





什么是Neo4j?
Neo4j是一个开源的NoSQL图形数据库,2003 年开始开发,使用 scala和java 语言,2007年开始发布。
- 是世界上最先进的图数据库之一,提供原生的图数据存储,检索和处理;
- 采用属性图模型(Property graph model),极大的完善和丰富图数据模型;
- 专属查询语言 Cypher,直观,高效;
官网: Neo4j Graph Database & Analytics | Graph Database Management System
Neo4j的特性:
- SQL就像简单的查询语言Neo4j CQL
- 它遵循属性图数据模型
- 它通过使用Apache Lucence支持索引
- 它支持UNIQUE约束
- 它包含一个用于执行CQL命令的UI:Neo4j数据浏览器
- 它支持完整的ACID(原子性,一致性,隔离性和持久性)规则
- 它采用原生图形库与本地GPE(图形处理引擎)
- 它支持查询的数据导出到JSON和XLS格式
- 它提供了REST API,可以被任何编程语言(如Java,Spring,Scala等)访问
- 它提供了可以通过任何UI MVC框架(如Node JS)访问的Java脚本
- 它支持两种Java API:Cypher API和Native Java API来开发Java应用程序
Neo4j的优点:
- 它很容易表示连接的数据
- 检索/遍历/导航更多的连接数据是非常容易和快速的
- 它非常容易地表示半结构化数据
- Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习
- 使用简单而强大的数据模型
- 它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有 连接或索引
各种NOSQL对比
| 分类 | 数据模型 | 优势 | 劣势 | 举例 |
|---|---|---|---|---|
| 键值对数据库 | 哈希表 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 | Redis |
| 列存储数据库 | 列式数据存储 | 查找速度快;支持分布横向扩展;数据压缩率高 | 功能相对受限 | HBase |
| 文档型数据库 | 键值对扩展 | 数据结构要求不严格;表结构可变;不需要预先定义表结构 | 查询性能不高,缺乏统一的查询语法 | MongoDB |
