Say we have a PCFG with the following rules and probabilties:
-
q( S → NP VP ) = 1. 0
-
q( VP → Vt NP ) = 0. 2
-
q( VP → VP PP ) = 0. 8
-
q( NP → NNP ) = 0. 8
-
q( NP → NP PP ) = 0. 2
-
q( NNP → John ) = 0. 2
-
q( NNP → Mary ) = 0. 3
-
q( NNP → Sally ) = 0. 5
-
q( PP → IN NP ) = 1. 0
-
q( IN → with ) = 1. 0
-
q( Vt → saw) = 1. 0
Now say we use the CKY algorithm to find the highest probability parse tree under this grammar for the sentence
We use tparser to refer to the output of the CKY algorithm on this sentence.
(Note: assume here that we use a variant of the CKY algorithm that can return the highest probability parse under this grammar - don't worry that this grammar is not in Chomsky normal form, assume that we can handle grammars of this form!)
The gold-standard (human-annotated) parse tree for this sentence is
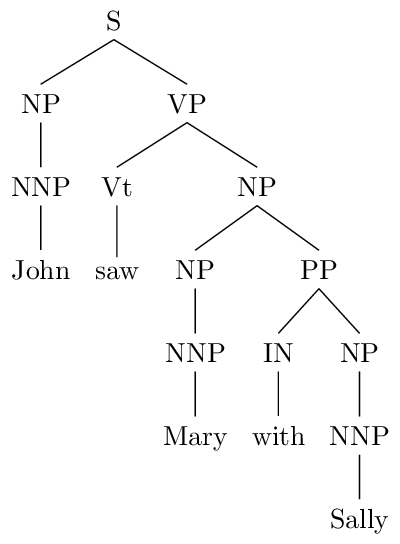
What is the precision and recall of tparser (give your answers to 3 decimal places)?
Write your answer as a sequence of numbers: for example “0.3 0.8” would mean that your precision is 0.3, your recall is 0.8.
Here each non-terminal in the tree, excluding parts of speech, gives a "constituent" that is used in the definitions of precision and recall. For example, the gold-standard tree shown above has 7 constituents labeled S, NP, VP, NP, NP, PP, NP respectively (we exclude the parts of speech NNP, IN, and Vt).


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











 本文深入探讨了上下文无关文法、概率文法模型及其在句法分析中的应用,包括句子的解析树数量计算、概率计算、左分支树概率最大化以及构成成分的确定。
本文深入探讨了上下文无关文法、概率文法模型及其在句法分析中的应用,包括句子的解析树数量计算、概率计算、左分支树概率最大化以及构成成分的确定。






















