






 本文介绍了Pandas的DataFrame操作,包括转置(T)、数据类型(dtypes)检查、是否为空(empty)、维度(ndim)、形状(shape)、元素数量(size)、Numpy表示(values)以及head/tail方法。还讨论了如何读取文件为DataFrame,如使用pd.read_csv(),以及如何过滤和处理NaN值,包括isnull、notnull和fillna方法。
本文介绍了Pandas的DataFrame操作,包括转置(T)、数据类型(dtypes)检查、是否为空(empty)、维度(ndim)、形状(shape)、元素数量(size)、Numpy表示(values)以及head/tail方法。还讨论了如何读取文件为DataFrame,如使用pd.read_csv(),以及如何过滤和处理NaN值,包括isnull、notnull和fillna方法。
Pandas基本功能
上一篇,我们对pandas数据结构Series和DataFrame做了简要介绍。这次我们将对pandas的一些基本功能做一些介绍
首先导入必要的包:
import pandas as pd
import numpy as np
一.DataFrame基本功能
(一)T–转置
当我们想要将一个DataFrame结构转置时,可以用print(df.T)语句
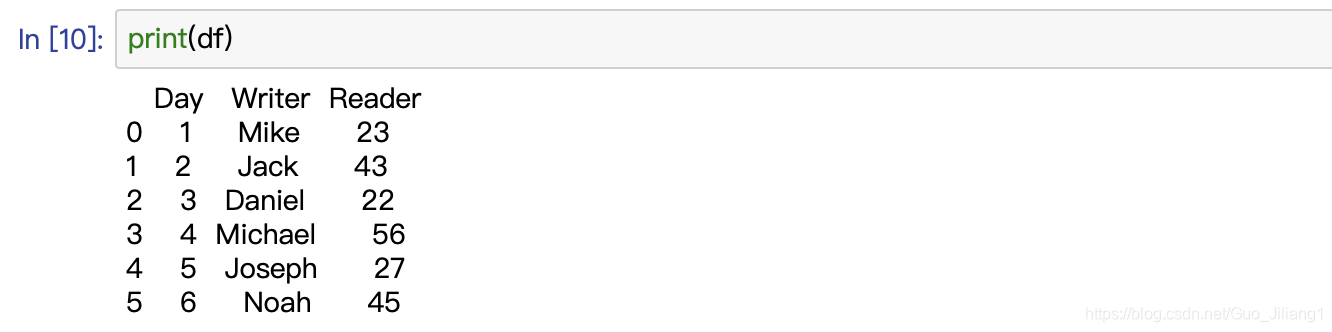
比如说我们先创建一个book_1DataFrame
book_1 = {'Day':[1,2,3,4,5,6],
'Writer':["Mike","Jack","Daniel","Michael","Joseph","Noah"],
'Reader':[23,43,22,56,27,45]}
df = pd.DataFrame(book_1)
print(df)
我们运行查看这个数据框架:
当我们要转置时:

(二)dtypes–返回此对象中的数据类型
一个数据框架中的元素有很多数据类型,如果我们要查看一组元素的数据类型,则直接用dtypes语句:
book_1 = {'Day':[1,2,3,4,5,6],
'Writer':["Mike","Jack","Daniel","Michael","Joseph","Noah"],
'Reader':[23,43,22,56,27,45]}
df = pd.DataFrame(book_1)

(三)empty–返回布尔值,表示对象是否为空; 返回True表示对象为空
book_1 = {'Day':[1,2,3,4,5,6],
'Writer':["Mike","Jack","Daniel","Michael","Joseph","Noah"],
'Reader':[23,43,22,56,27,45]}
df = pd.DataFrame(book_1)
print(df.empty)
因为此数据中元素不为空,则输出为False。

(四)ndim–轴/数组维度大小
当我们要查看此数据的维度时,则用ndim命令
book_1 = {'Day':[1,2,3,4,5,6],
'Writer':["Mike","Jack","Daniel","Michael","Joseph","Noah"],
'Reader':[23,43,22,56,27,45]}
df = pd.DataFrame(book_1)

