




 本文探讨了快速排序算法的原理和性能特点。快速排序并非在所有情况下都是最优选择,但在大规模数据时表现出高效率,平均时间复杂度为O(n log n)。然而,当数据已排序或接近排序时,快速排序可能退化为O(n²)。算法的核心是选取基准并分区,通过递归实现排序。快速排序的优越性在于较少的比较次数和高效的平均性能。
本文探讨了快速排序算法的原理和性能特点。快速排序并非在所有情况下都是最优选择,但在大规模数据时表现出高效率,平均时间复杂度为O(n log n)。然而,当数据已排序或接近排序时,快速排序可能退化为O(n²)。算法的核心是选取基准并分区,通过递归实现排序。快速排序的优越性在于较少的比较次数和高效的平均性能。
相信我们在没接触过排序知识之前,一定会觉得快速排序非常具有魅力,不因别的单纯快排这个名字就让人不明觉厉,但是了解一个算法不应该只知道code,了解思想,应用非常重要。
我先问出我心中非常好奇的问题:
- 快排为啥叫快排,快排是所有排序里面性能最好的吗?
- 快排适合什么情况呢,还是无论什么情况下快排总是最好的(显然× ?
- 快排算法的思想是什么?其性能优良的原因是依赖于算法中的哪个部分?
首先回答前两个问题:
快排的性能在所有排序算法里面是最好的,数据规模越大快速排序的性能越优。快排在极端情况下会退化成O(n²)。的算法,因此假如在提前得知处理数据可能会出现极端情况的前提下,可以选择使用较为稳定的归并排序。
下面回答第三个问题:
Quick Sort
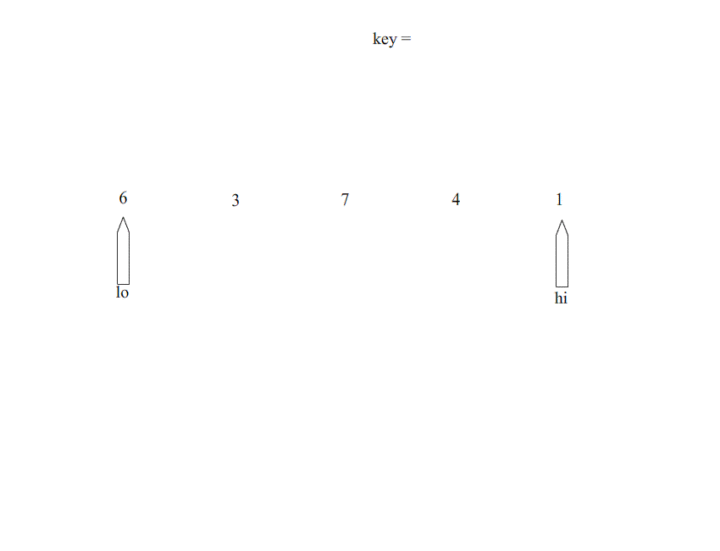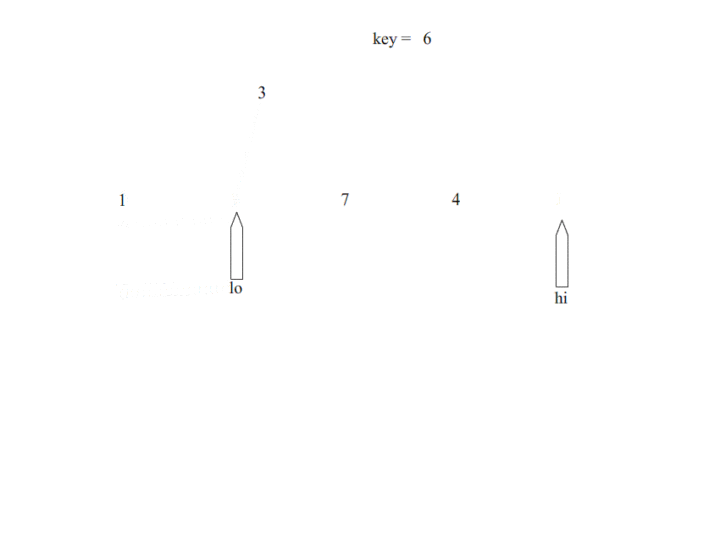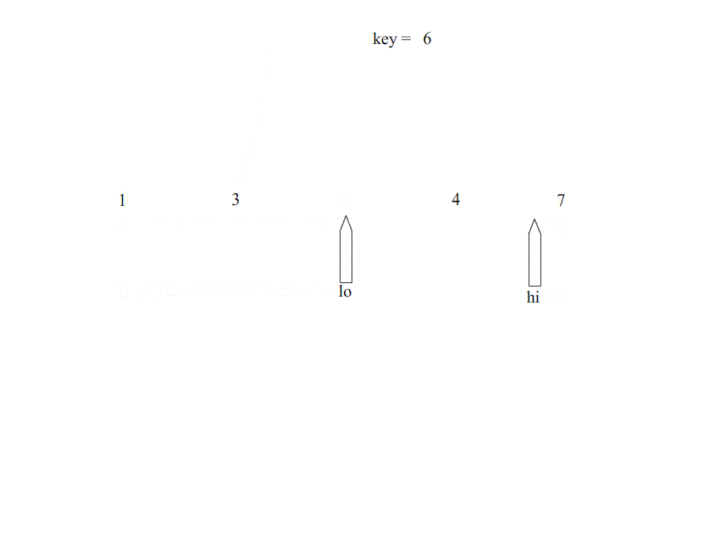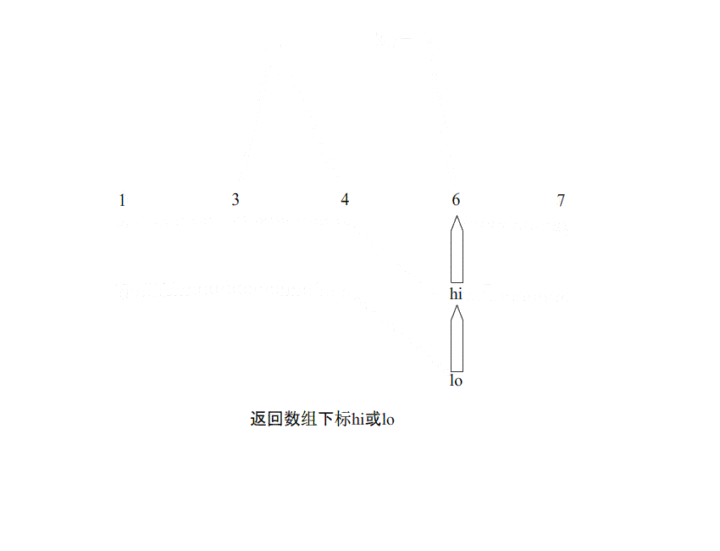
显然,我们从图中可以看出快排运用了二分的思想,首先选择一个基准,定义左右两端指针,先从左到右进行扫描直到,R[hi] < temp,将R[hi]移动至lo所在位置 [公式] 从右往左进行扫描,直到R[lo] > temp,将R[lo]移动到hi所在位置上,左右端指针在排序过程中从数组的两端往中间进行靠近,直到hi == lo。而快速排序则要进行多次快排过程,直到划分的区间最后长度仅为1.