| 图数据库 | 节点和关系组成的图 | 利用图结构相关算法(最短路径、节点度关系查找等) | 可能需要对整个图做计算,不利于图数据分布存储 | Neo4j |
更多Neo4J详细专题教程请见Neo4J超详细专题教程,快来收藏起来吧-腾讯云开发者社区-腾讯云 (tencent.com)
一、实验目的/原理
2. 掌握用Neo4j创建知识图谱的方法;
3. 掌握用Cypher语言对Neo4j知识图谱进行访问的方法;
4. 掌握用Neo4j Python 驱动包访问Neo4j知识图谱的方法;
5. 掌握用py2neo访问Neo4j知识图谱的方法。
二、实验重点和难点
难点:用Neo4j Python 驱动包和py2neo访问Neo4j知识图谱。
三、实验内容及步骤
实验内容:
1. 下载安装Neo4j ;
2. 创建知识图谱,并使用Cypher语言进行查询;
3. 用Neo4j Python 驱动包访问数据库,进行增删改查的操作;
4. 用py2neo访问数据库,进行增删改查的操作。
实验步骤:
1. 下载安装neo4j ,可以选择windows解压缩版、desktop版、linux版等。
下载地址: https://neo4j.com/deployment-center/#gdb-tab
这里选用的是打包的社区版 5.19.0,Java版本建议Java17,如果偷懒下载desktop桌面版更方便。

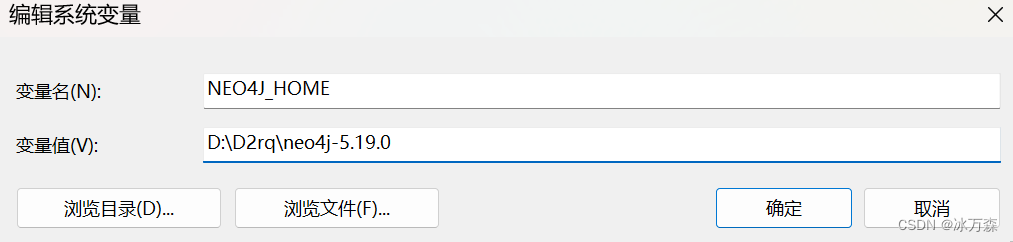
新建系统变量NEO4J_HOME
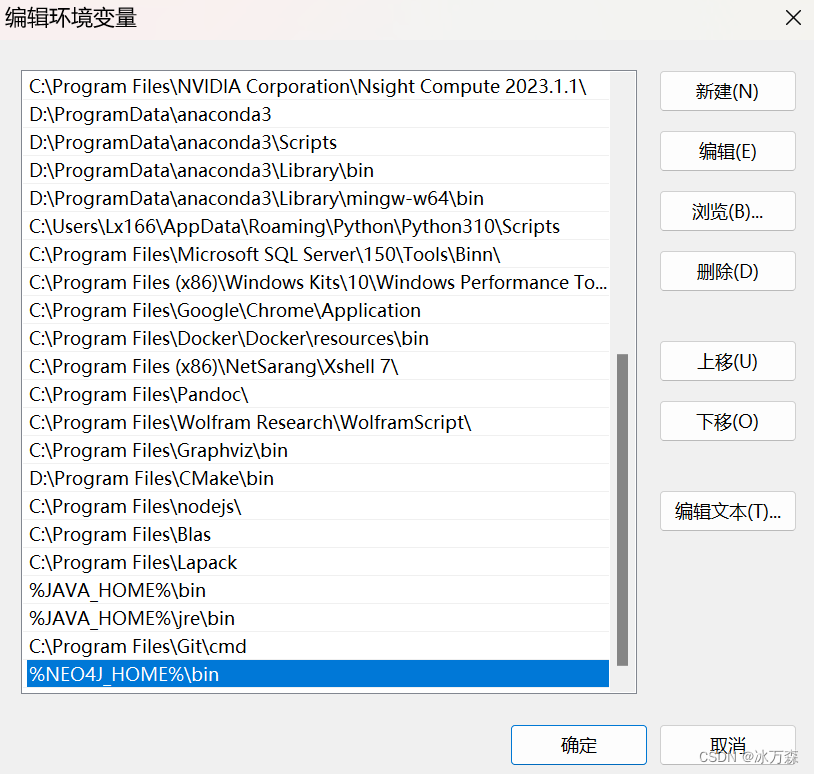
在path里新建环境变量%NEO4J_HOME%\bin
neo4j.bat console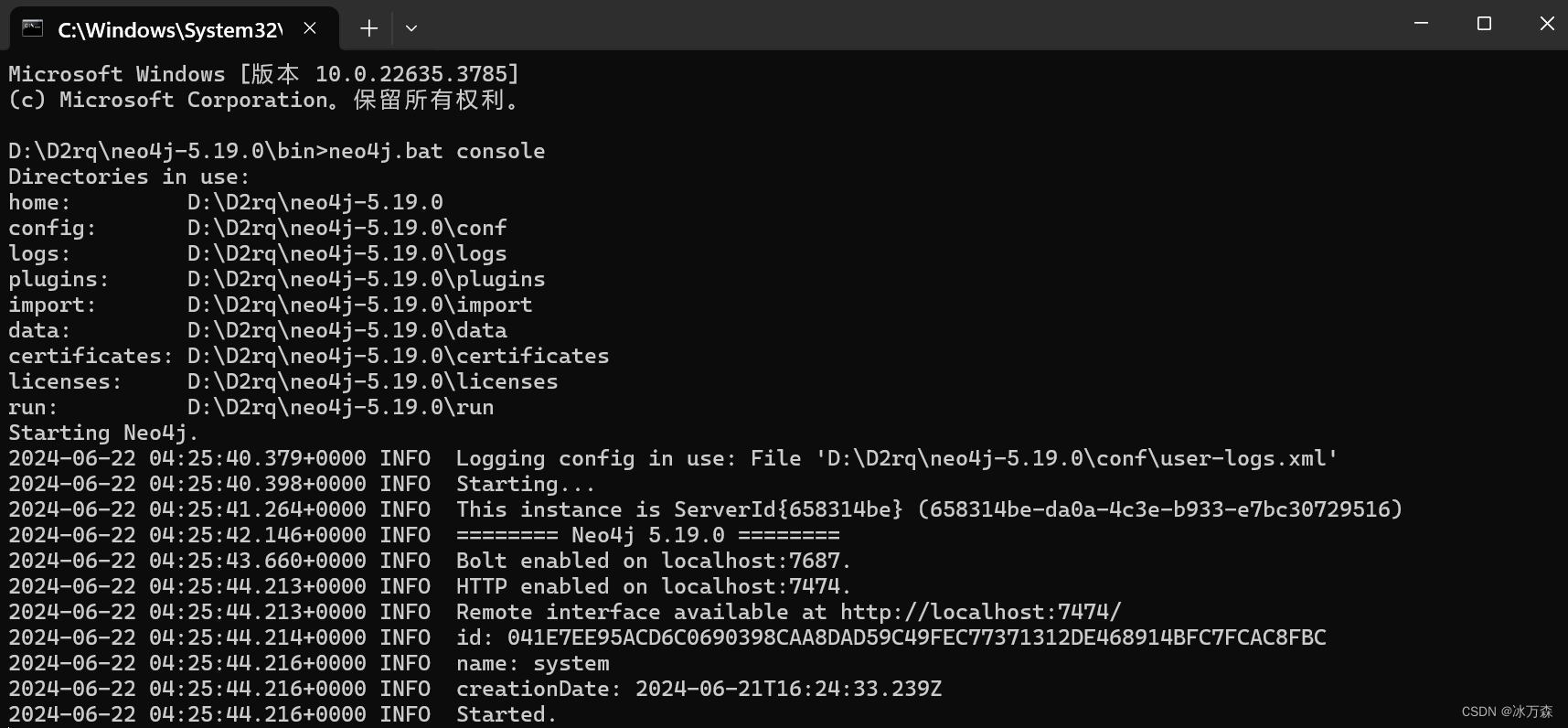
2.本实验选取《知识工程 人工智能如何学贯古今》案例二:《家有儿女》人物关系图谱,按照指定的步骤和要求完成数据库的创建和查询;
删除数据库中以往的图,确保在一个空白的环境中进行操作
match (n) detach delete n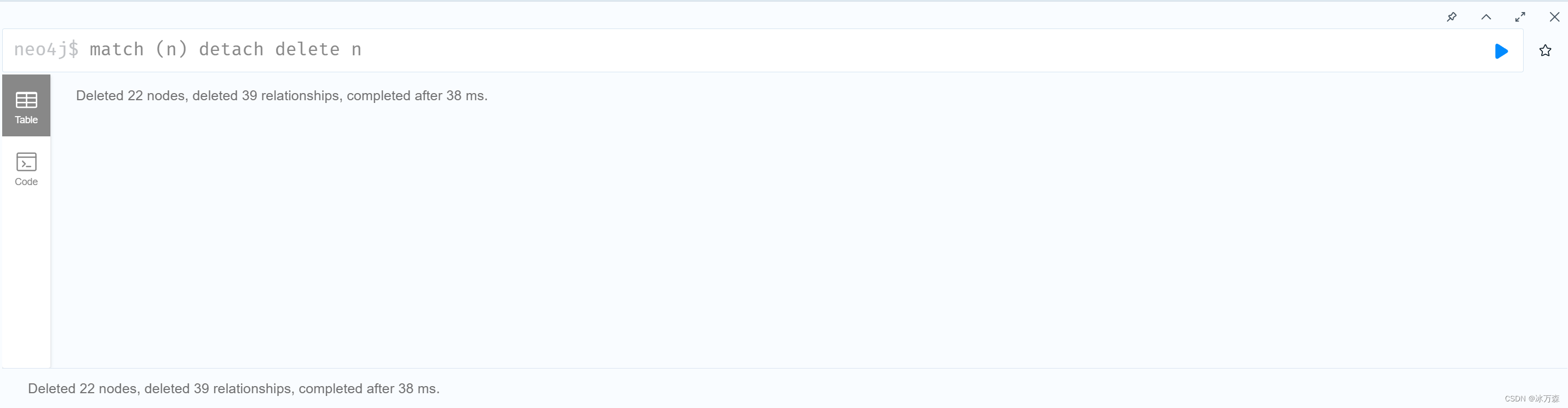
CREATE (n:Person {name: '夏东海'})RETURN n;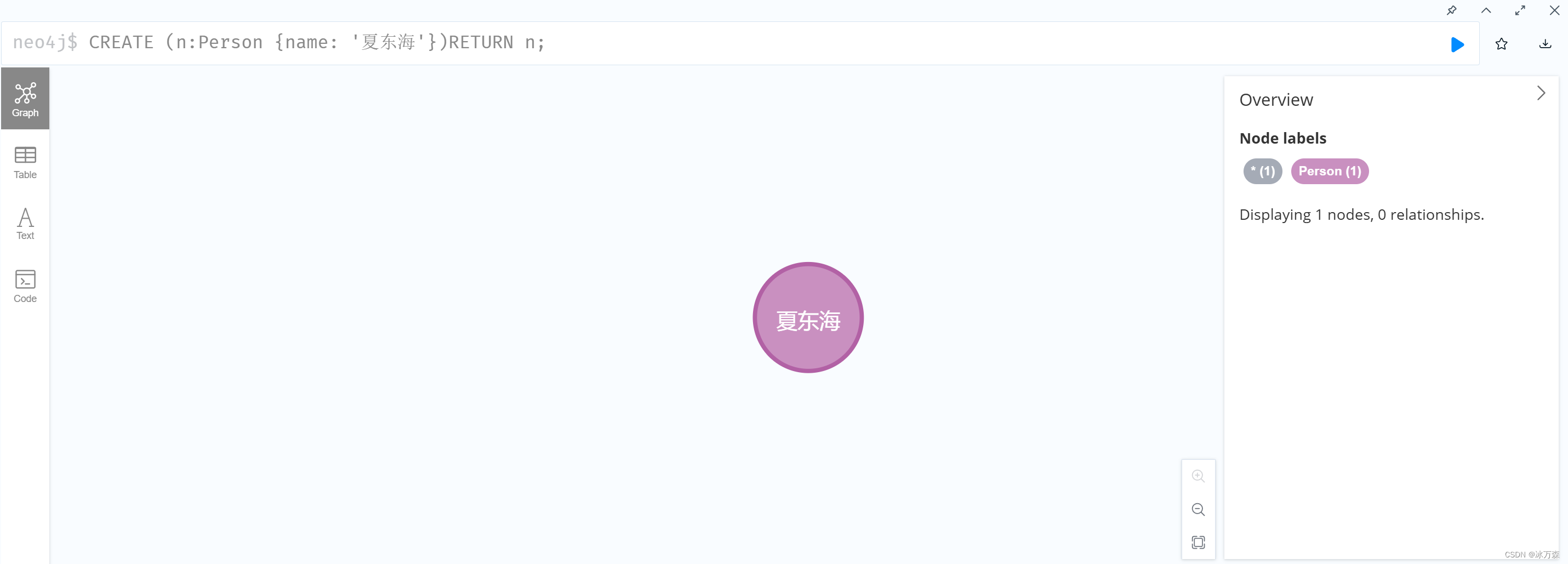