(五)shape–返回DataFrame维度的元组
book_1 = {'Day':[1,2,3,4,5,6],
'Writer':["Mike","Jack","Daniel","Michael","Joseph","Noah"],
'Reader':[23,43,22,56,27,45]}
df = pd.DataFrame(book_1)
print(df)
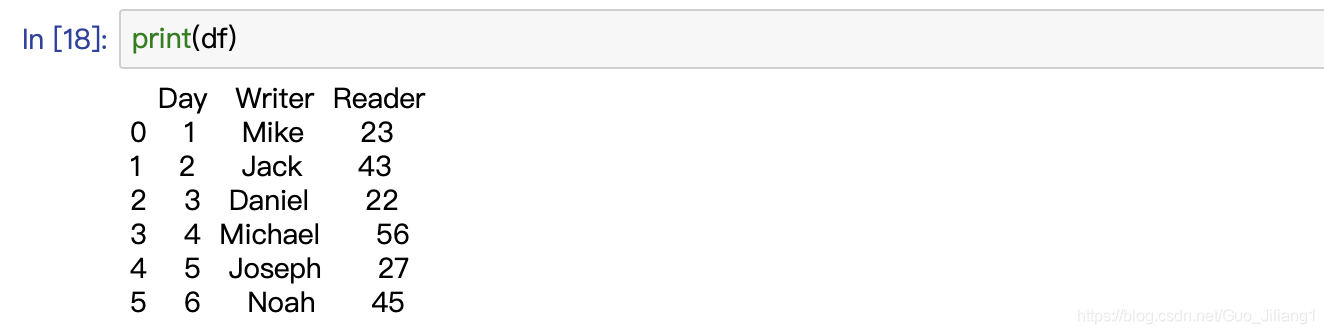

(六)size–返回DataFrame中的元素数
book_1 = {'Day':[1,2,3,4,5,6],
'Writer':["Mike","Jack","Daniel","Michael","Joseph","Noah"],
'Reader':[23,43,22,56,27,45]}
df = pd.DataFrame(book_1)
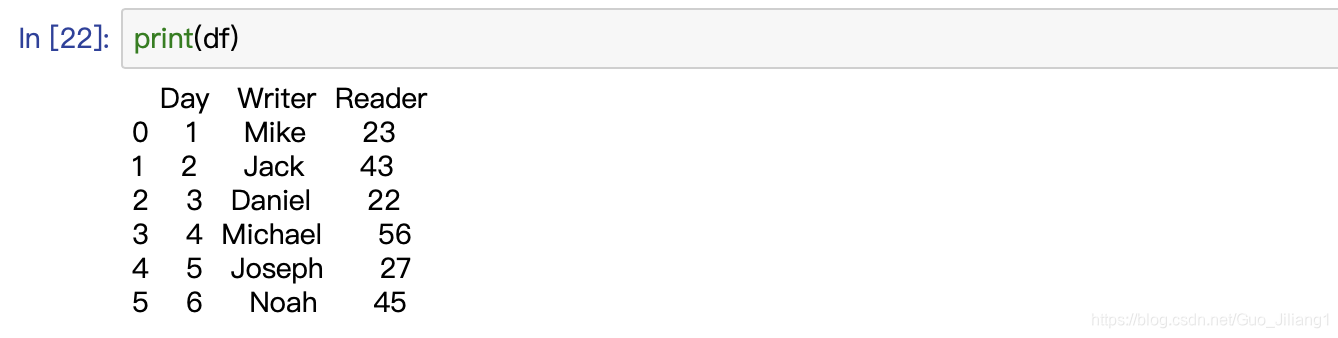

