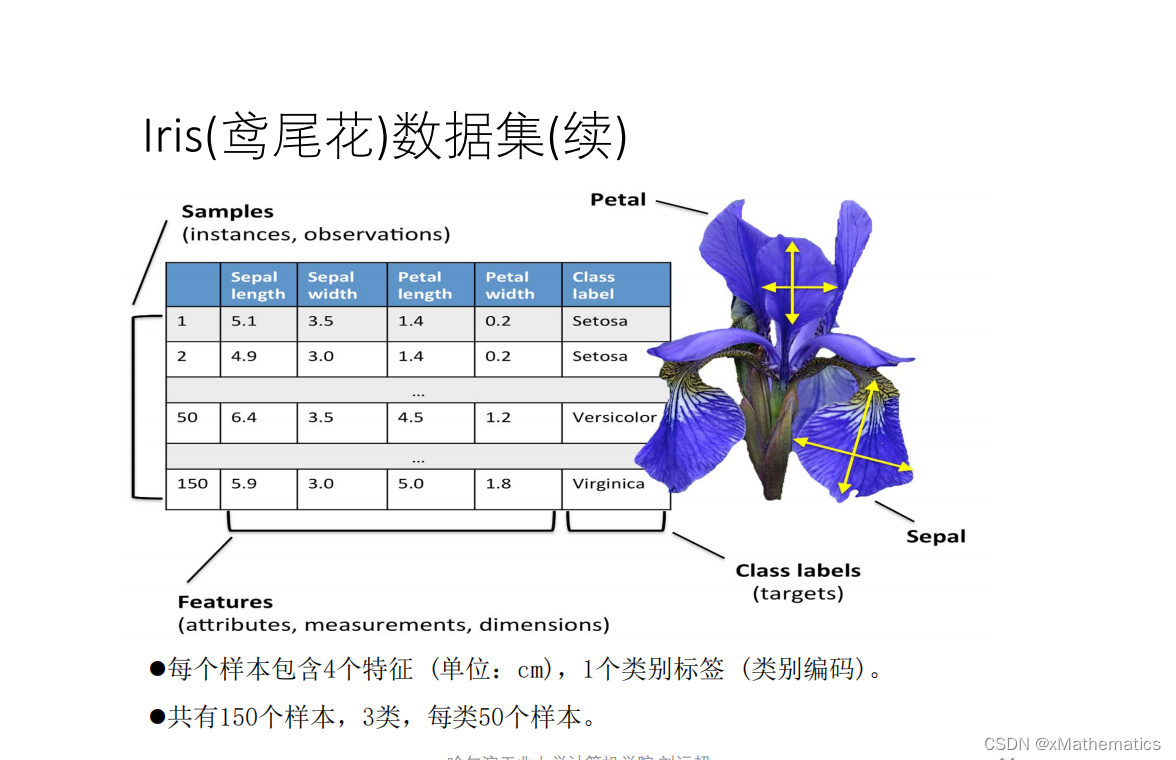
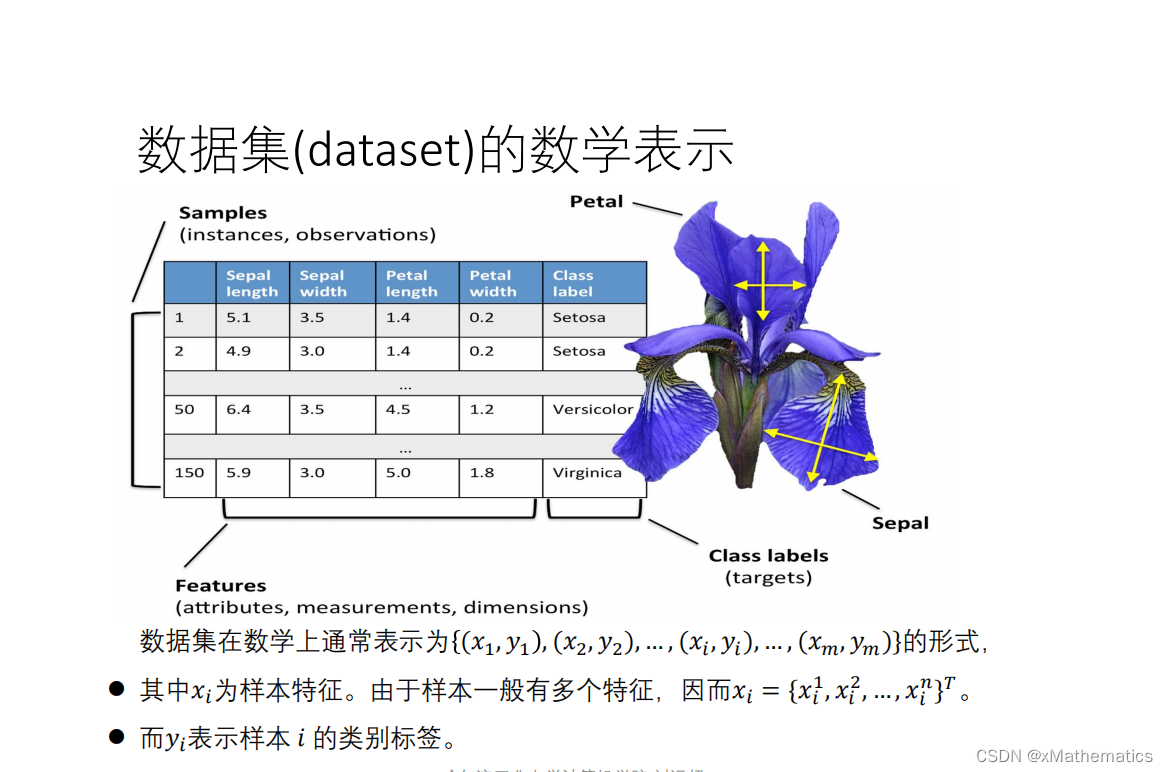
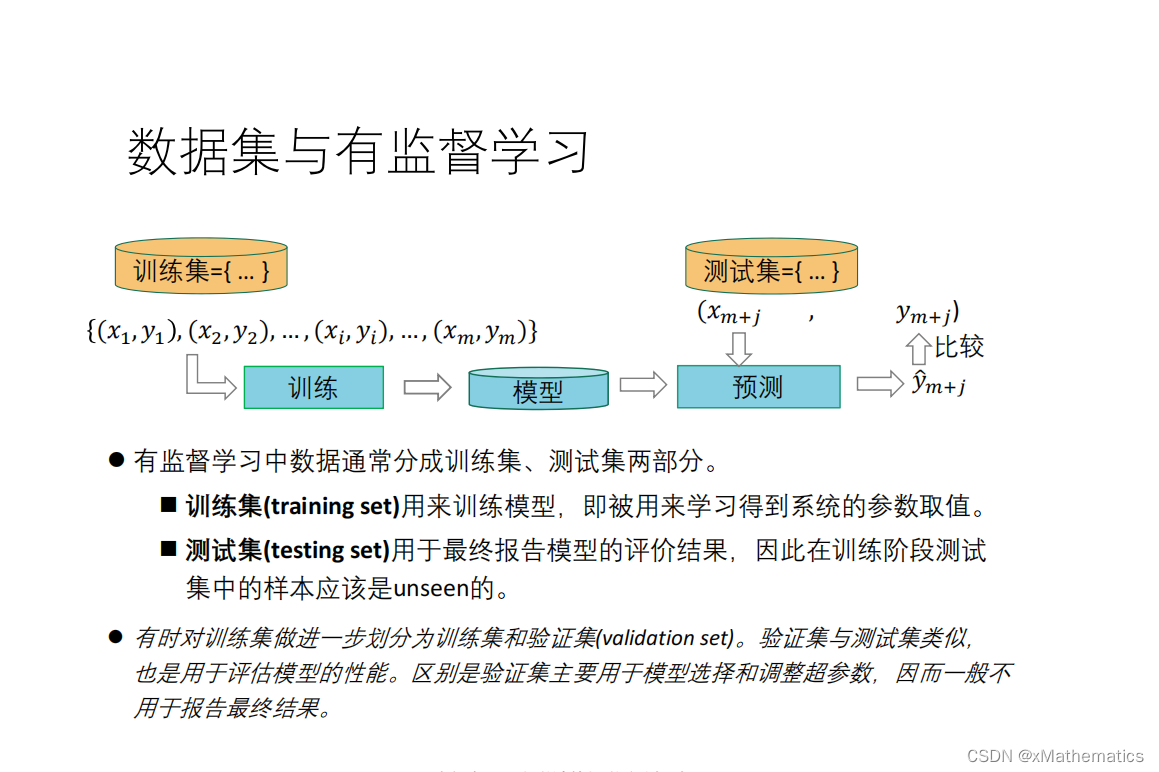
