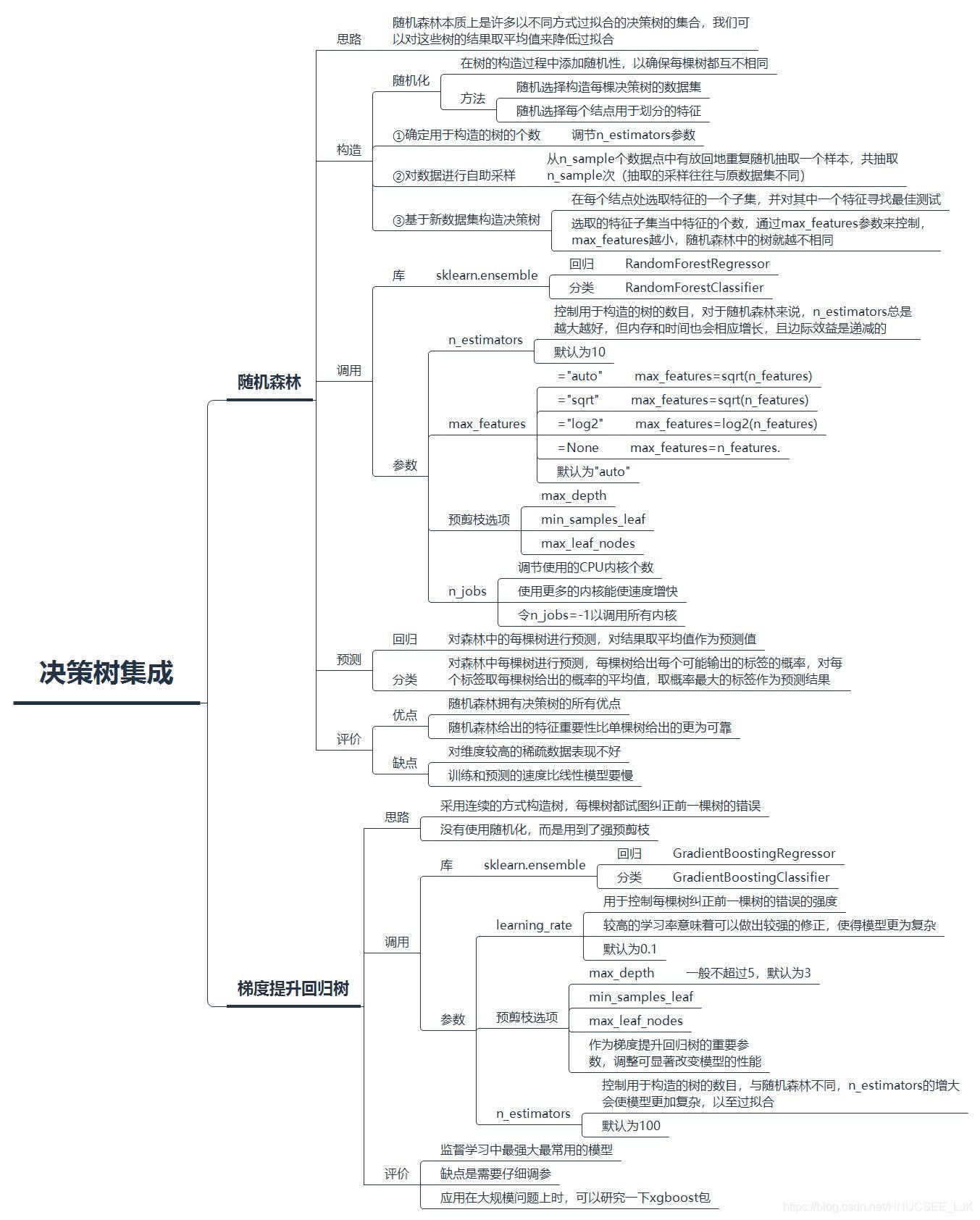
集成(ensemble)是合并多个机器学习模型来构造性能更优的模型的方法。决策树集成即是以决策树为基础的模型,主要有随机森林(random forest)与梯度提升回归树(gradient boosted decision tree, GBDT)。
随机森林
随机森林本质上是许多以不同方式过拟合的决策树的集合,我们可以对这些互不相同的树的结果取平均值来降低过拟合,这样既能减少过拟合又能保持树的预测能力。随机森林可用于回归或分类,通过sklearn.ensemble的RandomForestRegressor模块(回归)或RandomForestClassifier模块(分类)调用。
构造随机森林的步骤:
①确定用于构造的树的个数
②对数据进行自助采样
③基于新数据集构造决策树
要构造一个随机森林模型,第一步是确定森林中树的数目,通过模型的n_estimators参数进行调节。n_estimators越大越好,但占用的内存与训练和预测的时间也会相应增长,且边际效益是递减的,所以要在可承受的内存/时间内选取尽可能大的n_estimators。而在sklearn中,n_estimators默认为10。
随机森林之所以称为随机森林,是因为构造时添加了随机性,②与③正是随机性的体现。第二步是对数据进行自助采样,也就是说,从n_sample个数据点中有放回地重复随机抽取一个样本,共抽取n_sample次。新数据集的容量与原数据集相等,但抽取的采样往往与原数据集不同。注意,构建的n_estimators棵树采用的数据集都是独立自助采样的,这样才能保证所有树都互不相同。
接下来第三步就是基于这个新数据集来构造决策树。由于加入了随机性,故构造时与一般的决策树不同。构造时,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









