







正文
1. 引言

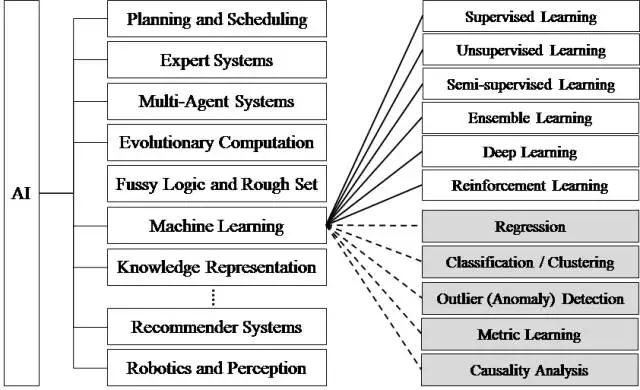
在当今数字化浪潮席卷全球的时代,机器学习无疑是科技领域最璀璨的明珠之一。作为人工智能的核心驱动力,它宛如一位拥有超凡智慧的 “魔法师”,悄然渗透到我们生活的方方面面,从清晨唤醒我们的智能语音助手,到出行时精准导航的交通 APP;从守护金融安全的风险预警系统,到助力医疗诊断的智能影像分析,机器学习的身影无处不在,持续重塑着我们的生活与工作模式,开启一场前所未有的智能化变革。
2. 机器学习基础入门
2.1 定义与本质
机器学习,宛如一座连接数据与智能决策的桥梁,处于人工智能领域的核心地带。它赋予计算机一种超凡能力,使其能够脱离预设的刻板程序,转而依据海量的数据自主探寻隐藏其中的规律与模式,进而精准地完成各类复杂任务。
从数学的视角来剖析,当给定一个训练数据集,机器学习的核心任务便是搜寻一个恰当的函数。如此一来,当面对新的输入时,模型通过得出的预测值能够最大程度地贴近真实结果。这实质上是一个复杂且精妙的数据驱动的优化求解过程,计算机在数据的海洋中不断 “摸索”,调整函数的参数,直至找到那个与真实世界规律最为契合的 “映射法则”,从而实现对未知的精准预测。
2.2 发展历程梳理
回顾机器学习的发展长河,早期的探索为后续的蓬勃兴起奠定了基石。彼时,简单线性回归等基础方法崭露头角,如同在黑暗中点亮的第一束微光,虽略显黯淡,却开启了数据探索的征程。随着时代的巨轮滚滚向前,计算能力呈指数级攀升,数据量也如汹涌浪潮般急剧增长,这为机器学习注入了强大动力,使其迎来了一个又一个突破。
20 世纪 80 年代,反向传播算法横空出世,宛如一把神奇的钥匙,解锁了多层神经网络训练的难题,让神经网络得以迅猛发展,从简单的感知机迈向了更为复杂、强大的架构,极大地拓展了机器学习的能力边界。
近年来,深度学习异军突起,成为变革的主力军。其中,AlexNet 在 2012 年的 ImageNet 图像识别竞赛中大放异彩,以压倒性优势击败众多对手,开启了深度学习在图像识别、语音识别、自然语言处理等诸多领域广泛应用的黄金时代。它如同一场风暴,席卷了整个科技界,促使各大行业纷纷引入深度学习技术,重塑业务流程,持续推动着机器学习向更高峰攀登,不断拓展其应用的广度与深度,为人类社会的智能化转型筑牢根基。
3. 核心类型全知晓
3.1 监督学习
3.1.1 原理精析
监督学习,作为机器学习家族中的关键成员,宛如一位严谨的 “学霸”,凭借着海量的已标注数据进行学习。在这个学习过程中,模型如同一个专注的 “学生”,仔细剖析输入数据 与对应的输出标签 之间的微妙关系,进而精准掌握从输入到输出的精确映射规律。
以手写数字识别任务为例,当我们向模型输入一张张手写数字的图像时,这些图像所蕴含的丰富特征,如笔画的粗细、走向、数字的形态等,便成为了模型的 “学习素材”。模型通过对成千上万张带有明确数字标签的手写图像进行深入学习,逐渐领悟到不同手写风格下每个数字的独特特征模式。如此一来,当面对全新的手写数字图像时,模型便能依据先前学习到的知识,胸有成竹地给出准确的数字类别预测,就像一位经验丰富的老师能够准确识别学生的作业答案一般。
3.1.2 算法与实例
在监督学习的 “算法宝库” 中,有着诸多实用且强大的工具。逻辑回归,作为其中的一员 “大将”,尤其擅长处理二分类问题。它基于线性回归的基础,巧妙地引入了逻辑函数,将连续的输出值映射到 0 与 1 之间,从而实现对样本类别的精准判断。在电子邮件的世界里,逻辑回归算法发挥着重要作用,它能够依据邮件的诸多特征,如发件人、邮件主题、正文内容中的关键词等,精准判断一封邮件是否为垃圾邮件,为我们的电子邮箱 “保驾护航”,免受垃圾信息的侵扰。
