 近似祖先节点查找算法
近似祖先节点查找算法





 本文介绍了一种在树结构中查找两个节点最近公共祖先的算法。算法的时间限制为1000毫秒,内存限制为10000KB。输入包含多个测试案例,每个案例由树的节点数、节点之间的边以及需要查找最近公共祖先的两个节点组成。通过递归和标记的方法,算法有效地解决了这个问题。
本文介绍了一种在树结构中查找两个节点最近公共祖先的算法。算法的时间限制为1000毫秒,内存限制为10000KB。输入包含多个测试案例,每个案例由树的节点数、节点之间的边以及需要查找最近公共祖先的两个节点组成。通过递归和标记的方法,算法有效地解决了这个问题。
Nearest Common Ancestors
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 19556 | Accepted: 10363 |
Description
A rooted tree is a well-known data structure in computer science and engineering. An example is shown below:
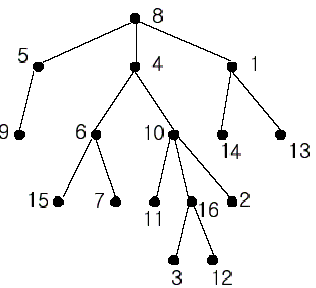
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
The input consists of T test cases. The number of test cases (T) is given in the first line of the input file. Each test case starts with a line containing an integer N , the number of nodes in a tree, 2<=N<=10,000. The nodes are labeled with integers 1, 2,..., N. Each of the next N -1 lines contains a pair of integers that represent an edge --the first integer is the parent node of the second integer. Note that a tree with N nodes has exactly N - 1 edges. The last line of each test case contains two distinct integers whose nearest common ancestor is to be computed.
Output
Print exactly one line for each test case. The line should contain the integer that is the nearest common ancestor.
Sample Input
2 16 1 14 8 5 10 16 5 9 4 6 8 4 4 10 1 13 6 15 10 11 6 7 10 2 16 3 8 1 16 12 16 7 5 2 3 3 4 3 1 1 5 3 5
Sample Output
4 3
Source
var i,j,k,m,n,x,y,s,t,l,r,u,v,ans:longint; a:array[1..10000,0..100]of longint; boo:array[1..2]of boolean; colour:array[1..10000]of boolean; f:array[1..10000]of longint; procedure find(x:longint); begin if (colour[x]=true) then begin writeln(x); exit; end; find(f[x]); end; procedure lca(x:longint); var i,j:longint; begin colour[x]:=true; if (x=u) then boo[1]:=true; if (x=v) then boo[2]:=true; if (boo[1]) and (boo[2]) then begin if (x=u) then find(v) else if (x=v) then find(u); exit; end; for i:=1 to a[x,0] do lca(a[x,i]); colour[x]:=false; end; procedure main; var i,j:longint; begin for i:=1 to m-1 do if (f[i]=0) then begin lca(i); exit; end; end; procedure init; begin readln(k); for i:=1 to k do begin fillchar(f,sizeof(f),0); fillchar(a,sizeof(a),0); fillchar(boo,sizeof(boo),false); fillchar(colour,sizeof(colour),false); readln(m); for j:=1 to m-1 do begin read(x,y); readln; inc(a[x,0]); a[x,a[x,0]]:=y; f[y]:=x; end; read(u,v); readln; main; end; end; begin init; end.

















 506
506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









