






引言

近日,广东肇庆怀集县遭遇百年一遇的特大洪水。据微信公众号“怀集发布”6月18日下午消息,据初步统计,截至6月18日7时,在暴雨肆虐下,19个乡镇、18.3万群众受灾,近900公顷农田被淹,直接经济损失超4000万元。这场灾害不仅冲毁了道路、房屋和基础设施,更对当地的农业生产造成了沉重打击——被洪水浸泡的土壤、倒伏的庄稼、损毁的灌溉系统,无一不在提醒我们:极端降水正深刻改变着农田的生产潜力。
农田生产潜力是国家粮食安全的根基,直接决定我们能种出多少粮食,养活多少人。如今,随着城市化扩张、气候变化加剧,农田资源越来越紧张,农田生产潜力也受到环境因素和人为因素的双重影响,例如上文提到的极端降水、农田性质、施肥量等因素。
如何排除其他变量的影响,只研究单个变量对结果的影响一直是摆在研究者面前的难题。在今天的文章中,我们将介绍如何使用因果推断分析这一最新的分析方法,来探究降水与农田生产潜力之间的因果关系。
01 因果推断分析原理与应用
PART.1 什么是因果推断分析?
因果推断分析(Causal Inference)是统计学和计量经济学中的一个重要领域,旨在从观察数据中识别变量之间的因果关系,而不仅仅是相关性。
具体来说,分析过程是对两个感兴趣变量之间的因果关系进行建模,探究变量A(称为暴露变量/处理变量)是否会直接更改或影响另一个变量B(称为结果变量)?
PART.2 因果推断分析的应用场景?

因果推断分析在我们的现实生活的方方面面都有广泛的应用,例如:
-
医学与公共卫生领域:评估药物疗效、疾病风险因素分析、公共卫生政策效果评估等
-
经济学与政策评估领域:政策干预效果、教育回报、劳动力市场分析等
-
社会科学领域:社会干预效果、犯罪学研究等
-
市场营销与商业决策领域:广告效果评估、定价策略、用户行为分析等
-
农业领域:农业技术效果评估(如不同施肥量对作物产量的影响?)、农业市场与供应链分析等
-
交通领域:单行道修建对城市交通拥挤度的影响?
-
环保领域:煤炭消耗量与城市PM2.5污染之间的关系?气候变化政策评估、污染治理效果等
-
自然资源领域:稀土资源开采量与GDP之间的关系?
PART.3 因果推断分析与相关性分析的区别?
在统计学中,我们经常使用相关性这个概念。那么,相关性能否等同于因果性?在回答这个问题之前,我们先来看下面这个统计学中经典例子。
冰淇淋销量上升导致溺亡人数上升?
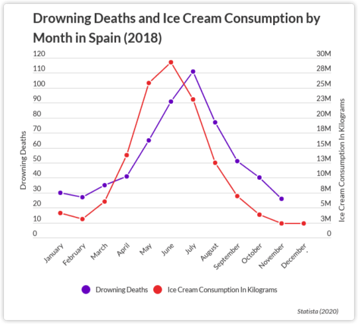
在上图中,红色曲线表示2018年1月至12月西班牙冰淇淋销量,蓝色曲线表示2018年1月至12月西班牙溺亡人数。比较图中的两个曲线,可以看到冰淇淋销量与溺亡人数之间,存在时序滞后的相关关系,那这个例子能够说明是冰淇淋销量的上升导致了溺亡数量的上升吗?