总结下来(转, 自己懒得敲了:
选择A中的任意一个元素pivot,该元素作为基准
将小于基准的元素移到左边,大于基准的元素移到右边(分区操作)
A被pivot分为两部分,继续对剩下的两部分做同样的处理
直到所有子集元素不再需要进行上述步骤
void QuickSort(R[], int lo, int hi)
{
将lo, hi用i, j两个副本进行拷贝(**
声明基准;
if(划分长度大于等于2,即hi > lo)
{
取基准为左端端点;//都可
当hi 不等于 lo时循环;
当hi > lo且R[hi] > temp时循环;
hi--(继续往中间靠;
R[lo] = R[hi];//发现小于基准的替换将其替换到左半区
当lo < hi且R[lo] < temp时循环;
lo++(继续往中间靠;
R[hi] = R[lo];//发现大于基准的将其替换到右半区
在hi,lo重合处放基准;//数据平衡,循环里有一个数据是直接被覆盖的,就是基准,现在将其添加回数组中
QuickSort(R[], lo, i - 1);
QuickSort(R[], i + 1, hi);//递归继续进行快排
//要是前面没有进行副本拷贝在这里进行递归操作时就不太好判断边界了。
}
}
[公式] 请写出快速排序的真正代码(见文末)
现在回答一下,为什么快速排序是平均性能最好的排序算法,其优渥之处体现在哪?
快速排序的优越性体现在他没有多余的比较上,对于初学者,我们可以较为简单的认为,快排所需要的指令数会比较少。
void QuickSort(int R[], int lo, int hi){
int i = lo, j = hi;
int temp;
if(i < j){
temp = R[i];
while (i != j)
{
while(j > i && R[j] > temp)-- j;
R[i] = R[j];
while(i < j && R[i] < temp)++ i;
R[j] = R[i];
}
R[i] = temp;
QuickSort(R, lo, i - 1);
QuickSort(R, i + 1, hi);
}
}

















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