CREATE (n1:Person {name: '刘梅'}),
(n2:Person {name: '刘星'}),
(n3:Person {name: '夏雪'}),
(n4:Person {name: '夏雨'}),
(n5:Person {name: '胡统一'}),
(n6:Person {name: '玛丽'}),
(n7:Person {name: '范晓英'}),
(n8:Person {name: '夏祥'}),
(n9:Person {name: '杨欣'}),
(n10:Person {name: '戴明明'}),
(n11:Person {name: '戴天高'}),
(n12:Person {name: '胖婶'})
RETURN n1, n2, n3, n4, n5, n6, n7, n8, n9, n10, n11, n12;
CREATE (n:Job {title: '护士长'})
RETURN n;
CREATE (n:Job {title: '学生'})
RETURN n;
CREATE (n:Job {title: '编导'})
RETURN n;
CREATE (n:Job {title: '无业游民'})
RETURN n;
CREATE (n:Job {title: '社区工作人员'})
RETURN n;
CREATE (n:Job {title: '无业游民'})
RETURN n;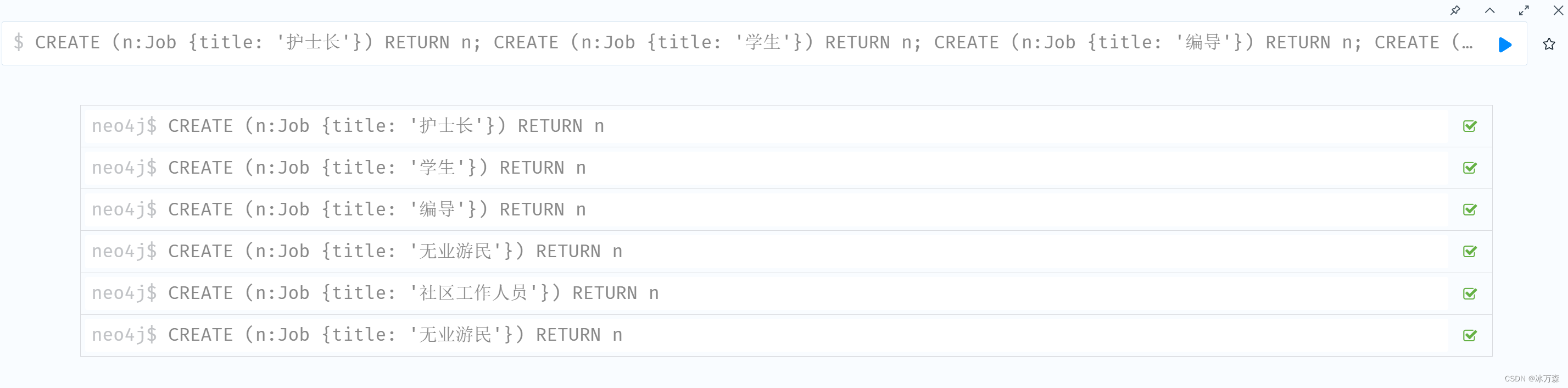
CREATE (n:Location {country: '中国', city: '北京'});
CREATE (n:Location {country: '美国', city: '纽约'});
MATCH (a:Person {name: '刘梅'})MERGE (a)-[:妻子]->(b:Person {name: '夏东海'})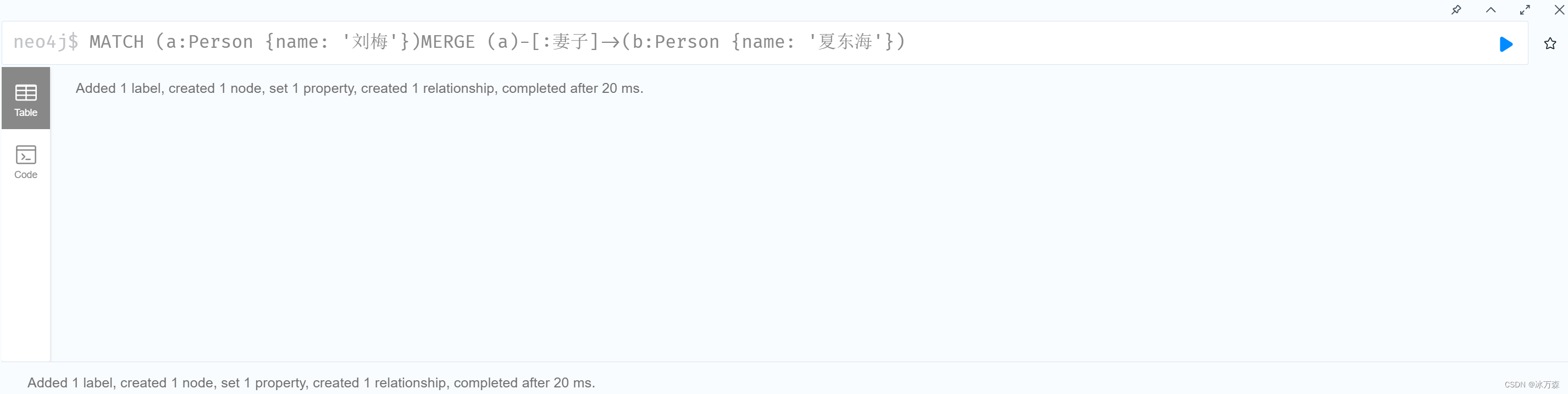
MATCH (a:Person {name:'刘梅'}), (b:Person {name:'夏东海'}) MERGE (a)-[:妻子]->(b);
MATCH (a:Person {name:'刘梅'}), (b:Person {name:'夏雨'}) MERGE (a)-[:继母]->(b);
MATCH (a:Person {name:'刘梅'}), (b:Person {name:'夏雪'}) MERGE (a)-[:继母]->(b);