从逻辑上,我们可以判断两者不存在直接的因果关系。实际上两者的相关性是因为存在公共的因子“气温”所导致的,气温升高导致了冰淇淋销量的上升,气温升高导致了游泳人数的变多,进而导致了溺亡人数的增多。因此,如果希望通过控制冰淇淋销售,来降低溺亡人数是很荒谬的决策。
通过这个例子我们可以看出,相关性比因果性更缺乏可解释性。因果推断分析中的重要步骤就是剔除混杂变量的影响,只探究暴露变量对结果变量的直接影响,也就是因果关系。
02 GeoScene Pro中的因果推断分析
PART.1 初步探究暴露变量和结果变量之间的关系
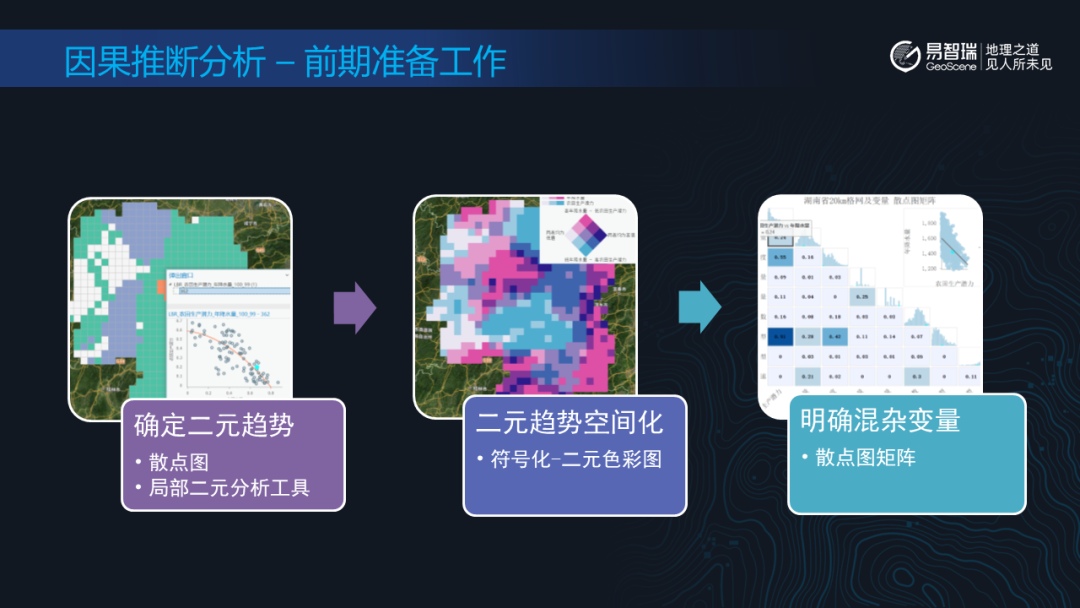
在GeoScene Pro进行因果推断分析之前,需要首先确定暴露变量和结果变量,以及参与分析的混杂变量。
GeoScene Pro 提供了一系列工具帮助用户对选定的暴露变量和结果变量之间的二元趋势进行二元可视化与空间化分析,并提供散点图矩阵工具用于明确混杂变量。
PART.2 GeoScene Pro 中的因果推断分析

接下来即可使用GeoScene Pro 5.1 新推出因果推断分析工具,通过平衡混杂变量来估计连续暴露变量和连续结果变量之间的因果效应。
