 Redis主从复制的实现原理及同步方式
Redis主从复制的实现原理及同步方式




Redis主从复制的实现原理
Redis 的主从复制是指一个 Redis 实例(主节点)可以将数据复制到一个或多个从节点(从节点),从节点从主节点获取数据并保持同步,主从节点之间有两种数据同步方式:
- 全量同步
- 增量同步
主从节点的第一次数据同步就是全量同步,在了解这两种数据同步方式之前,我们先要了解两个概念,主节点master如何判断从节点slave是不是第一次来同步数据?如果不是又该从什么地方开始同步?
- Replicationld:简称replid,是数据集的标记,id一致则说明是同一数据集,每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset.如果slave的offset小于master的offset,说明slave数据落后于master,需要更新
因此slave做数据同步,必须向master声明自己的replicationid和offset,master才可以判断到底需要同步哪些数据,如果同步数据时,从节点的replicationid和主节点的replicationid不一致,说明这是该从节点第一次向主节点同步数据,此时应该进行全量同步
全量同步
全量同步通常是指从节点第一次向主节点发出同步请求,此时主从节点的数据完全不一致,所以主节点要复制全部数据给从节点做同步,
那上面提到的replid就可以让主节点知道从节点是不是第一次同步
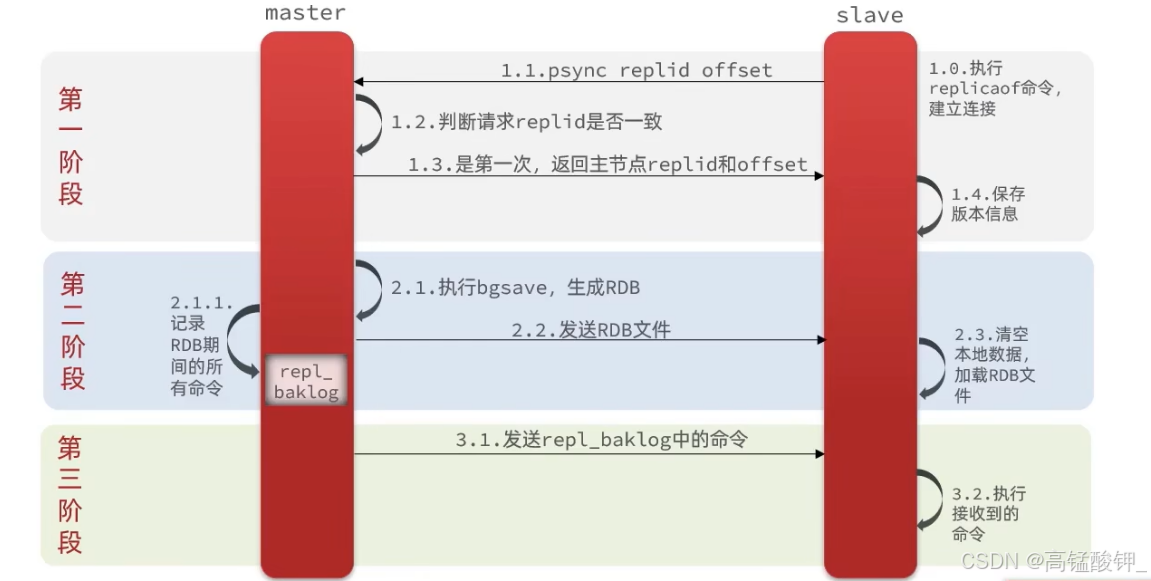
同步流程为:
-
slave节点请求增量同步
-
master节点判断replid,发现不一致,拒绝增量同步
说明这是第一次同步
-
master将完整内存数据生成RDB,发送RDB到slave
RBD就是数据快照,其中保存了主节点全部的数据信息
-
slave清空本地数据,加载master的RDB
-
master将RDB期间的命令记录在repl_baklog,并持续将log中的命
令发送给slave在主节点生成RDB的过程中还会有请求对主节点的数据进行增删改操作,因此repl_baklog就记录了在这期间发生的数据变更,将这部分数据给从节点同步过后,此时主从节点的数据才是完全一致的
增量同步
主从之间的网络可能不稳定,如果连接断开,主节点部分写操作未传递给从节点执行,主从数据就不一致了,此时有一种选择是再次发起全量同步,但是全量同步数据量比较大,非常耗时,因此就会执行增量同步
因为此时已经不是第一个进行同步,所以主从节点replid一定是相同的,此时主节点就不会再发送RDB数据,而是发送未同步部分的repl_baklog数据,那主节点又是怎么知道哪些是同步过,哪些没同步呢?
这就要用到数据偏移量offset,主节点获取从节点的偏移量后就能够将偏移量之后未同步的数据通过repl_baklog发送过去
流程为:
-
slave节点请求增量同步
-
master节点判断replid,发现一致,进行增量同步
-
repl_baklog中找到根据从节点传递来的offset之后的未同步的数据
-
发送offset之后的数据命令完成同步

repl_baklog:
他的本质就是一个数组,大小固定,当数据记录满之后就会从0开始记录,即一种环形记录方式
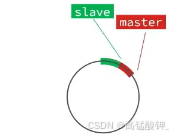
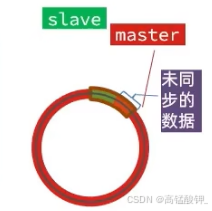
绿色就是从节点的偏移量,红色是主节点,通过这种机制主节点就知道从节点从哪里开始的数据未同步
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步

















 2075
2075



 到【灌水乐园】发言
到【灌水乐园】发言








