




一、KNN算法
KNN算法也叫k-近邻算法,简单的说就是运用k算法采用测量不同特征值之间的距离的方法对日常生活中出现的人或物进行分类。它的算法核心思想就是:近朱者赤,近墨者黑。举个例子: 如图1.1所示假设坐标图中有3种颜色的图案,其中有一个白色的图案,要判断它应该属于哪种颜色,取决于它的坐标位置,经过计算它离红色图案的坐标位置更近,所以它最后属于红色类型。
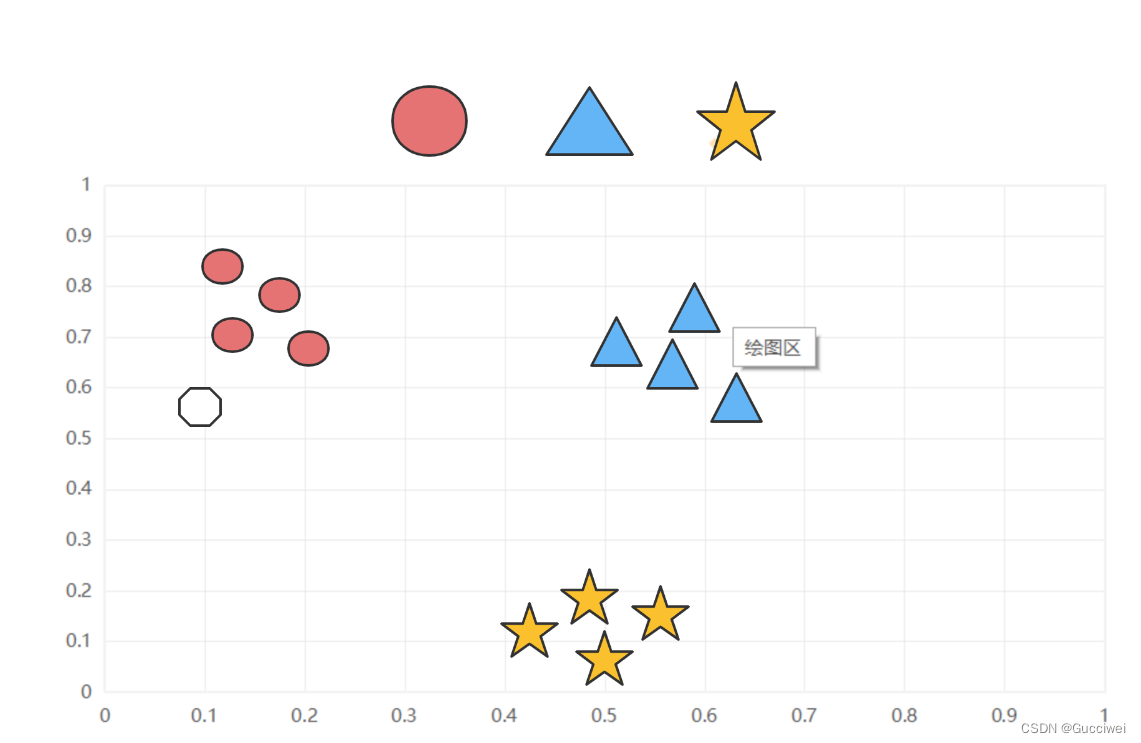
图1.1
二、K算法的一般流程
(1)收集数据:线上或者线下收集。
(2)准备数据:可以使用结构化的数据格式,比如二维坐标。
(3)分析数据:可以使用任何方法。
(4)训练算法:不需要。
(5)测试算法:计算错误率。
(6)使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
三、距离的计算
欧式距离:计算两点A、B之间的距离:
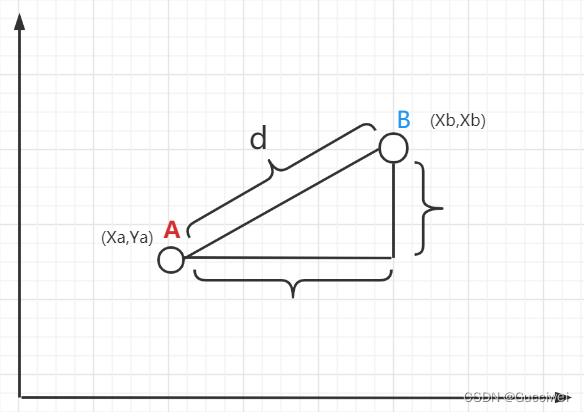
四、K值的确定
K近邻算法中的K是什么意思呢?
K近邻,是k个最近的邻居,也就是每个样本都可以用它最接近的k个邻居来代表。
K:临接近的数,在预测目标点时取几个临近的点来预测。
K值的确定:
(1)当K的取值过小时,会出现偏差,容易发生过拟合;
(2)当K的值取过大时,就相当于用较大邻域中的训练实例进行预测,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2753
2753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