工具使用倾向得分匹配或者逆倾向得分加权算法为每个观测值分配权重,使混杂变量与暴露变量变得不相关,从而隔离暴露与结果之间的因果效应。
工具运行后将生成暴露响应函数(ERF,Exposure-Response Function),可用于估计结果变量如何响应暴露变量的变化。
03 分析案例:探究降水量和农田生产潜力之间的因果关系

接下来,我们以湖南省为例,使用GeoScene Pro 5.1软件探究该省降水量与农田生产潜力之间的因果关系,具体分析步骤分为以下几步:
数据准备
确定二元趋势及明确混杂变量
因果推断分析
结果解读
基于因果关系的预测
PART.1 数据准备
以湖南省为例,首先创建分辨率为20km的格网,细化分析的尺度。
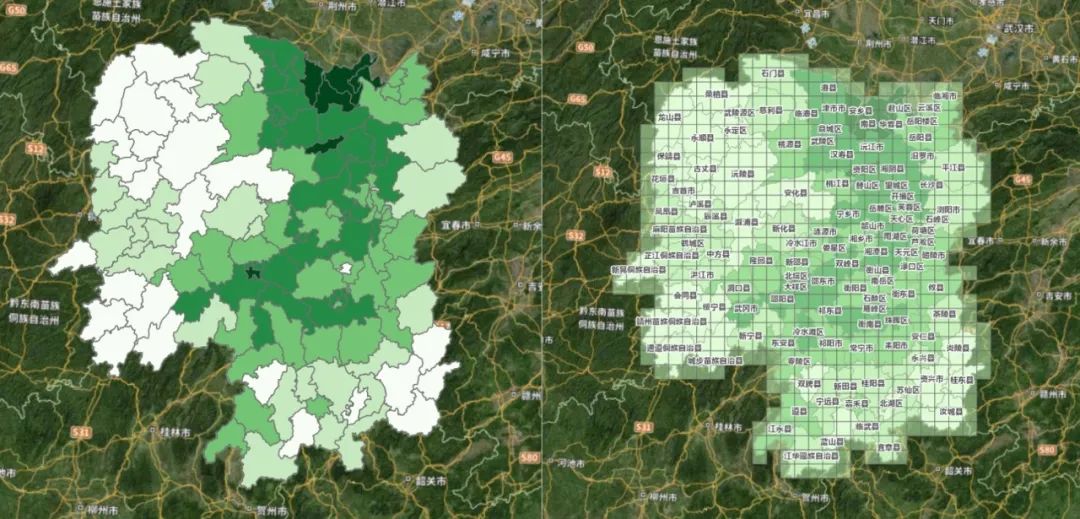
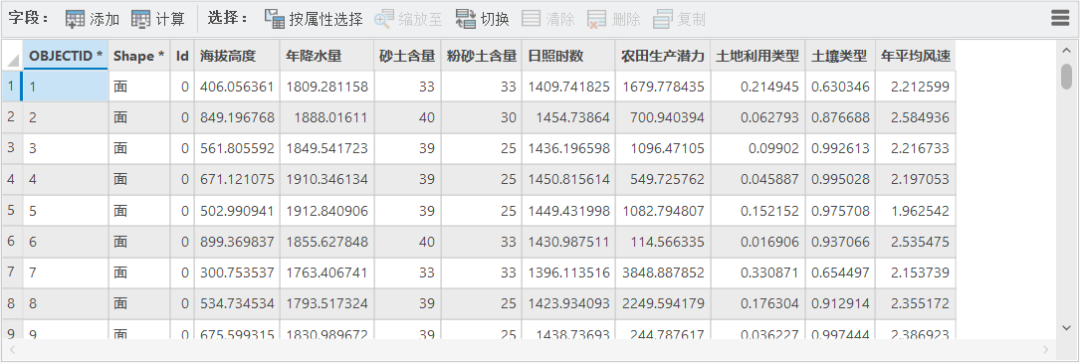
数据中含有的自变量为:海拔高度、砂土含量、粉砂土含量、日照时数、土地利用类型(耕地面积占比)、土壤类型(适宜种植类型的土壤面积占比)以及年平均风速。
