






集合
1.集合的来由
-
数组的不足:
-
无法扩展:数组本身的长度是固定的,一旦创建,就无法修改
-
结果:每次要添加一个新元素的时候,就需要创建一个新的数组,长度为原来的数组长度+1,将原来数组中的所有元素都拷贝到新数组中,添加新元素这些操作和真正的业务逻辑无关
-
-
解决:
-
为了解决这一限制,Java 提供了一系列的类,它们被称为集合框架。
-
-
集合和数组的异同:
-
共同点:
-
都是用于存储数据的容器
-
使用容器的原因,就是希望使用有规律的索引、操作方式,操作那些没有规律的元素
-
-
不同点:
-
存储内容的不同
-
数组既可以存储基本类型,也可以存储引用类型
-
集合只能存储引用类型,如果需要存储基本数据类型 ,其实里面存的是包装类对象
-
-
-
存储数量的不同:
-
数组的长度不可变,一旦确定大小就无法改变
-
集合的长度可变,是一个可以伸缩的容器
-
-
方法不同:
-
数组中只有Object中定义的方法,以及有一个length属性
-
集合中可以有很多方法,很丰富
-
-
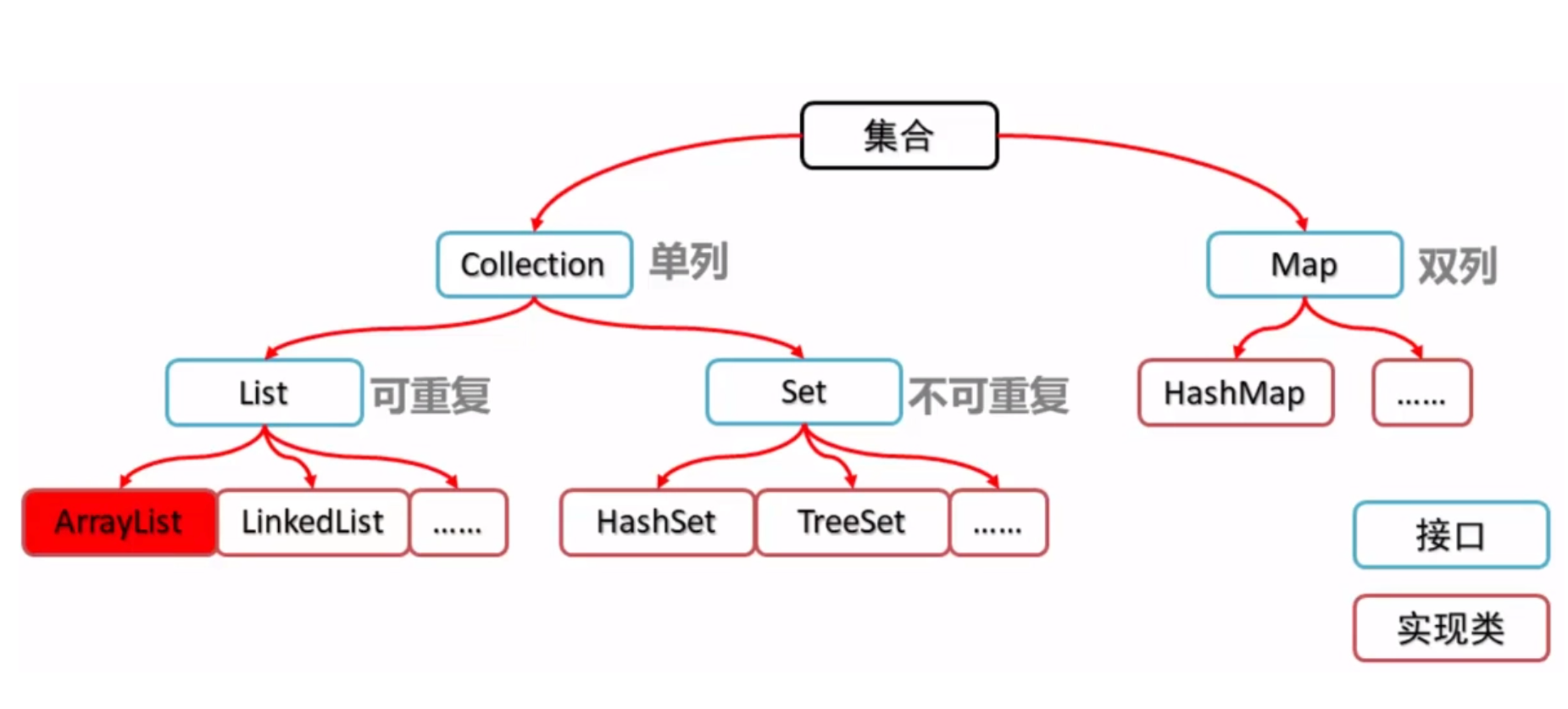
集合的体系结构
-
集合分类:
-
单列集合:每个元素都是一个单独的个体
-
双列集合:每个操作都是针对一对数据来进行的,一对数据作为一个单位,类似字典
-
-
-
集合的体系介绍
-
List
为了实现容器容量可变,提供 List 接口,其中定义了新增元素、删除元素等动态操作容器的方法。List 接口继承自 Collection 接口。
List 下的主要实现类有:ArrayList、LinkedList
-
Set
为了实现容器中元素不可重复,提供 Set 接口,其中同样提供基础的操作容器的方法。Set 接口继承自Collection 接口。
Set 下的主要实现类有:HashSet、TreeSet
