




 本文通过实例演示如何使用Scrapy爬取新浪股市评论的评论内容、时间及作者。介绍了创建spider项目、配置文件、编写爬虫代码等步骤,并提醒读者了解正则表达式或使用XPath辅助工具。最后,展示了运行结果和数据存储。
本文通过实例演示如何使用Scrapy爬取新浪股市评论的评论内容、时间及作者。介绍了创建spider项目、配置文件、编写爬虫代码等步骤,并提醒读者了解正则表达式或使用XPath辅助工具。最后,展示了运行结果和数据存储。
Scrapy爬取小实战——以新浪股市为例
前言
- 相信大家已经在优快云上找到了很多讲解scrapy爬虫原理、详解balabala…的一大堆,所以这里我就不去对scrapy的原理做什么讲解,就只是用代码与注释来告诉大家要如何操作scrapy写一个爬虫小应用。
第一部分:看看网站
- 这次案例我们要爬新浪股市某一条评论里面的三个内容:评论内容、时间、作者。
- 我随机打开一个评论:
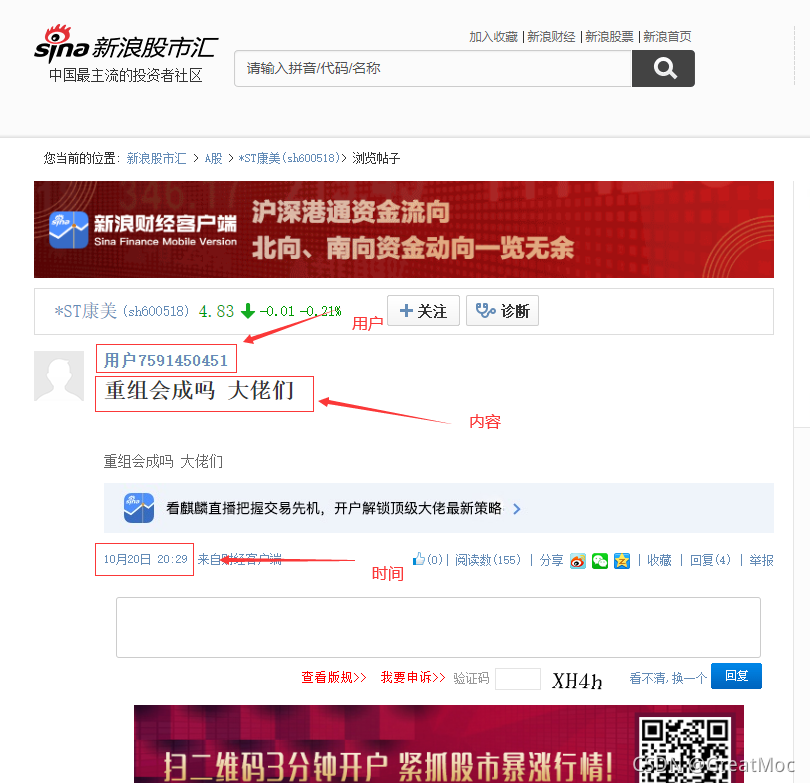
- 可以看到要爬的就是框起来的三个内容,通过F12我们可以看到它详细的html代码,这里我就不打开看了。
- 因为我们后面爬取要涉及到正则表达式,所以建议大家要学会如何使用正则表达式来找信息,如果大家不会的话也可以下载chrome的xpath插件,查看每一部分的正则表达式代码。
这里附上链接:Xpath-helper插件下载戳这里!!!!.
第二部分:创建一个spider项目
- 首先,在你想要创建项目的目录下打开cmd并进入python环境:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4307
4307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









