







 本文深入讲解Java集合框架,包括List、Set、Map的各种实现类,如ArrayList、LinkedList、HashSet、TreeSet、HashMap、ConcurrentHashMap等,探讨其底层数据结构、特性及应用场景。
本文深入讲解Java集合框架,包括List、Set、Map的各种实现类,如ArrayList、LinkedList、HashSet、TreeSet、HashMap、ConcurrentHashMap等,探讨其底层数据结构、特性及应用场景。
集合类存放于Java.util包中,主要有3种
set(集)、list(列表)、map(映射) 视频学习链接
先上图 ~

List、Set
- ArrayList:底层是数组。
- LinkedList:底层是双向链表。
- Vector:底层是数组,线程安全的,线程同步的,某一时刻只有一个线程能够写 Vector,所有效率较低,使用较少。
- HashSet:底层是HashMap,放到HashSet集合中的元素等同于放到HashMap集合key部分了。
- TreeSet:底层是TreeMap,放到TreeSet集合中的元素等同于放到TreeMap集合key部分了。
注:自定义的类必须实现 Comparable 接口,并且重写相应的 compareTo()方法,方法内部定义排序规则 ,才可以正常使用TreeSet。
TreeSet的add方法底层调用TreeMap的put方法:
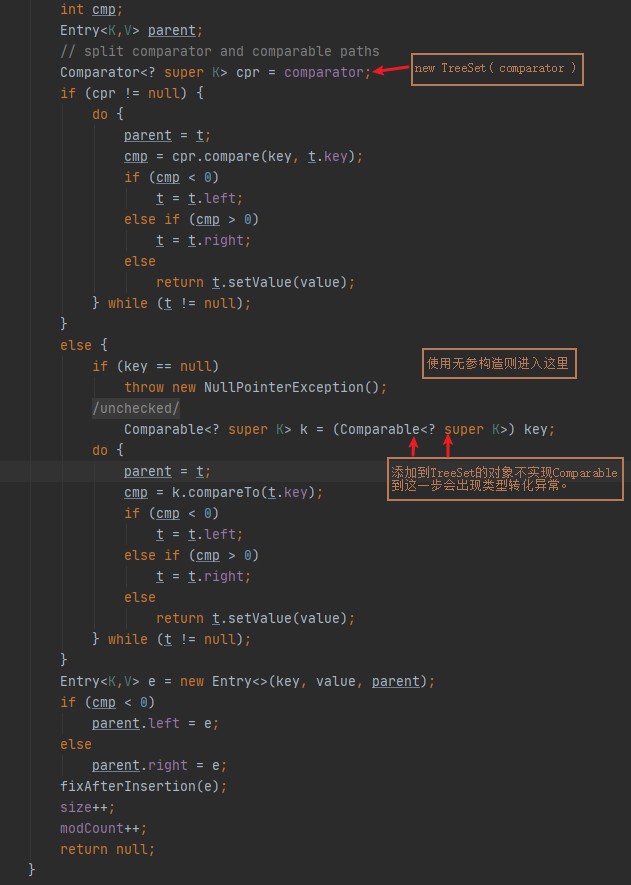
List 集合使用Collections.sort()方法进行排序。
public class Student implements Comparable<Student>{
String name;
int age;
float score;
//省略set get toString...
//k.compareTo(t.key)
//参数k是拿来与集合中每一个t.key来比较的
//如果升序 k(this)-t.key,反之。
@Override
public int compareTo(Student o) {//s1.compareTo(s2);
if (this.score == o.score){
return this.age-o.age;//年龄升序
}else return (int) (o.score-this.score);//成绩降序
}
//使用内部类创建比较器
static class StudentComparetor implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
if (o2.score == o1.score){
return o1.age-o2.age;
}return (int) (o2.score-o1.score);
}
}
}public class test {
public static void main(String[] args) {
Student liusan=new Student("liusan",20,90.0F);
Student lisi=new Student("lisi",22,90.0F);
Student wangwu=new Student("wangwu",20,99.0F);
Student sunliu=new Student("sunliu",22,100.0F);
List<Student> l=new ArrayList();
l.add(liusan);
l.add(wangwu);
l.add(lisi);
l.add(sunliu);
Collections.sort(l);
//内部类创建一个比较器类,排序时new一个比较器对象
// Collections.sort(l,new Student.StudentComparetor());
for (Student s:l
) {
System.out.println(s);
}
}
}Map

- HashMap:底层是哈希表。
- Hashtable:底层也是哈希表,只不过线程安全的,效率较低,使用较少。
- Properties:是线程安全的,并且key和value只能存储字符串String。
- TreeMap:底层是二叉树。TreeMap集合的key可以自动按照大小顺序排序。

ConcurrentHashMap
-
Segment段:
整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。 -
线程安全(Segment 继承 ReentrantLock 加锁)
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。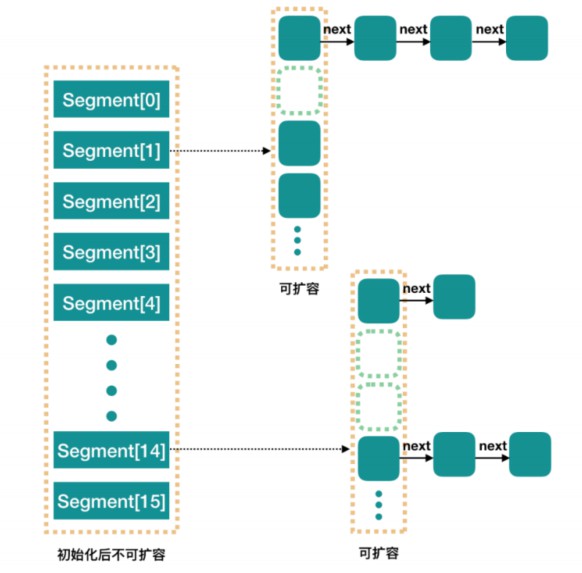
-
并行度(默认 16)
concurrencyLevel:并行级别、并发数、Segment 数。ConcurrentHashMap 默认有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
遍历集合的几种方式
1.使用foreach2.迭代器Iterator
Iterator<String> it=list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}3.通过map的keySet()获得key的set集合再迭代通过map.get(key)获得value4.使用Map的静态内部类Entry
public class MapTest01 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<Integer, String>();
map.put(1, "张三丰");
map.put(2, "周芷若");
map.put(3, "汪峰");
map.put(4, "灭绝师太");
Set<Map.Entry<Integer,String>> node=map.entrySet();
for (Map.Entry<Integer,String> data:node
) {
System.out.println(data);//得到 key=value
System.out.println(data.getKey()+"---->"+data.getValue());
}
}[刚学Java时记录的笔记,如有侵权请联系]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