size返回一个数据框架中的元素。
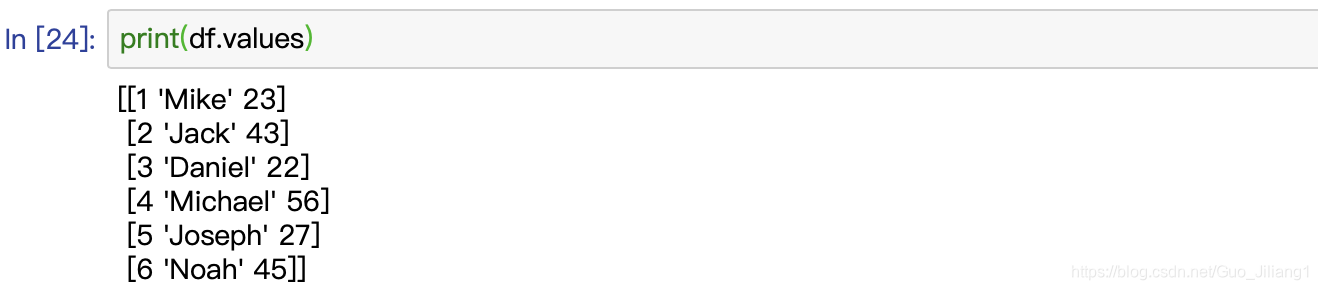
(七)values–NDFrame的Numpy表示
book_1 = {'Day':[1,2,3,4,5,6],
'Writer':["Mike","Jack","Daniel","Michael","Joseph","Noah"],
'Reader':[23,43,22,56,27,45]}
df = pd.DataFrame(book_1)
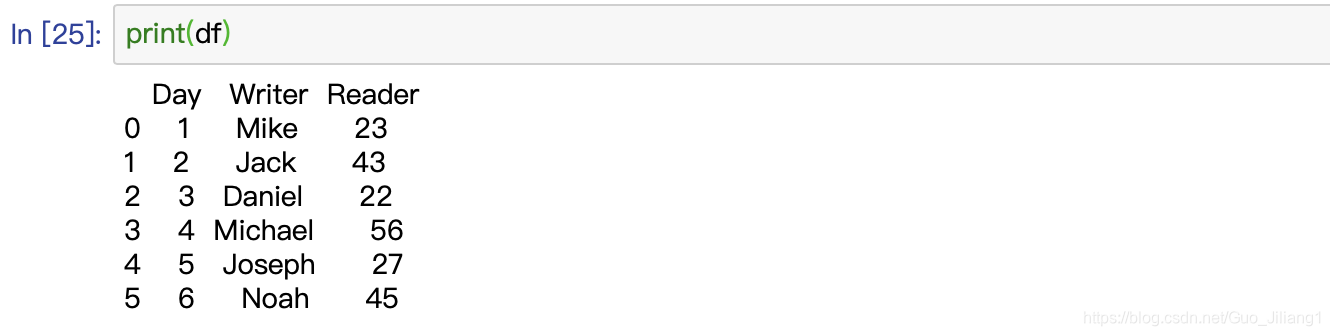
(八)head()和tail()–返回开头前n行/返回最后n行

