




对于一些初学者来说,会因为自己的学艺不精,对jmeter性能测试的机理不够了解,而导致一些理解偏差。比如说将聚合报告上的吐吞率当做服务器的最大吞吐率,而在实际中由于网络带宽原因,本地测试机上测试出的最大吞吐率会可能会远远小于服务器的最大吞吐率。所以本节我将讲述网络带宽是如何影响我们测试数据的,并给出示例和详细的解释。
正文
什么是吞吐率?
吞吐率是指一个业务系统在单位时间内处理事务的总量。在事务的定义中可以是一个请求或者多个请求的集合,在Jmeter中可以用事务控制器(Transaction Controller)来控制。在资源有限的情况下每个系统都会有一个最大的吞吐率。在Jmeter中并发数和吞吐率有一定关系如下图。

从图中可以直观的看到,吞吐率会随着并发数提高的时候增长,但在用户数提高到一定程度时吞吐率不变,此时为系统的最大吞吐率(如例子中100/s)。当我们在本地下测出最大吞吐率时,我们往往会忽略我们本地网络带宽的原因,把测试出的数据当成系统最大的吞吐率。为什么这样说呢?请看下面示例,我将分三种不同网络环境下(WiFi、手机热点、云服务器)以访问百度为例进行测试。这个图的原理我将在系列中之后的章节中分析。
本地WiFi网络下测试结果
200 * 1 * 100(200线程1s内启动循环100次,下同理)
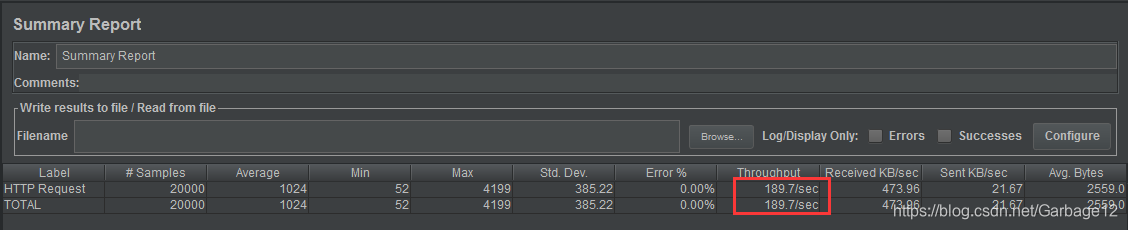
400 * 1 *
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









