





摘要
在今日的信息洪流中,推荐系统扮演着至关重要的角色。然而,缺乏透明度的“黑箱”特性限制了用户对推荐结果的信任。本文《Personalized Prompt Learning for Explainable Recommendation》提出了一种新颖的个性化提示学习方法,旨在提高推荐系统的可解释性,通过生成自然语言解释来增强用户对推荐结果的理解。
1. 相关工作
1.1 可解释推荐
可解释推荐领域主要分为两大研究方向:人机交互和机器学习。前者关注用户对解释的感知,后者致力于设计算法以提供解释。本研究聚焦于后者,尤其是如何利用自然语言生成技术来自动生成解释。
1.2 Transformer与预训练模型
Transformer模型因其在自然语言处理任务中的卓越性能而受到广泛关注。预训练模型,如BERT和GPT系列,通过在大规模文本数据上的预训练,积累了丰富的语言知识。然而,如何将这些模型应用于推荐系统的解释生成,仍是一个未被充分探索的领域。
2. 方法
2.1 模型架构
本文提出的PEPLER模型包含两种提示学习方法:离散提示学习(Discrete Prompt Learning)和连续提示学习(Continuous Prompt Learning)。这两种方法都旨在将用户和物品ID融合到预训练模型中,以生成解释。
2.1.1 离散提示学习
离散提示学习通过将ID映射为与推荐项目相关的特征词(如“房间”、“位置”),这些特征词作为提示输入到预训练模型中。
2.1.2 连续提示学习
连续提示学习则直接将用户和物品的ID向量作为输入,这些向量与解释词向量一起通过预训练模型。
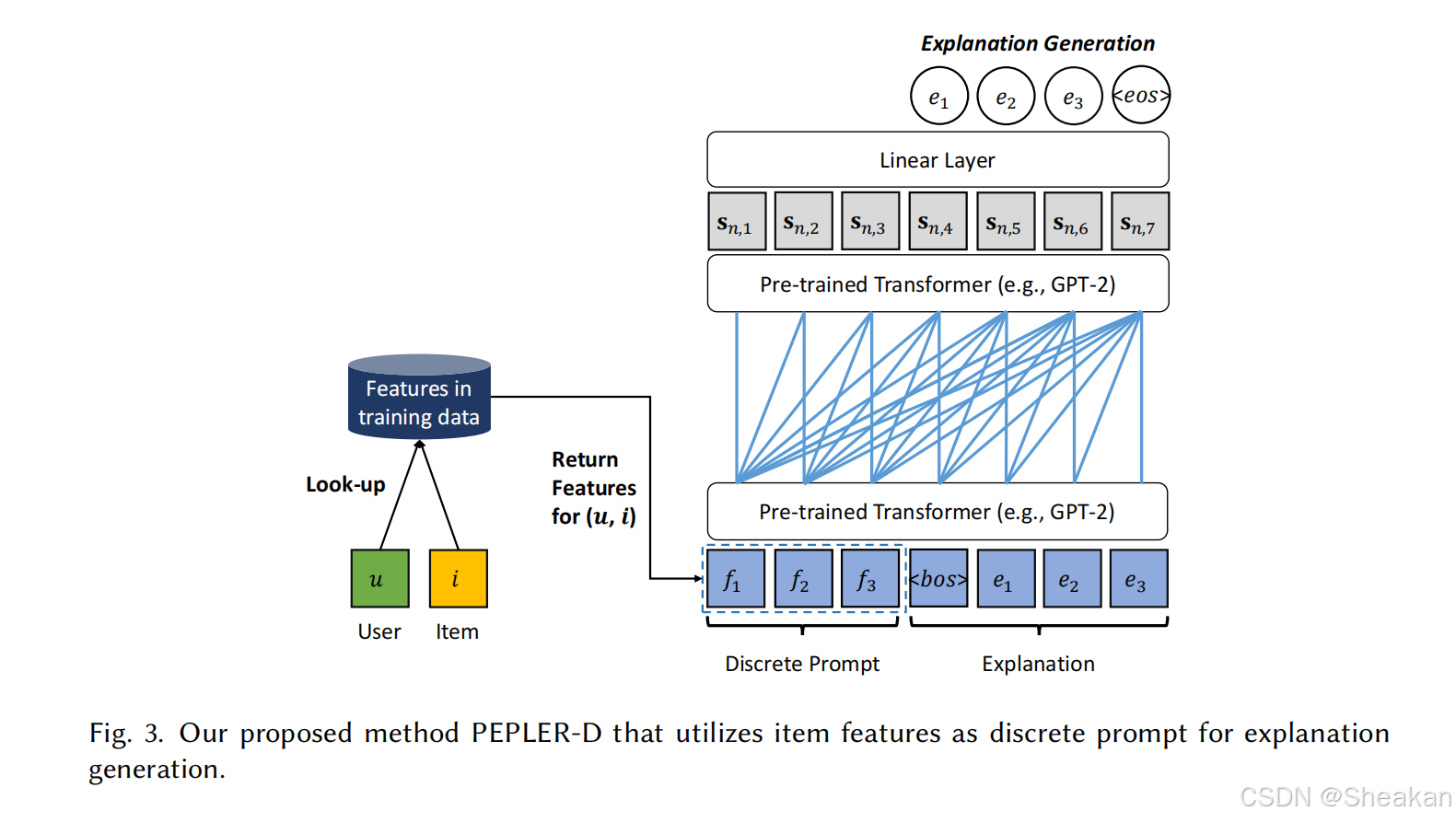
2.2 创新点
- 个性化提示:首次将提示学习应用于推荐系统的可解释性问题。
- 训练策略:提出了顺序调整和推荐作为正则化的训练策略,以缩小预训练模型与新引入参数之间的差距。
3. 实验
3.1 数据集
实验使用了三个公开的可解释推荐数据集:TripAdvisor、Amazon和Yelp。
3.2 评估指标
评估指标包括BLEU、ROUGE、USR、FMR、FCR和DIV,旨在全面评估生成解释的文本质量和可解释性。
3.3 实验结果
实验结果表明,PEPLER在所有指标上均优于现有方法,特别是在文本质量和特征覆盖率方面。
4. 结论与未来工作
本文提出的PEPLER模型有效地提高了推荐系统的可解释性。未来的工作将探索多模态数据的融合以及跨语言解释生成。

















 3720
3720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