print(df.head(2)) #返回开头2行

print(df.tail(2)) #返回最后2行

二.文件读取
pandas可以将读取到的表格型数据(文件不一定要是表格)转成DataFrame类型的数据结构,然后我们可以通过操作DataFrame进行数据分析,数据预处理以及行和列的操作等。
path1 = r'Desktop/泰迪杯/附件1-示例数据-100辆车/附件1-示例数据-100辆车/AA00001.csv'
path2 = r'Desktop/泰迪杯/附件1-示例数据-100辆车/附件1-示例数据-100辆车/AA00004.csv'
path3 = r'Desktop/泰迪杯/附件1-示例数据-100辆车/附件1-示例数据-100辆车/AA00052.csv'
path4 = r'Desktop/泰迪杯/附件1-示例数据-100辆车/附件1-示例数据-100辆车/AA00128.csv'
data1 = pd.read_csv(path1)
data2 = pd.read_csv(path2)
data3 = pd.read_csv(path3)
data4 = pd.read_csv(path4)
用pd.read_csv()以一csv格式读取文件
data3 = pd.concat([data1,data2])
data3
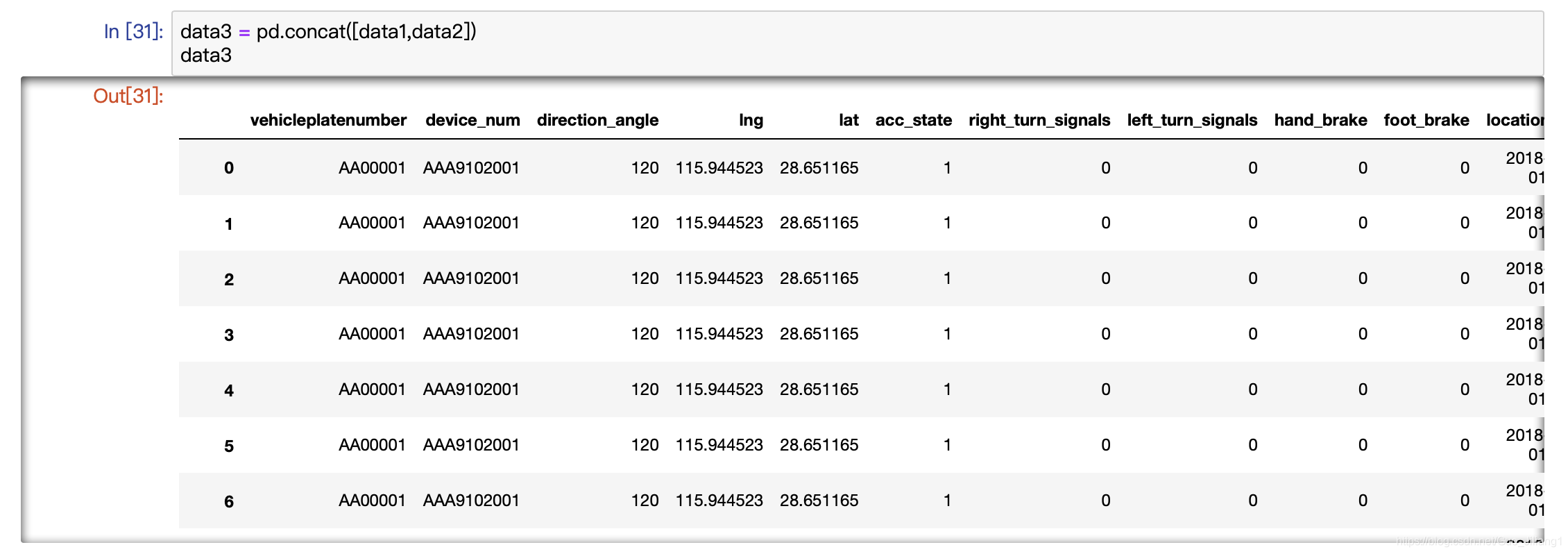
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合。
三.数据过滤
在一个数据结构中,如果我们想要补充空值或者删除数据中的NaN值,那么pandas可以帮你很好的实现
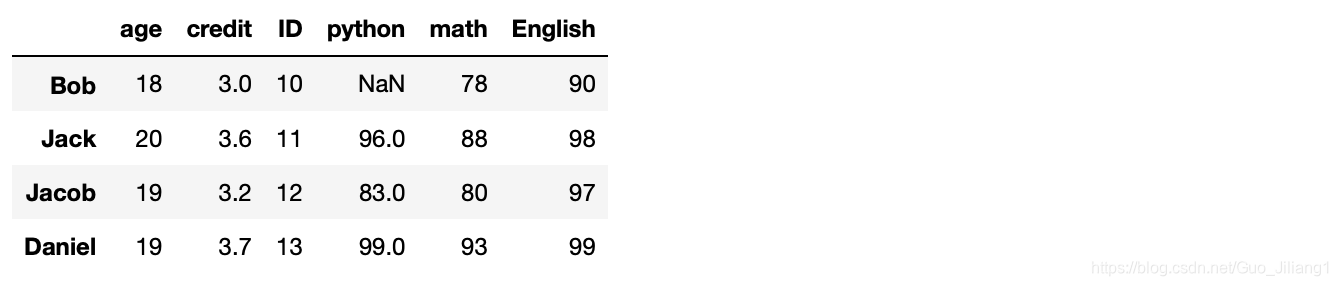
首先创造一个含有部分NaN值的学生信息的数据框架:
columns=["age","credit","ID","python","math","English"]