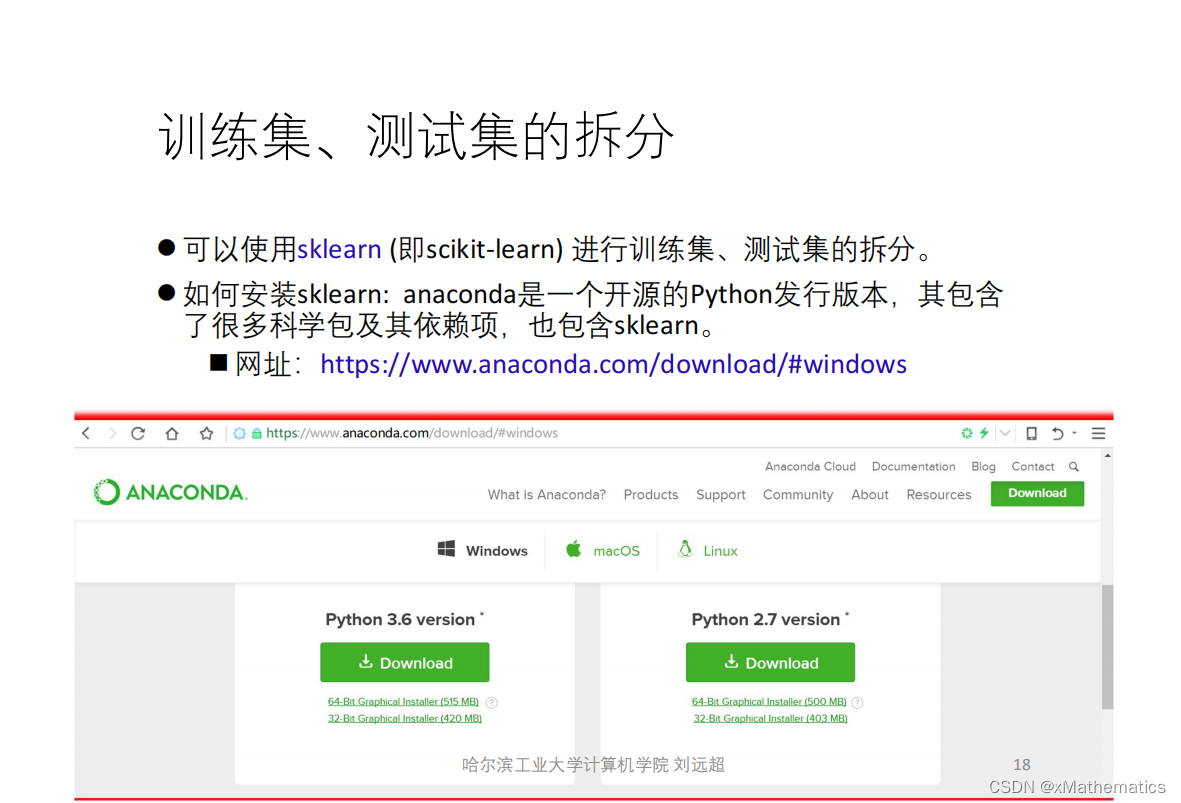
1 鸢尾花数据集 2 数据集的数学表示 3 类别标签(ground truth、gold standard) 4 数据集与有监督学习 5 训练集、测试集的拆分 6 训练集测试集拆分(留出法) 7 