因变量为:农田生产潜力。
PART.2 确定二元趋势及明确混杂变量
首先,可以先使用GeoScene Pro 中的局部二元关系工具先初步探究下两变量之间的趋势。结合图例可以看出,大部分区域年降水量与农田生产潜力之间呈现出负线性关系(绿色区域),少部分区域呈现出凸形关系(蓝色区域),极少部分区域为凹形关系(橙色区域)。
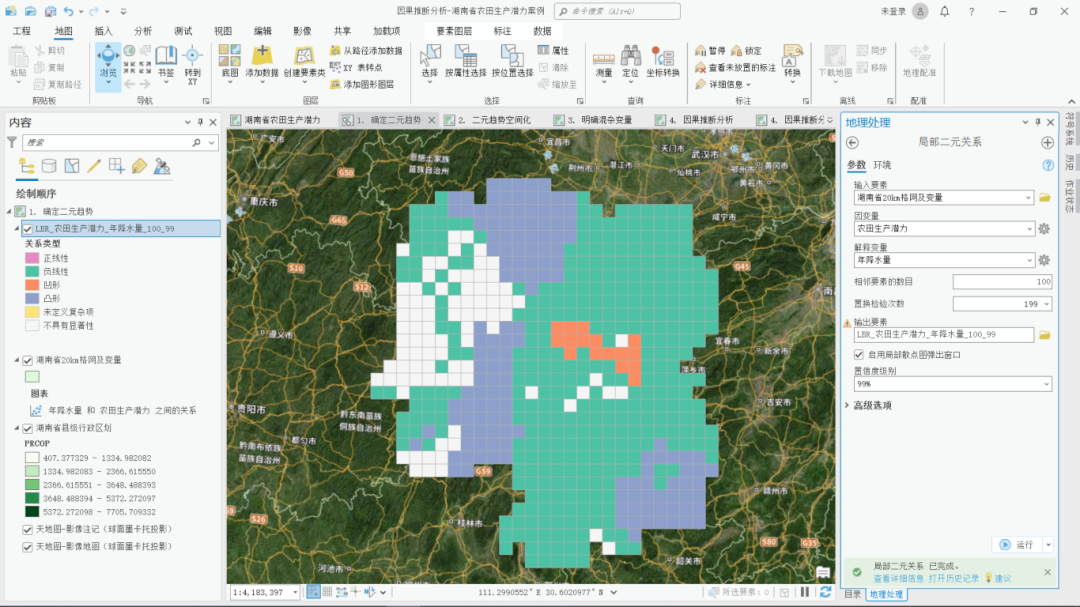
局部二元关系初探
最后,通过 GeoScene Pro 中的散点图矩阵功能,借助皮尔逊相关系数,明确以下混杂变量:海拔高度、砂土含量、粉砂土含量、日照时数、土壤类型、年平均风速,共六个变量。
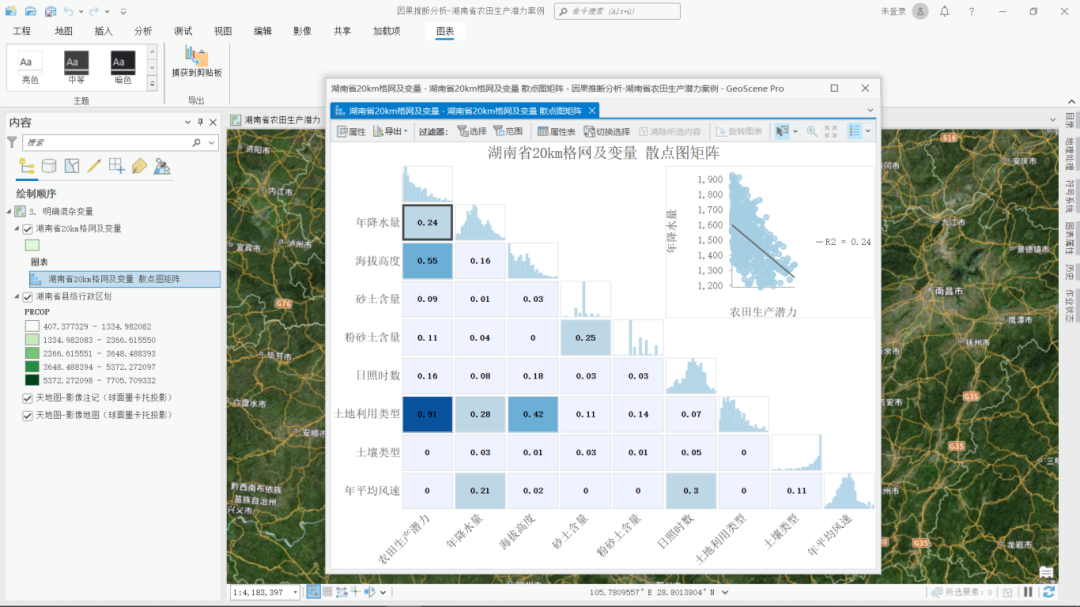
通过散点图矩阵中的皮尔逊相关系数明确混杂变量
PART.3 因果推断分析
接下来,我们使用 GeoScene Pro 5.1 新推出的因果推断分析工具来探究年降水量与农田生产潜力之间的关系。
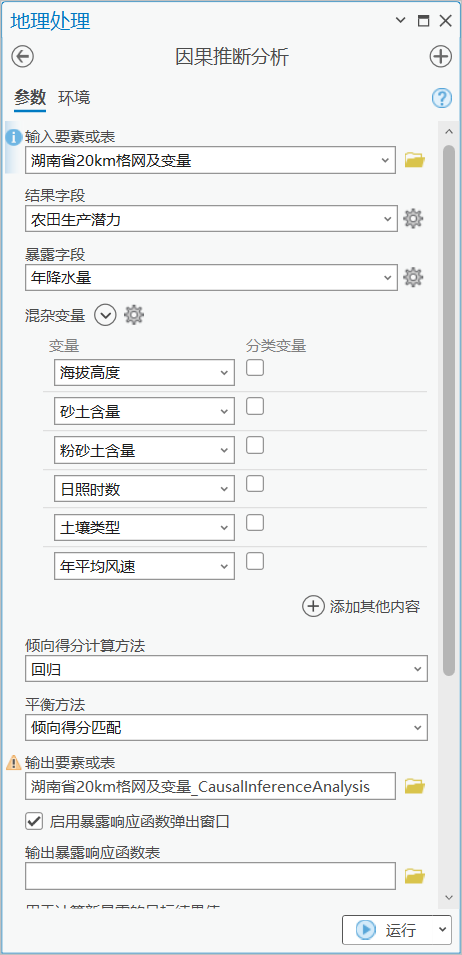
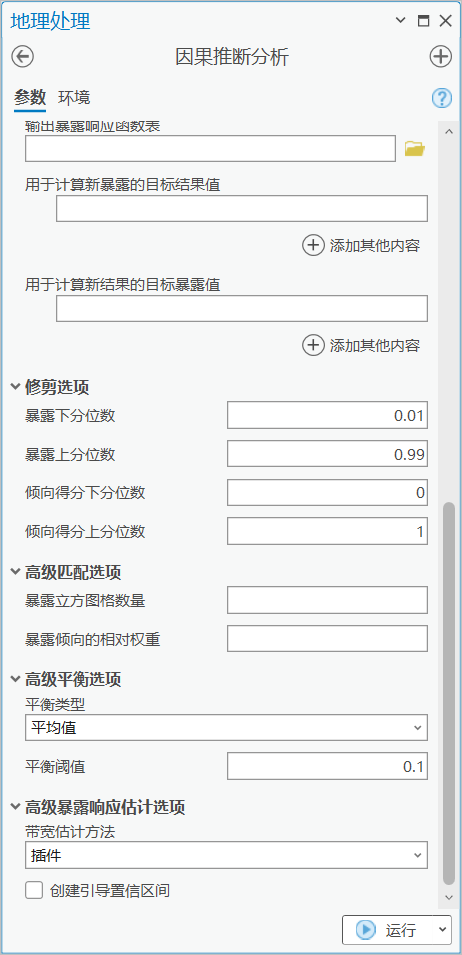