MATCH (a:Person {name:'刘梅'}), (b:Person {name:'胡统一'}) MERGE (a)-[:前妻]->(b);
MATCH (a:Person {name:'刘星'}), (b:Person {name:'刘梅'}) MERGE (a)-[:儿子]->(b);
MATCH (a:Person {name:'刘星'}), (b:Person {name:'胡统一'}) MERGE (a)-[:儿子]->(b);
MATCH (a:Person {name:'夏东海'}), (b:Person {name:'刘星'}) MERGE (a)-[:继父]->(b);
MATCH (a:Person {name:'玛丽'}), (b:Person {name:'夏东海'}) MERGE (a)-[:前妻]->(b);
MATCH (a:Person {name:'夏雪'}), (b:Person {name:'夏东海'}) MERGE (a)-[:女儿]->(b);
MATCH (a:Person {name:'夏雨'}), (b:Person {name:'夏东海'}) MERGE (a)-[:儿子]->(b);
MATCH (a:Person {name:'夏雪'}), (b:Person {name:'玛丽'}) MERGE (a)-[:女儿]->(b);
MATCH (a:Person {name:'夏雨'}), (b:Person {name:'玛丽'}) MERGE (a)-[:儿子]->(b);
MATCH (a:Person {name:'夏雨'}), (b:Person {name:'夏雪'}) MERGE (a)-[:弟弟]->(b);
MATCH (a:Person {name:'夏雪'}), (b:Person {name:'刘星'}) MERGE (a)-[:姐姐]->(b);
MATCH (a:Person {name:'刘星'}), (b:Person {name:'夏雨'}) MERGE (a)-[:哥哥]->(b);
MATCH (a:Person {name:'戴明明'}), (b:Person {name:'夏雪'}) MERGE (a)-[:朋友]->(b);
MATCH (a:Person {name:'戴天高'}), (b:Person {name:'刘梅'}) MERGE (a)-[:同学]->(b);