K折交叉验证 8 分层抽样策略(Stratified k-fold) 9 用网络搜索来调超参数


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
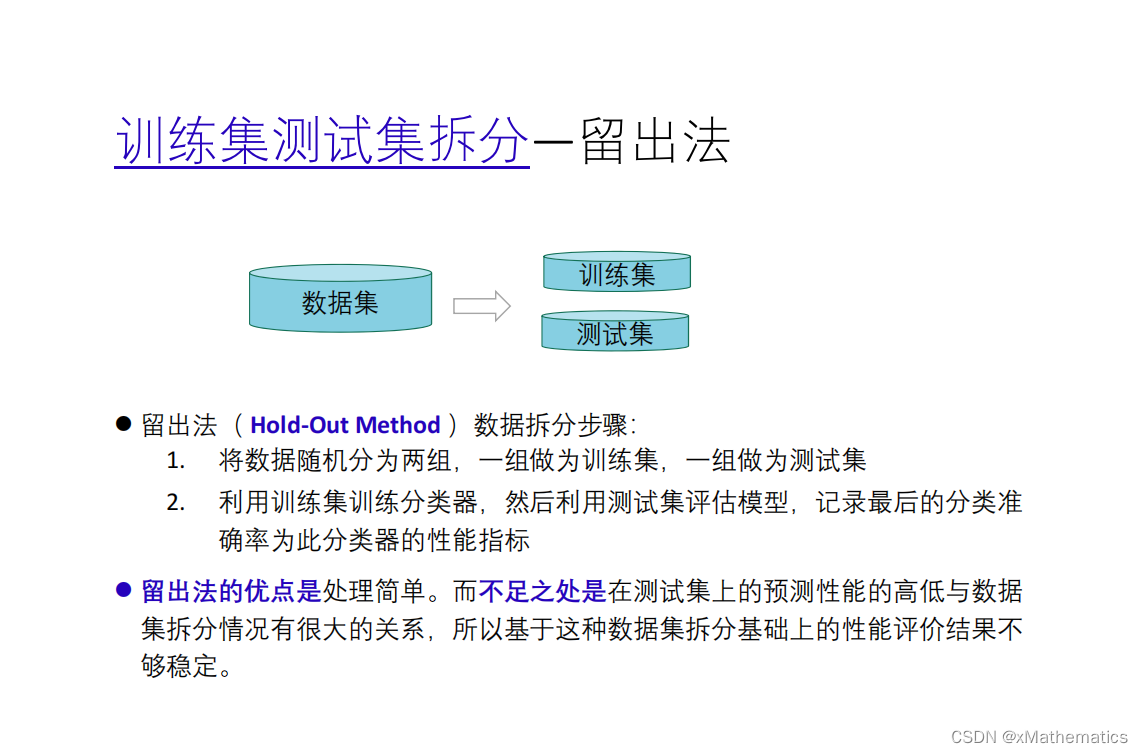