因果推断分析工具界面
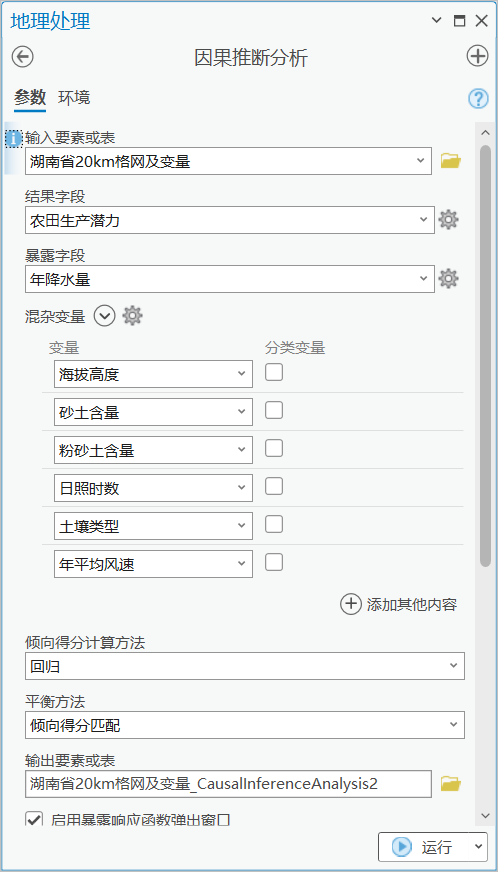
主要参数为:
-
输入要素或表:“湖南省20KM格网及变量”;
-
结果字段:“农田生产潜力”字段;
-
暴露字段:“年降水量”字段;
-
混杂变量:上一步确定的海拔高度、砂土含量、粉砂土含量、日照时数、土壤类型、年平均风速,共六个变量,均为连续变量;
-
倾向得分计算方法:指定将用于计算每个观测的倾向得分的方法。共提供两种方法:“回归”(默认)和“梯度提升”,本例中采用默认的回归算法;
-
平衡方法:指定将用于平衡混杂变量的方法。每种方法都会估计一组平衡权重,这些平衡权重用于移除混杂变量和暴露变量之间的相关性。本例中使用默认的“倾向得分匹配”方法;
-
启用暴露响应函数弹出窗口:指定是否将为每个观测创建弹出图表,其中显示了观测的局部 ERF。本例中选择启用弹出窗口;
设置完成后点击运行。
PART.4 结果解读
工具运行结束后将在地图中生成两个新图层。