决策树算法,则宛如一棵枝繁叶茂的 “智慧树”,它以树形结构来展现决策过程,直观易懂。每个内部节点代表一个特征测试,分支代表特征的不同取值,而叶节点则对应着最终的决策结果。在客户流失预测的场景中,决策树模型大显身手。它依据客户的各种属性,如年龄、性别、消费金额、消费频率,以及行为特征,如近期是否有投诉、是否参与过特定活动等,构建出一棵详尽的决策树。通过沿着树的分支逐步判断,最终确定客户流失的可能性,为企业提供极具价值的预警信息,助力企业提前采取措施挽留客户,恰似一位经验老到的商业顾问,为企业发展出谋划策。
3.2 无监督学习
3.2.1 原理揭秘
无监督学习恰似一位充满好奇心的 “探险家”,一头扎进无标签数据的 “神秘森林”,致力于挖掘其中隐藏的模式、结构或分组信息。它不依赖于预先设定的 “标准答案”,而是凭借自身强大的自主探索能力,在数据的海洋中寻找规律。
在文本处理这片广阔天地里,无监督学习的表现尤为亮眼。以主题建模为例,当面对海量的文本数据,如新闻文章、学术论文、社交媒体帖子时,模型运用主题建模算法,能够抽丝剥茧般地提取出主要主题。它通过分析文本中词汇的共现频率、语义关联等信息,将相似主题的文本归为一组,从而发现文本集合背后隐藏的内在语义结构,就像一位知识渊博的学者,能够从繁杂的文献中梳理出清晰的知识脉络。
3.2.2 算法应用
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)密度聚类算法,是无监督学习领域中的一把 “利器”。它基于数据点的密度进行聚类,能够敏锐地识别出数据集中不同密度的区域。在地理信息系统中,它发挥着独特的作用。通过分析城市、人口、经济活动等多维度数据的分布密度,DBSCAN 算法可以精准地将地理区域划分为不同的聚类,清晰地展现出城市聚集区、人口密集区,以及相对稀疏的乡村地区等地理现象,为城市规划、资源分配提供科学依据,仿佛是一位专业的地理分析师,绘制出精准的地理蓝图。
关联规则挖掘的 Apriori 算法,如同一位精明的 “购物侦探”,专注于找出数据项之间的隐藏关联关系。在零售行业,它的价值得到了淋漓尽致的体现。通过对海量交易数据的深入挖掘,Apriori 算法能够发现那些看似不相关商品之间的紧密联系,比如购买面包的顾客常常会同时购买牛奶,购买手机的顾客大概率会选购手机壳等。这些宝贵的信息能够助力商家优化商品陈列,制定更具吸引力的营销策略,实现销售额的显著增长,如同为商家点亮了一盏明灯,指引其在激烈的市场竞争中找准方向。
3.3 半监督学习
3.3.1 原理阐释
半监督学习宛如一位智慧的 “调和大师”,巧妙地整合了少量有标签数据的 “精准指引” 与大量无标签数据的 “丰富信息”,实现优势互补。在实际应用中,获取大量有标签数据往往成本高昂,耗时费力,而无标签数据却如潮水般海量涌现。半监督学习正是看准了这一现实困境,充分利用无标签数据中蕴含的潜在信息,辅助模型学习,从而有效增强模型的泛化性能,使其能够在更广泛的场景中精准应对。
在医学图像分析这一关键领域,半监督学习展现出了巨大的潜力。医学影像数据的标注工作极为复杂,需要专业医生耗费大量时间精力,且对专业知识要求极高。半监督学习模型应运而生,它仅需少量已标注病变图像作为 “种子”,结合大量未标注图像,便能开启高效学习之旅。通过挖掘无标签图像中的共性特征、潜在模式,模型不断丰富自身对疾病特征的认知,进而大幅提升疾病诊断的准确性,为医疗工作者提供有力支持,如同一位得力的医疗助手,协助医生更精准地识别病魔的蛛丝马迹。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