到【灌水乐园】发言











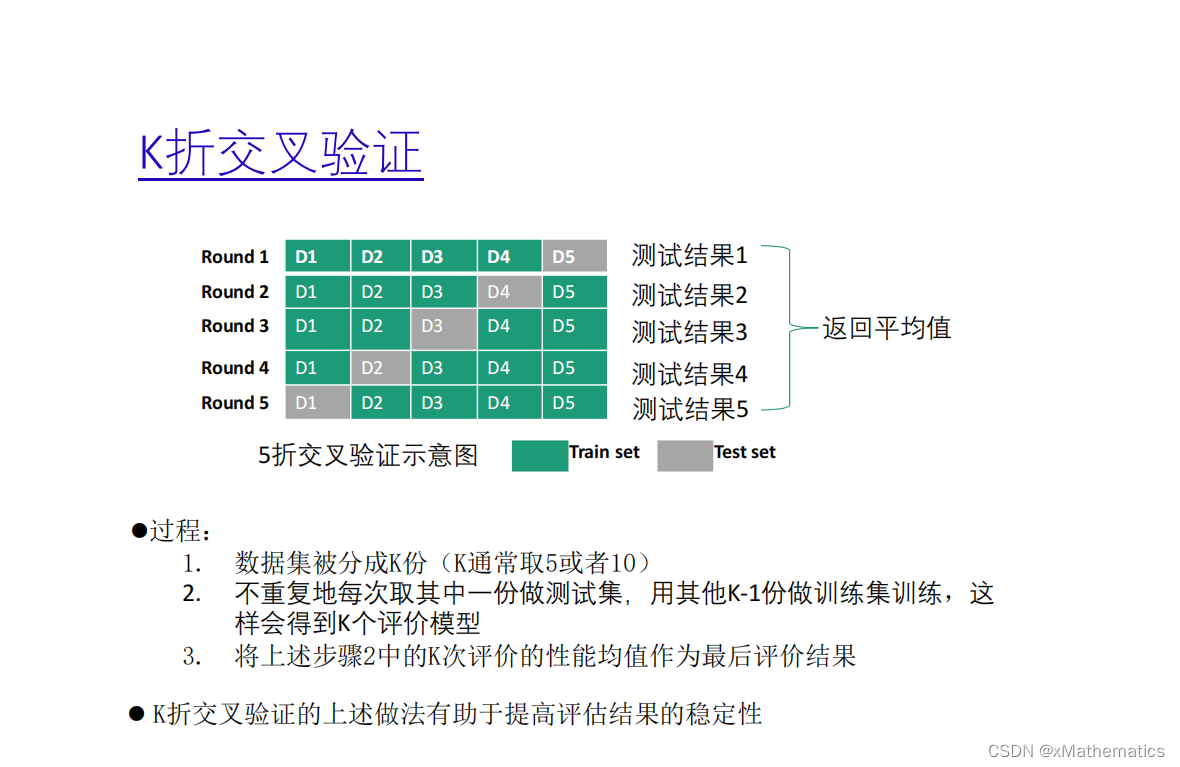
 本文探讨了鸢尾花数据集的数学表示,类别标签的含义,以及它在有监督学习中的应用。