-
Map
为了实现关联性数据的存储,提供 Map 接口,也叫双列集合、K-V 集合、键值对集合,其中 Key 不可重复,Map 是 Set 的实现原理,Set 就是单独使用 Map 的 Key 来实现的。
Map 下的主要实现类有:HashMap、TreeMap
-
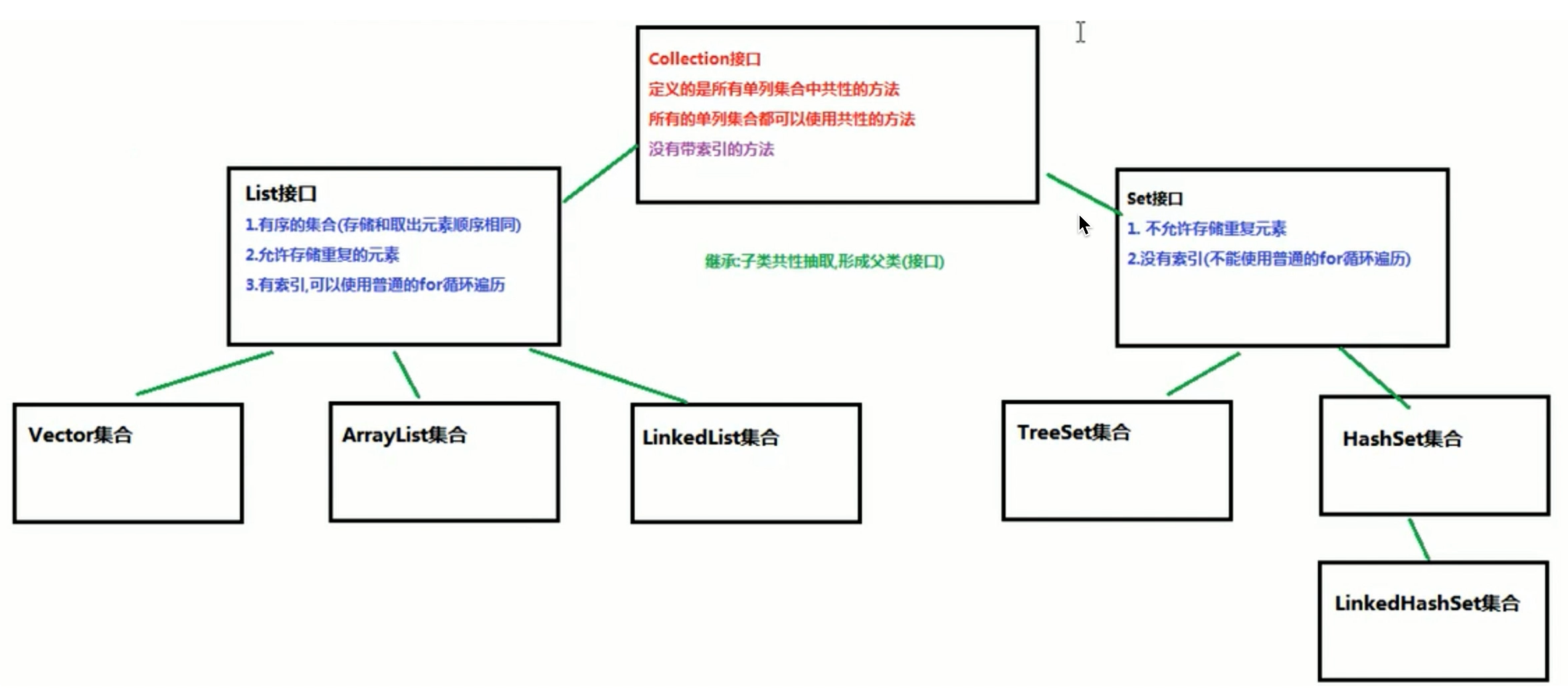
2.Collection
2.1 Collection概述和常用方法
-
单词:收集、集合
-
单列集合的顶层接口,定义的是所有单列集合中共有的功能。
-
-
常用方法:
-
add(Object obj):将obj元素添加到集合中
-
remove(Object obj):将obj元素从集合中删除
-
clear():将集合中的元素清空
-
isEmpty():判断集合中元素是否为空
-
contains(Object obj):判断集合中是否包含obj元素
-
size():返回集合中的元素个数
-
-
示例代码
-
import java.util.Collection; import java.util.ArrayList; /** * Collection概述和常用方法 */ public class Simple01 { public static void main(String[] args) { Collection c1 = new ArrayList(); c1.add("a"); c1.add("b"); c1.add("c"); c1.add("d"); c1.add("xyz"); c1.add(123); System.out.println(c1);//说明重写了集合的toString方法 