其中第一个图像图层为曝光响应函数(ERF)。在本例中,对于湖南省研究区域,暴露变量为年降水量,结果变量为农田生产潜力,则 ERF 将估计如果年降水量增多或减少,同时保持所有其他变量(例如海拔高度、砂土含量等混杂变量)与年降水量变化之前相同,农田生产潜力将如何变化。本例中可以看出整体为下降趋势(粉色线)。
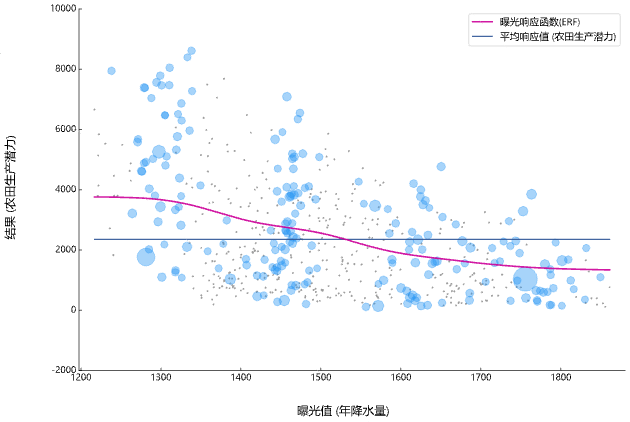
平均曝光响应函数
第二个为输出要素,点击输出要素中的单元格,可以在弹窗中查看该格网对应的局部曝光响应函数。
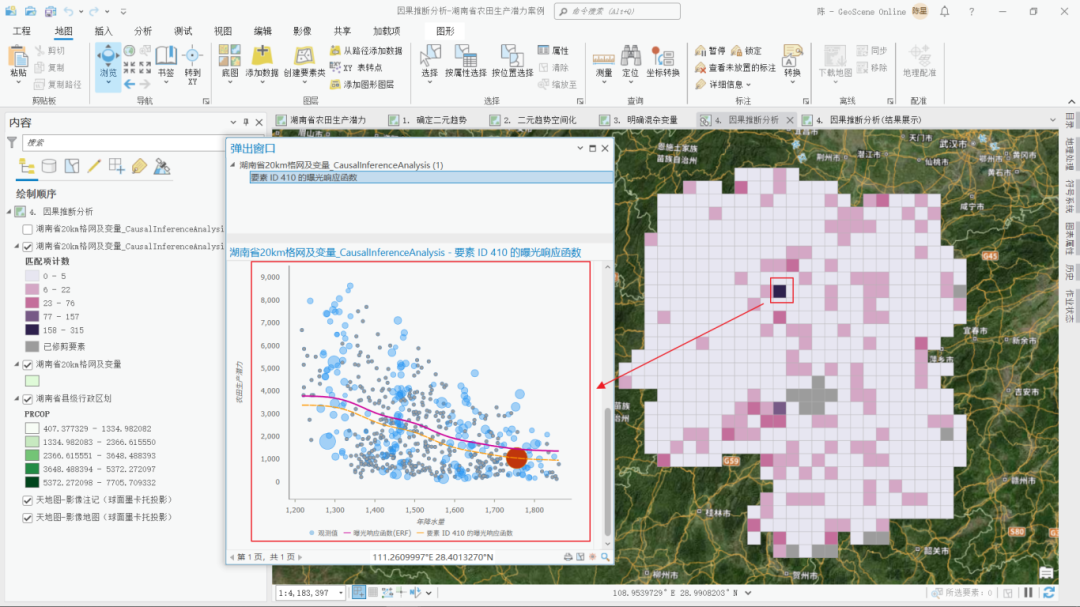
弹窗中的局部暴露响应函数
例如在上图中,可以看到有两条曲线。粉色曲线为考虑所有网格后的研究区平均暴露响应函数,而下方的黄色曲线为我们所选网格的暴露响应函数,可以看到黄色曲线为穿过所选网格所对应XY值(X:年降水量-1755,Y:农田生产潜力-1033)的和粉色曲线平行的曲线。黄色曲线反映了该网格年降水量与农田生产潜力之间的因果关系:在年降水量增加的情况下,农田生产潜力呈现出下降趋势。
点击图中其他的网格,可以审视不同地区所对应的不同的局部暴露响应函数,如下图中,该地区对应的局部暴露响应函数位于平均暴露响应函数上方。