深入讲解了训练集与测试集的划分方法,如留出法和K折交叉验证,并介绍了分层抽样策略。同时涵盖了超参数调优的网络搜索技巧。
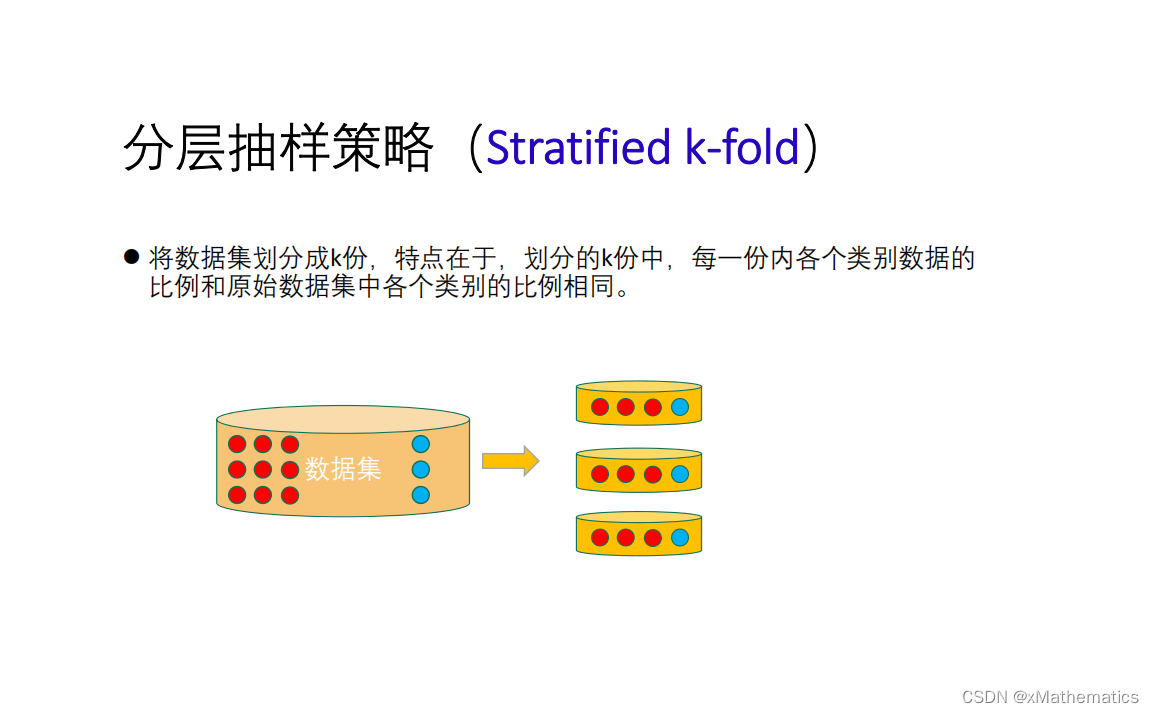
本文探讨了鸢尾花数据集的数学表示,类别标签的含义,以及它在有监督学习中的应用。