




论文信息
- 标题:Instructing and Prompting Large Language Models for Explainable Cross-domain Recommendations
- 期刊:18th ACM Conference on Recommender Systems (RecSys ’24)
- 年份:2024
- 关键词:#CrossDomainRecommendations #RecommenderSystems #LargeLanguageModels #InstructionTuning
🌟 研究背景
在信息爆炸的时代,推荐系统成为了我们日常生活中不可或缺的一部分,帮助我们筛选出感兴趣的内容。特别是跨领域推荐系统(CDR),它们能够在不同的领域之间进行知识迁移,为用户提供更加个性化的推荐。
💡 创新点
这篇论文的最大亮点在于利用大型语言模型(LLMs)来提供可解释的跨领域推荐。作者提出了一种全新的策略,通过指导LLM处理CDR任务、设计个性化提示,以及在零样本和单样本设置中提取推荐和自然语言解释,从而解决了数据稀疏性问题。
🔍 方法介绍
研究者们设计了一个包含四个阶段的流程:
- 数据预处理:准备适合LLM处理的数据。
- 指令调整:通过部分数据训练模型,使其能够处理CDR任务。
- 提示LLMs进行CDR:构建基于用户偏好的个性化提示,让LLM生成推荐。
- 输出细化和推荐:处理LLM的输出,提取建议列表和解释。
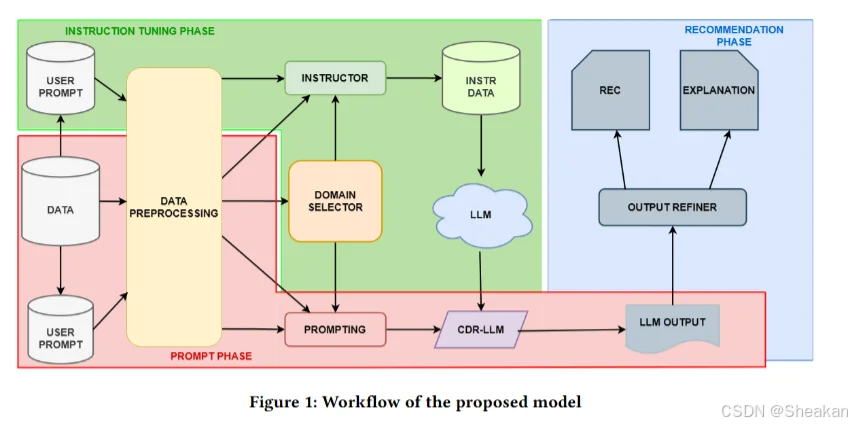
方法的详细步骤:
a. 数据预处理(Data Pre-Processing)
- 用户和物品集的划分:首先,将用户分为两个不相交的子集,一个用于指令调整(instruction tuning),另一个用于提示阶段(prompting phase)。这样做是为了防止信息泄露,确保模型评估的公正性。
- 构建偏好集合:对于每个用户,构建他们在源领域喜欢(positive preferences)和不喜欢(negative preferences)的物品集合,以及目标领域中待排名的物品集合。
- 获取物品描述性特征:收集每个物品的描述性特征,如类型、作者等。
b. 指令调整(Instruction Tuning)
- 适应性提示设计:设计一个由三部分组成的提示:系统提示(System Prompt)、用户提示(User Prompt)和模型输出(Model Output)。
- 系统提示:提供关于CDR任务和领域的一般指导。
- 用户提示:详细描述用户在源领域的交互历史,包括喜欢和不喜欢的物品及其特征,以及目标领域中候选物品的特征。
- 模型输出:指定LLM预期的输出格式,即基于用户偏好重新排名的目标领域物品列表和解释。
- 模型微调:使用这些适应性提示来微调LLM,使其适应CDR任务。
c. 提示LLMs进行CDR(Prompting LLMs for CDR)
- 选择领域:为每个用户选择一个源领域和一个目标领域。
- 构建个性化提示:根据用户的偏好集合和物品特征,构建一个个性化的提示,但不包括模型输出部分,因为这部分将由模型生成。
- 零样本和单样本设置:实验中考虑了零样本(zero-shot)和单样本(one-shot)设置,以评估LLMs在不同设置下的表现。
d. 输出细化和推荐(Output Refinement and Recommendation)
- 处理LLM输出:分析LLM返回的物品ID,过滤掉不存在的物品(hallucinations),并按照LLM返回的顺序生成最终推荐列表。
- 提取解释:从LLM的回答中提取自然语言解释,这部分文本通常位于“Explanation:”之后。
e.创新点
- 利用LLMs的知识转移能力:LLMs在大量文本数据上训练,能够学习复杂的模式和关系,这使得它们能够在不同的领域之间转移知识。
- 生成自然语言解释:LLMs能够生成解释推荐决策的自然语言文本,增加了推荐的透明度和可解释性。
- 适应性提示和指令调整:通过设计特定的提示和对LLMs进行指令调整,使得模型能够更好地理解和执行CDR任务。
📊 数据集
研究者们使用了Amazon dataset,包括“Movies”、“CDs”和“Books”三个数据集,这些数据集具有跨多个领域的重叠用户,非常适合CDR研究。

















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