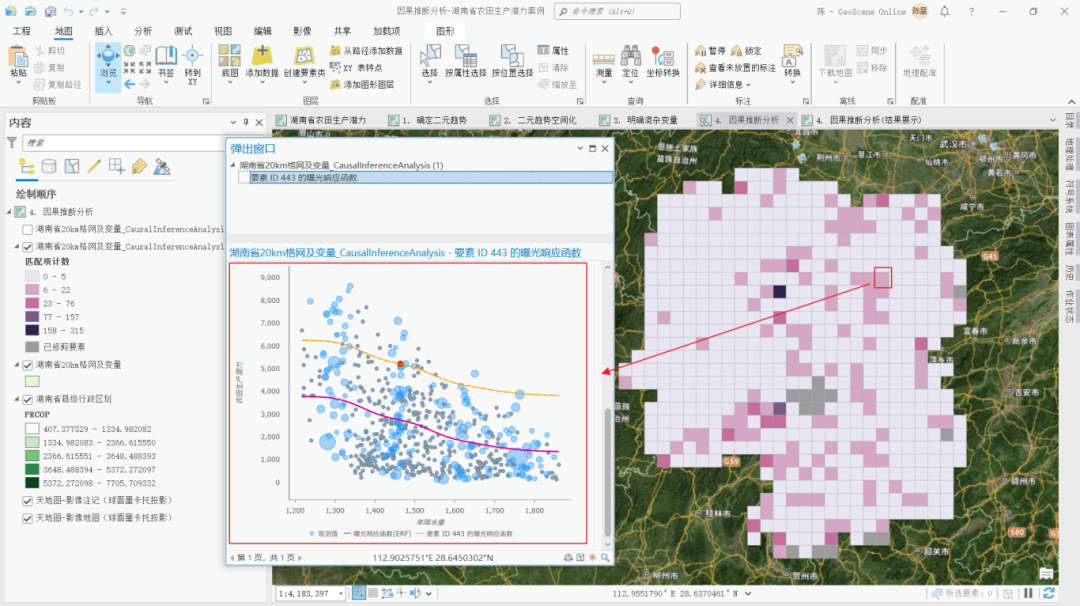
不同地区的局部暴露响应函数
PART.5 基于因果关系的预测
在明确了因果关系之后,还可以使用该工具进行预测。
例如,我们将农田生产潜力的最低值设为3000,我们想知道当保持其他变量不变时,年降水量需要位于哪个区间内,该地区农田生产潜力能不低于3000?
那针对这个场景,我们只需在工具中使用相同的参数,并在 “用于计算新暴露的目标结果值” 参数中填入我们设定的值3000,并运行工具。
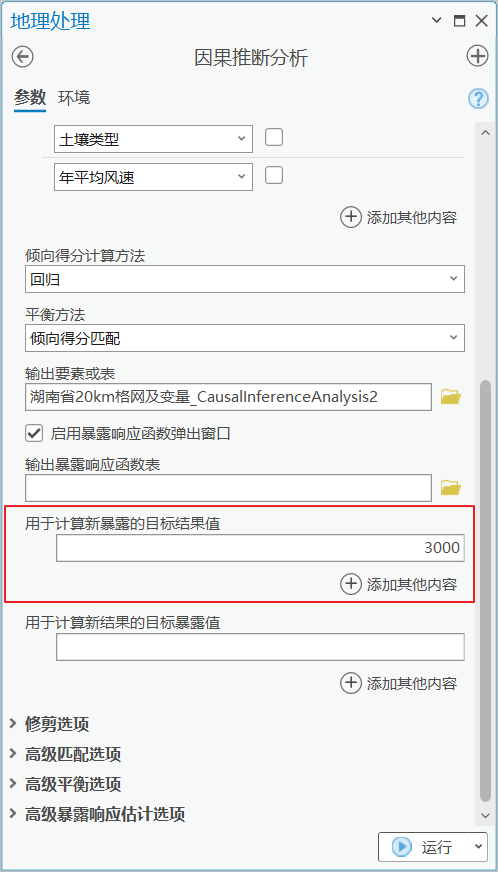
使用工具进行预测
弹窗中显示的内容与上一节中显示的内容类似,但是在我们输入了目标值3000后,可以在图中查看当前值与目标值之间的差距和改善方法,如下图中可以看到,该地区农田生产潜力低于3000,在年降水量减少143毫米的情况下,农田生产潜力值才能高于3000。
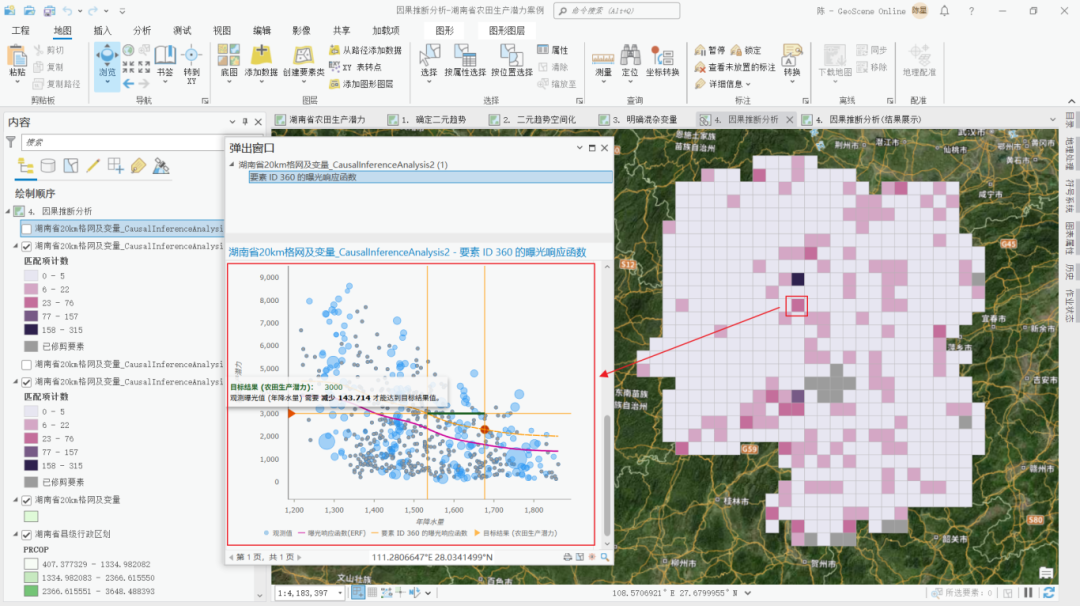
弹窗中显示的预测结果