MATCH (a:Person {name:'戴天高'}), (b:Person {name:'戴明明'}) MERGE (a)-[:父亲]->(b);
MATCH (a:Person {name:'胖婶'}), (b:Person {name:'刘梅'}) MERGE (a)-[:邻居]->(b);
MATCH (a:Person {name:'夏祥'}), (b:Person {name:'夏东海'}) MERGE (a)-[:父亲]->(b);
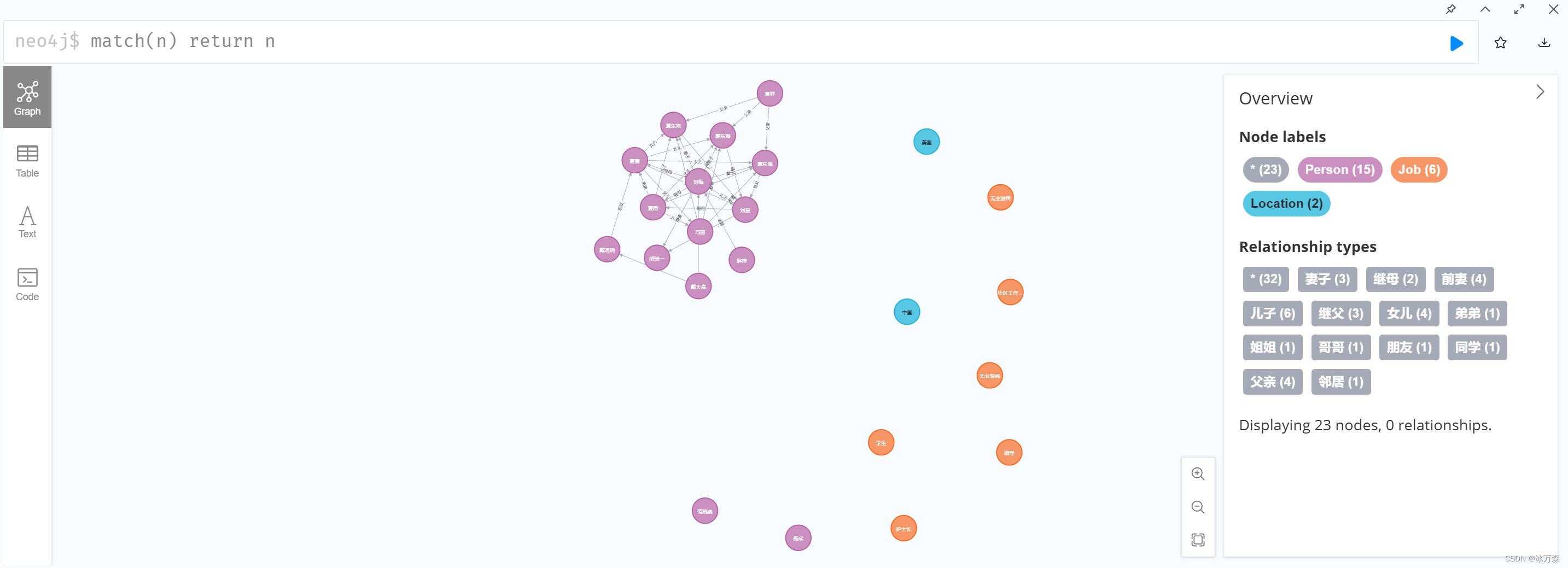
MATCH (a:Person {name:'刘梅'}), (b:Location {country:'中国', city:'北京'})
MERGE (a)-[:居住]->(b)
;
MATCH (a:Person {name:'夏东海'}), (b:Location {country:'中国', city:'北京'})
MERGE (a)-[:居住]->(b)
;
MATCH (a:Person {name:'玛丽'}), (b:Location {country:'美国', city:'纽约'})
MERGE (a)-[:居住]->(b)
;
MATCH (a:Person {name:'刘梅'}), (b:Job {title:'护士长'})
MERGE (a)-[:职业]->(b);
MATCH (a:Person {name:'夏东海'}), (b:Job {title:'编导'})
MERGE (a)-[:职业]->(b);
MATCH (a:Person {name:'胡统一'}), (b:Job {title:'无业游民'})
MERGE (a)-[:职业]->(b);
MATCH (a:Person {name:'夏雨'}), (b:Job {title:'学生'})
MERGE (a)-[:职业]->(b);
MATCH (a:Person {name:'刘星'}), (b:Job {title:'学生'})
MERGE (a)-[:职业]->(b);
MATCH (a:Person {name:'夏雪'}), (b:Job {title:'学生'})
MERGE (a)-[:职业]->(b);
MATCH (a:Person {name:'胖婶'}), (b:Job {title:'社区工作人员'})
