




 本文介绍了一种在C++中计算字符串中特定字符(不区分大小写)出现次数的方法,使用toupper函数将输入转换为大写进行计数。
本文介绍了一种在C++中计算字符串中特定字符(不区分大小写)出现次数的方法,使用toupper函数将输入转换为大写进行计数。
题目:HJ2 计算某字符出现次数
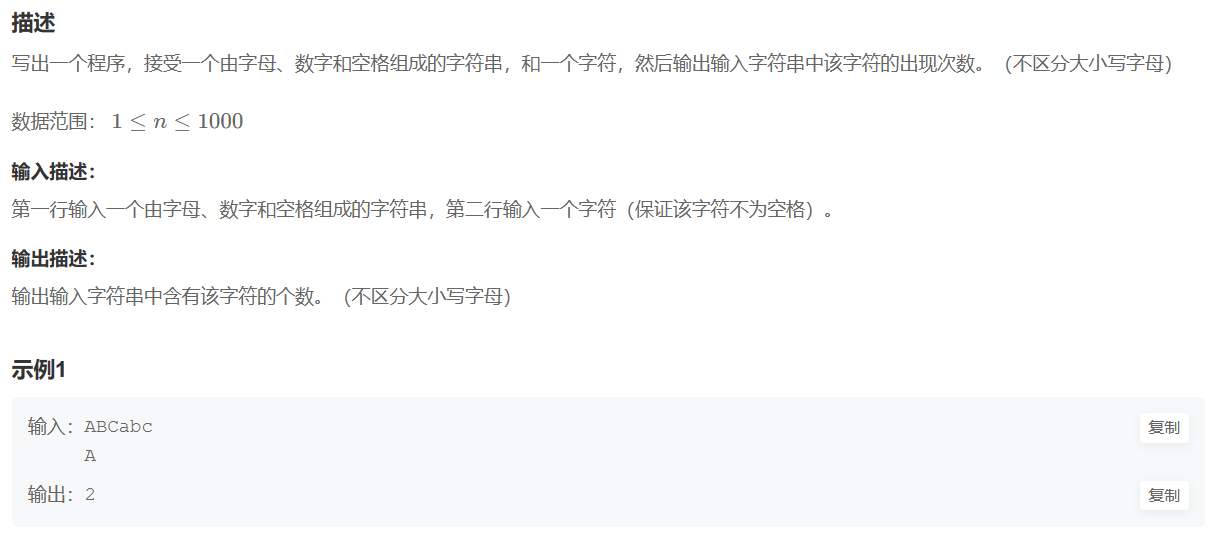
https://www.nowcoder.com/practice/a35ce98431874e3a820dbe4b2d0508b1
思路:不区分大小写可以用toupper都转成大写
代码如下
#include <cctype>
#include <iostream>
using namespace std;
int main() {
string input;
getline(cin, input);
char c = toupper(getchar());
int count = 0;
for (int i = 0; i < input.size(); i++) {
if (toupper(input[i]) == c) {
count++;
}
}
cout << count;
}
谢谢观看,祝顺利!

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