dit={'age':[18,20,19,19],
'credit':[3.0,3.6,3.2,3.7],
'ID':[10,11,12,13],
'python':[np.nan,96,83,99],
'math':[78,88,80,93],
'English':[90,98,97,99]}
df=pd.DataFrame(dit,index=['Bob','Jack','Jacob','Daniel'])
df
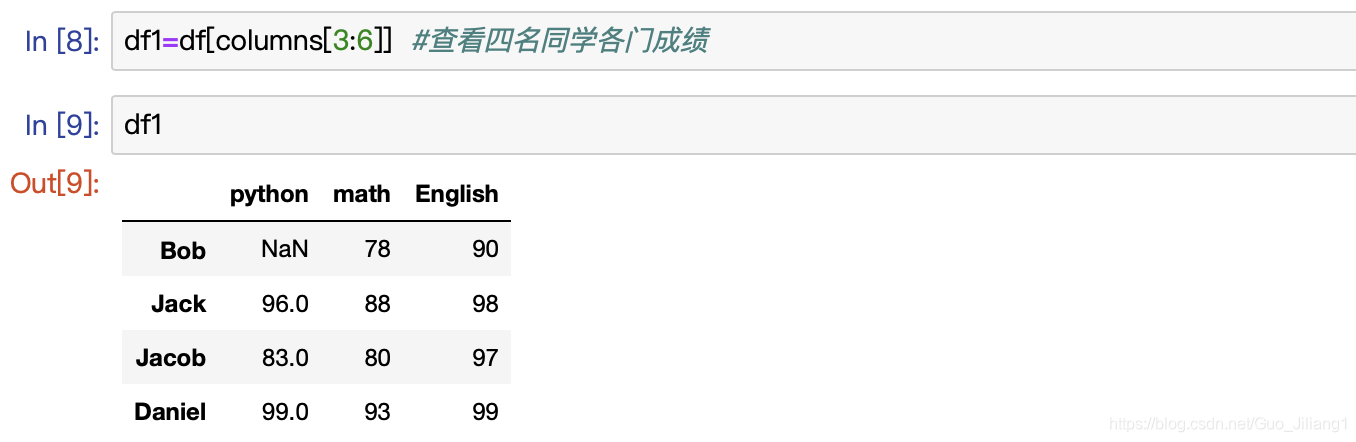
假如要查看四名同学的各门成绩,我们可以用索引来查看:
当我们不想要具有NaN值的行或列,则可以用axis
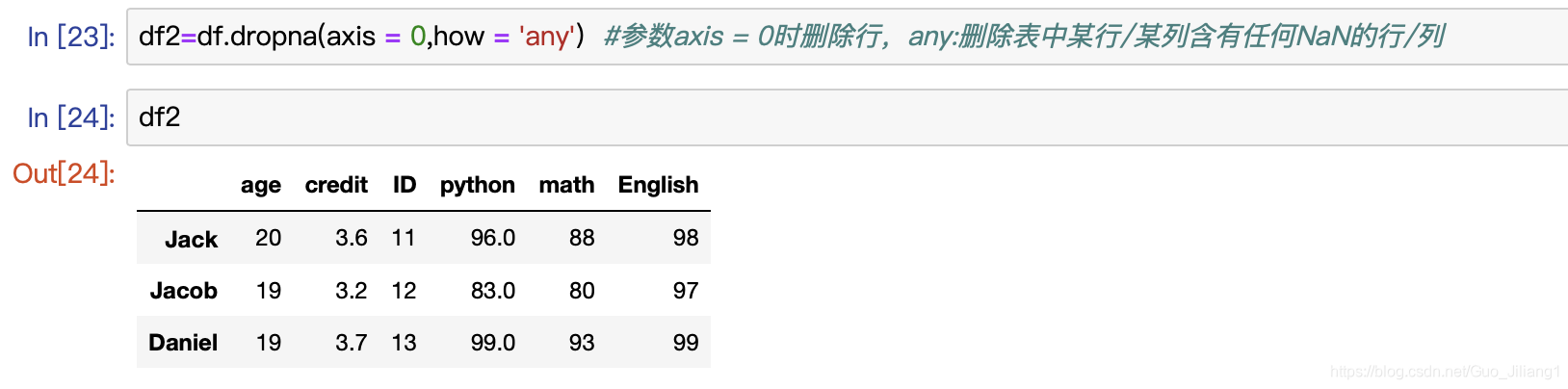
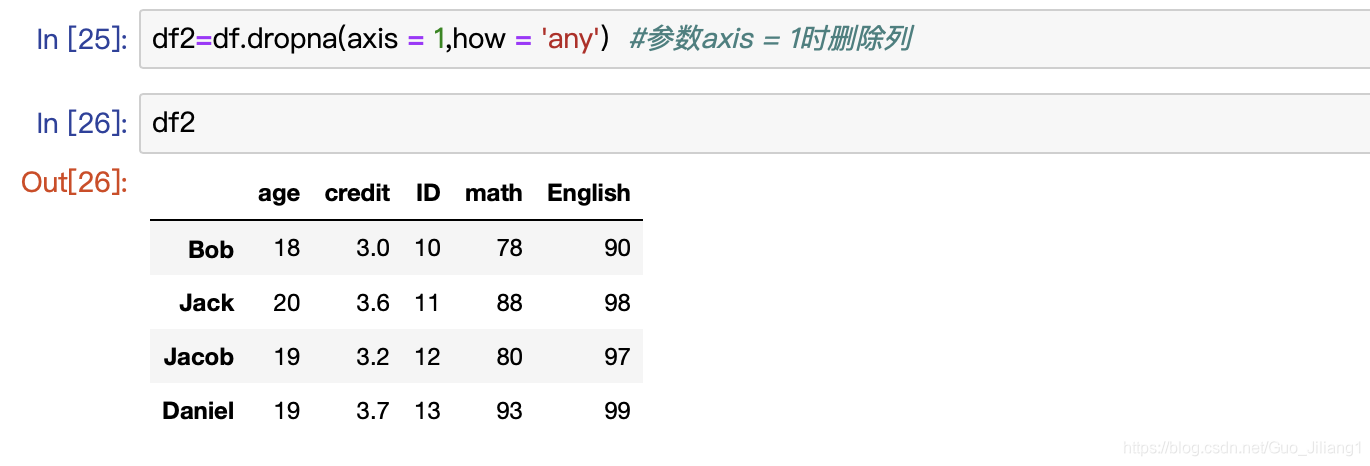
axis参数如果等于0,则删除含有空值的行;如果等于1,则删除含有空值的列。
any:删除表中某行/某列含有任何NaN的行/列
处理NaN值
columns=["age","credit","ID","python","math","English"]
dit={'age':[18,20,19,19],
'credit':[3.0,3.6,3.2,np.nan],
'ID':[10,11,12,13],
'python':[np.nan,96,83,99],
'math':[78,88,np.nan,93],
'English':[90,np.nan,97,99]}
df=pd.DataFrame(dit,index=['Bob','Jack','Jacob','Daniel'])
df
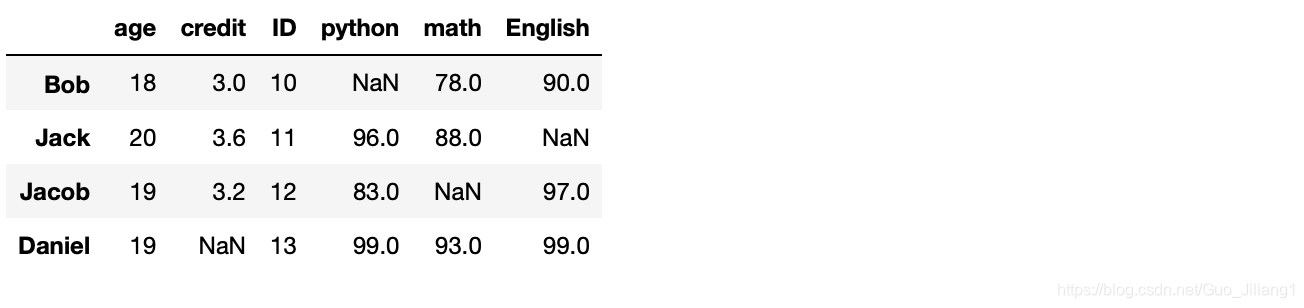
(一) isnull–将NaN的值设置为True
df.isnull()