深入讲解了训练集与测试集的划分方法,如留出法和K折交叉验证,并介绍了分层抽样策略。同时涵盖了超参数调优的网络搜索技巧。



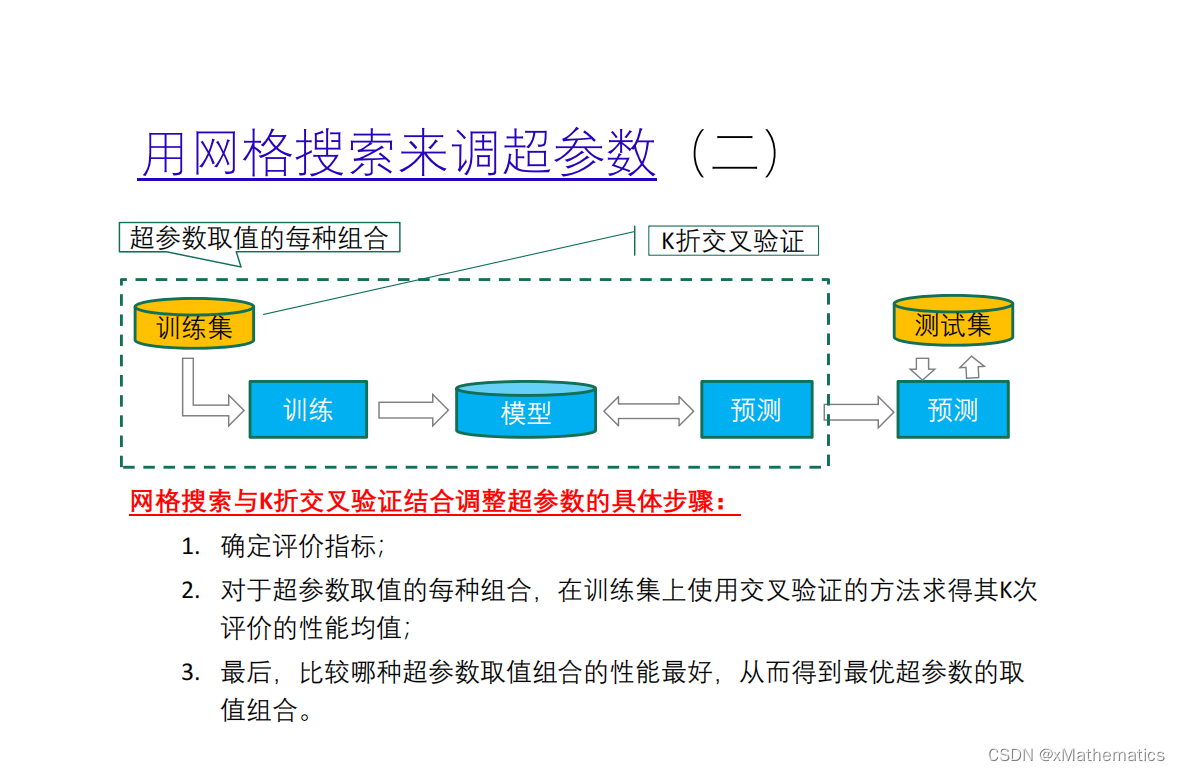


















 285
285