MERGE (a)-[:职业]->(b);
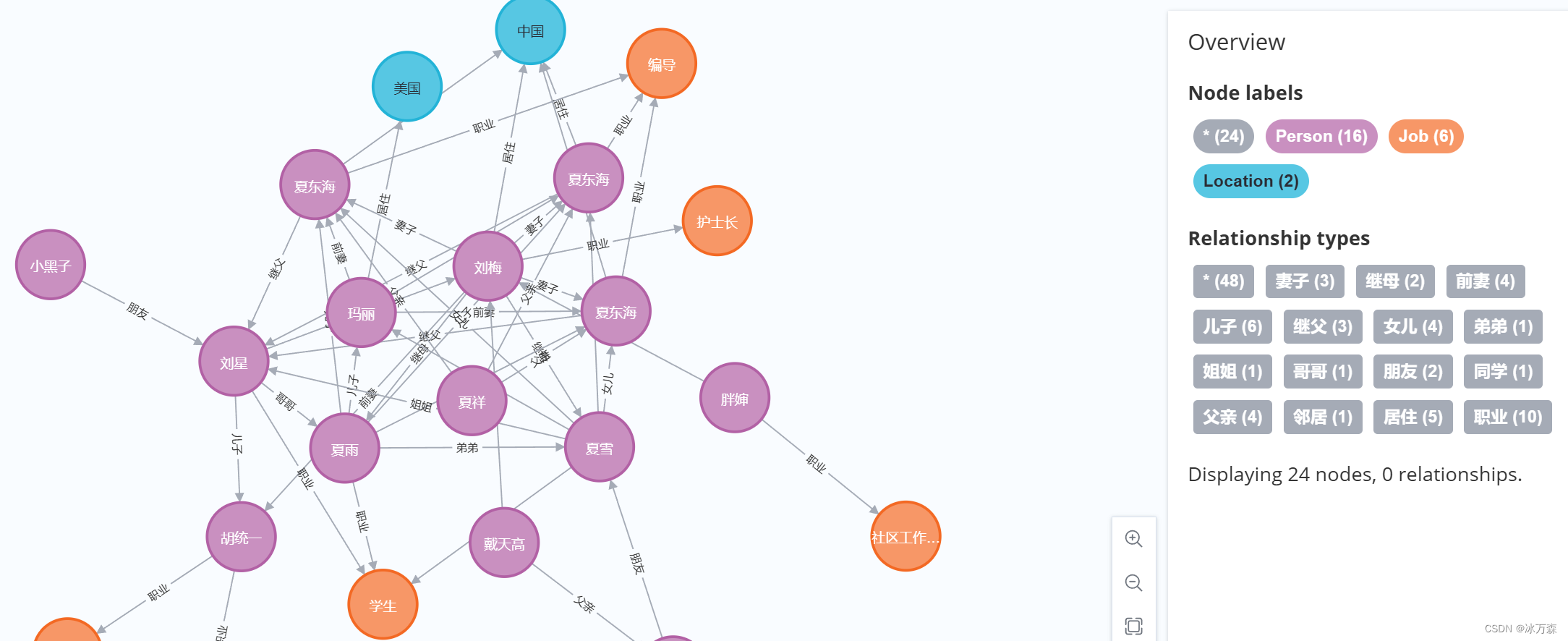 3. 安装Neo4j Pytho驱动包,用Python编程对数据库进行增删改查的操作,操作的内容自行决定;4. 安装py2neo,用Python编程对数据库进行增删改查的操作,操作的内容自行决定;以案例二为例,操作如下:
3. 安装Neo4j Pytho驱动包,用Python编程对数据库进行增删改查的操作,操作的内容自行决定;4. 安装py2neo,用Python编程对数据库进行增删改查的操作,操作的内容自行决定;以案例二为例,操作如下:
增加一个人物节点:姓名"小黑子" ;
from py2neo import Graph, Node, Relationship
# 连接到neo4j数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "12345678"), name='neo4j')
# 检查“小黑子”节点是否已经存在
existing_xiaoheizi = graph.nodes.match("Person", name="小黑子").first()
# 如果不存在,则创建新人物节点
if not existing_xiaoheizi:
xiaoheizi = Node("Person", name="小黑子")
graph.create(xiaoheizi)
else:
xiaoheizi = existing_xiaoheizi
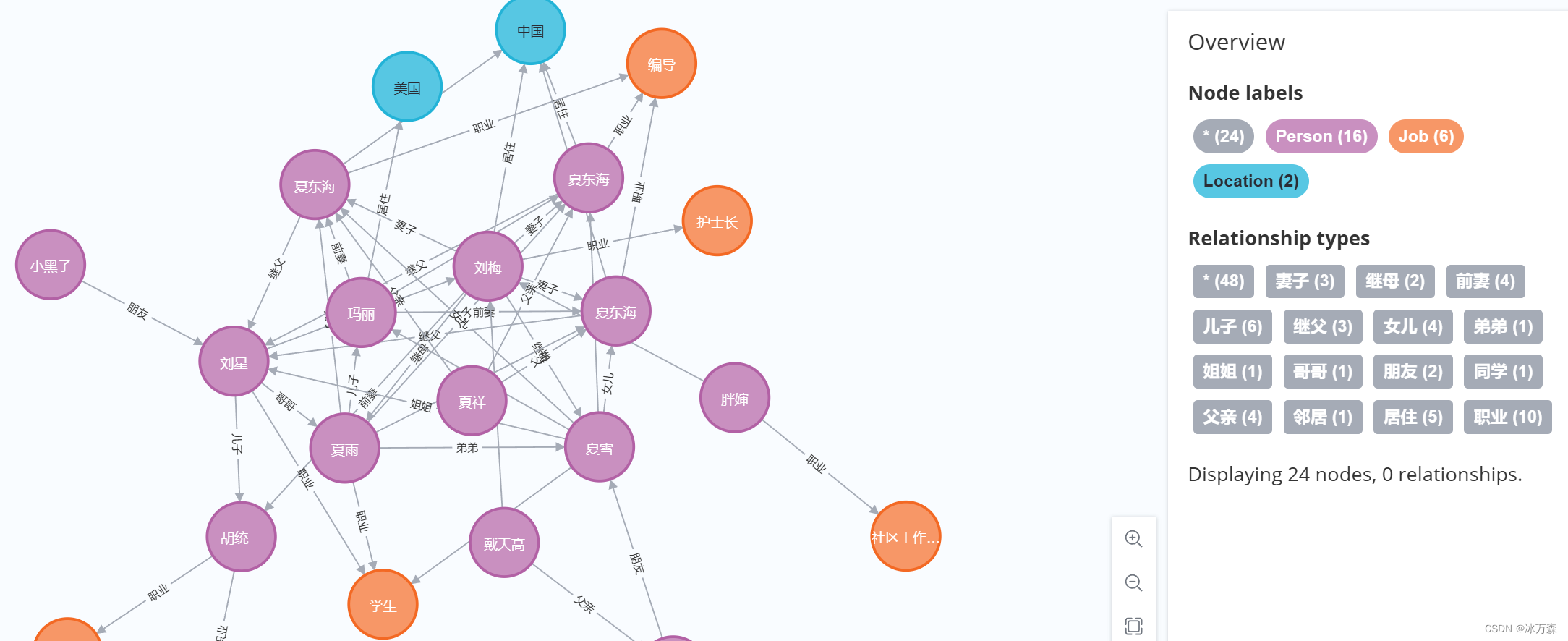
修改节点: "小黑子"的属性:昵称“坤坤”;
# 修改人物属性
graph.run("MATCH (n:Person {name: '小黑子'}) SET n.nickname = '坤坤'")增加关系: "小黑子" -> "朋友" -> "刘星"
# 创建关系
liu_xing = graph.nodes.match("Person", name="刘星").first()
if liu_xing:
relationship = Relationship(xiaoheizi, "朋友", liu_xing)
graph.create(relationship)
查询: "小黑子和刘星的关系是什么?"