那根据这一结果图层,我们可以进一步划分出针对预定的农田生产潜力目标值,各地区所面临的挑战。例如在下图中,红色区域表示该地区降水量需要极大幅度减少,才能达到设定的农田生产潜力目标值,绿色区域表示降水量继续增多的情况下,该地区也会满足要求。而灰色区域则表示无论降水量如何调整,都不能达到目标值,需要通过其他方式进行干预,如施肥等。
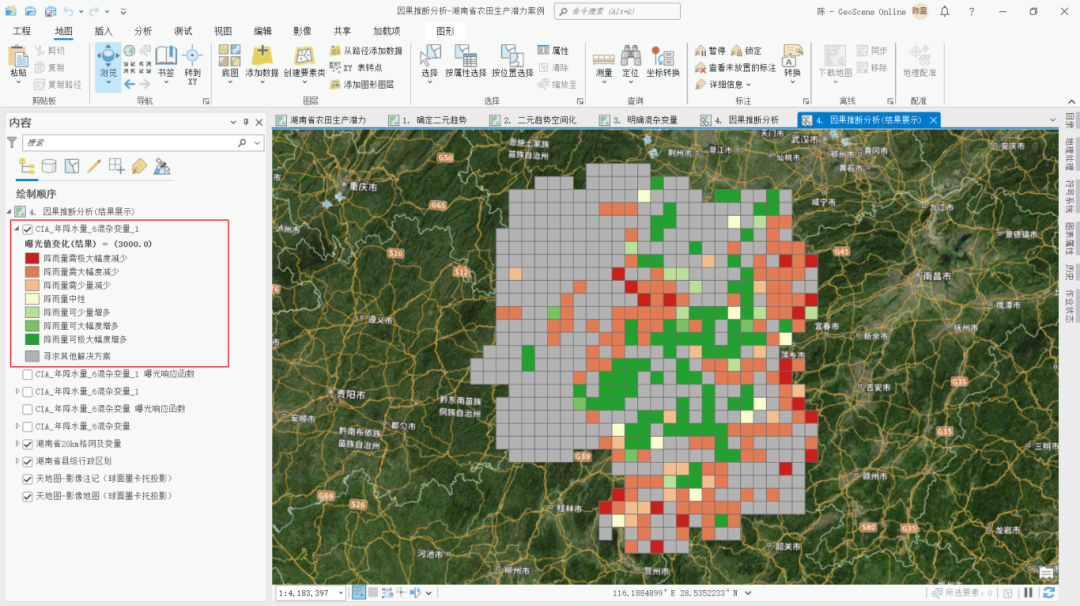
针对设定目标值 - 各地区应对方案
04 Demo视频
可以通过下面的视频了解完整的案例:
小结
在本篇文章中,我们详细讲解了因果推断分析这一统计学中重要的分析方法,以及因果性与相关性的区别。随后使用了GeoScene Pro 5.1中的因果推断分析工具,针对湖南省境内降水量对农田生产潜力关系进行了建模,并进行了基于因果关系的预测与评估。
因果推断分析在我们的现实生活的方方面面都有广泛的应用,利用GeoScene Pro中这一最新的工具,还可以进行其他诸如评估药物疗效、疾病风险因素分析,探究单行道修建对城市交通拥挤度的影响,分析煤炭消耗量与城市PM2.5污染之间的关系等多种分析。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