(二) notnull–将NaN的值设置为False
df.notnull()

(三) fillna–用指定值或者插值的方式填充缺失数据
value=None, method=None, axis=None, inplace=False, limit=None
1.value 指定填充的值
2.method 指定填充方法
3.axis 指定填充值的方向
4.inplace 指的是是否对原df进行替换
5.limit 限制填充的个数
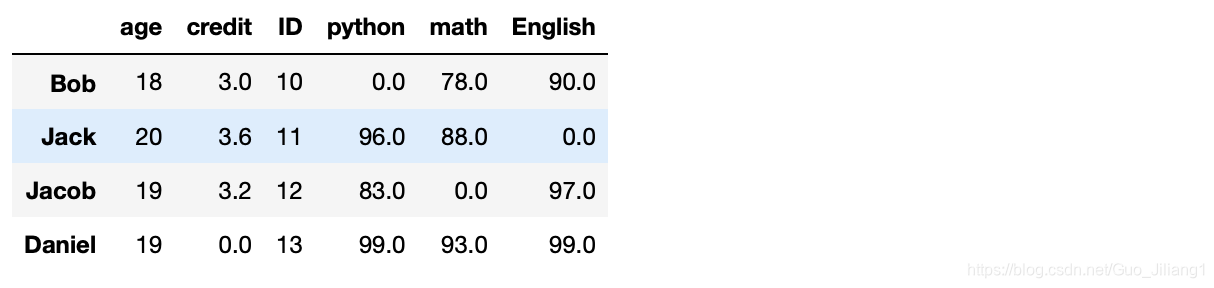
df.fillna(0) #将NaN值补充为0

















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