# 查询:小黑子和刘星的关系是什么?
relation_query_result = graph.run("MATCH (xiao:Person {name: '小黑子'}), (liu:Person {name: '刘星'}), (xiao)-[r]->(liu) RETURN type(r)").data()
# 输出查询结果
if relation_query_result:
relation_type = relation_query_result[0]['type(r)']
print(f"小黑子和刘星的关系是:{relation_type}")
else:
print("小黑子和刘星之间没有找到直接关系。")

删除关系: "小黑子" -> "朋友" -> "刘星"
# 删除与“小黑子”节点相关的所有关系
graph.run("MATCH (n:Person {name: '小黑子'})-[r]-() DELETE r")
查询: "小黑子和刘星的关系是什么?"
# 查询:小黑子和刘星的关系是什么?
relation_query_result = graph.run("MATCH (xiao:Person {name: '小黑子'}), (liu:Person {name: '刘星'}), (xiao)-[r]->(liu) RETURN type(r)").data()
# 输出查询结果
if relation_query_result:
relation_type = relation_query_result[0]['type(r)']
print(f"小黑子和刘星的关系是:{relation_type}")
else:
print("小黑子和刘星之间没有找到直接关系。")

删除人物节点“小黑子”
# 删除“小黑子”节点
graph.run("MATCH (n:Person {name: '小黑子'}) DELETE n")
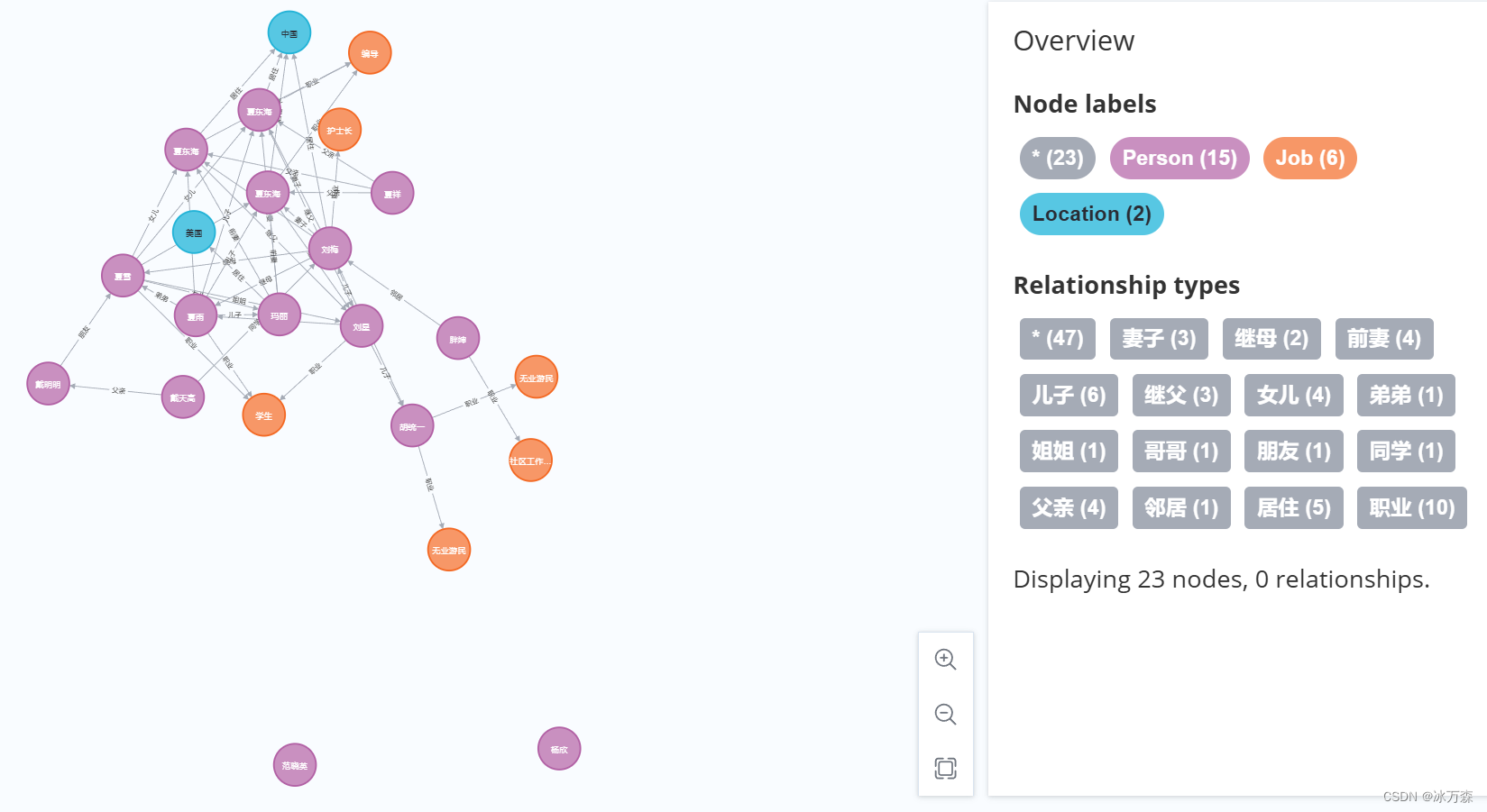
查询:谁的职业是学生?
# 查询:谁的职业是学生?
student_query_result = graph.run("MATCH (p:Person)-[:职业]->(j:Job {title: '学生'}) RETURN p.name").data()
# 输出查询结果
if student_query_result:
students = [student['p.name'] for student in student_query_result]
print(f"以下人物的职业是学生:{', '.join(students)}")
else:
print("没有找到职业是学生的人物。")

四、总结与体会
通过本次实验,我深入了解了Neo4j图数据库的安装、启动、知识图谱的创建、以及使用Cypher语言、Neo4j Python驱动包和py2neo对知识图谱进行访问的方法。以下是我的实验总结与体会:
1. 安装和启动Neo4j:在实验中,我学会了如何下载和安装Neo4j,并成功启动了数据库服务。这为我后续进行知识图谱的创建和访问奠定了基础。
2. 创建知识图谱:通过实验,我掌握了使用Cypher语言创建知识图谱的方法。Cypher语言是Neo4j的查询语言,它具有简洁、易学、易用的特点。我学会了如何定义节点和关系,以及如何为节点和关系添加属性。
3. 使用Cypher语言进行查询:实验中,我使用Cypher语言对知识图谱进行了查询。我学会了如何编写基本的查询语句,如查找节点、关系、路径等,以及如何使用WHERE子句进行条件过滤。
4. 使用Neo4j Python驱动包访问数据库:在实验中,我学会了使用Neo4j Python驱动包访问Neo4j知识图谱。通过编写Python代码,我成功实现了对知识图谱的增删改查操作。这为我后续在实际项目中使用Python操作Neo4j数据库提供了有力支持。
5. 使用py2neo访问数据库:实验中,我还学习了使用py2neo库访问Neo4j知识图谱。py2neo是一个Python库,它提供了更加便捷的方式操作Neo4j数据库。我学会了如何使用py2neo进行节点和关系的创建、更新、删除等操作。
6. 难点与挑战:在实验过程中,我遇到了一些难点和挑战,尤其是在使用Neo4j Python驱动包和py2neo进行知识图谱访问时。通过搜索引擎搜索,大量阅读博客,我逐渐克服了这些困难,掌握了相关技能。
总之,本次实验使我深入了解了Neo4j及其应用,掌握了安装、启动、创建知识图谱、使用Cypher语言、Neo4j Python驱动包和py2neo进行访问的方法。这对我今后在图数据库领域的研究和实践具有重要意义。在今后的学习和工作中,我将继续深入研究Neo4j的相关技术,不断提高自己的技能水平。


















 1218
1218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