c1.remove("a"); c1.remove("b"); c1.remove("xyz"); c1.remove(123); System.out.println(c1); System.out.println(c1.contains("c"));//true System.out.println(c1.contains(123));//false System.out.println(c1.isEmpty()); System.out.println(c1.size()); c1.clear(); System.out.println(c1); System.out.println(c1.isEmpty()); } }
2.2 Collection的第一种遍历方式
-
转成数组,通过遍历数组的方式,来间接的遍历集合,Object[] toArray():将调用者集合转成Object类型的数组
-
示例代码:
-
/** * Collection的第一种遍历方式 toArray(); */ public class Simple02 { public static void main(String[] args) { // test1(); test2(); } public static void test1() { Collection c1 = new ArrayList(); c1.add(111); c1.add(222); c1.add(333); c1.add(444); c1.add("aaa"); c1.add("bbb"); System.out.println(c1); // Object[] toArray(): Object[] objects = c1.toArray(); for (Object object : objects) { System.out.println(object); } } public static void test2() { Collection c2 = new ArrayList(); c2.add(new Person("zs")); c2.add(new Person("ls")); c2.add(new Person("ww")); // [Person{name='zs'}, Person{name='ls'}, Person{name='ww'}] System.out.println(c2); Object[] objects = c2.toArray(); for (Object object : objects) { // System.out.println(object); // 如何只输出name的值? // System.out.println(object.getName()); // 向下转型 if (object instanceof Person) { Person object1 = (Person) object; System.out.println(object1.getName()); } } } } class Person { private String name; public Person(String name) { this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + '}'; } }
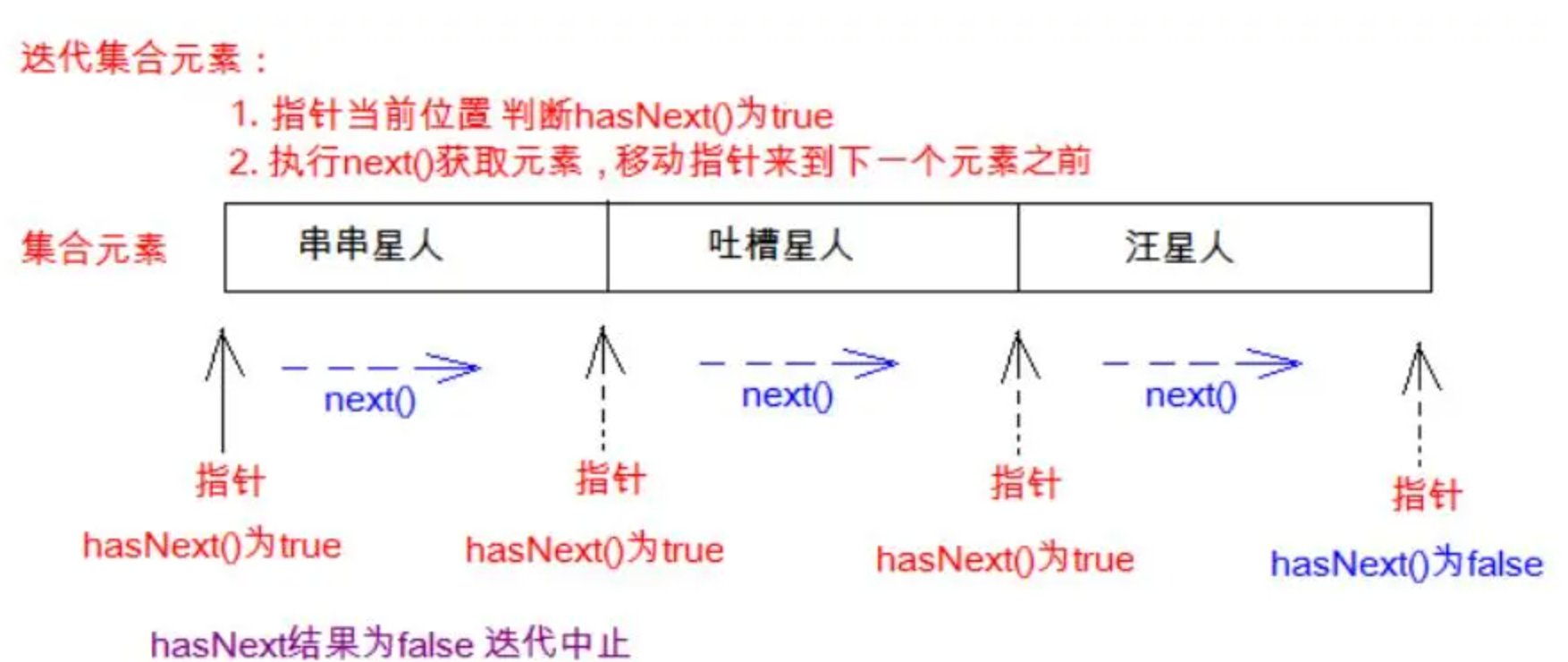
2.3 集合遍历的第二种方式:迭代器
-
迭代:更迭、更新换代,有从某一个到下一个的过程的含义
-
迭代器:专门用于将集合中的元素,一个到另一个逐个进行迭代的对象
-
获取:集合自己内部就有一个可以迭代自己的对象,从集合对象中获取即可
-
语法:
-
类型 Iterator it = collection.iterator()
-
-
迭代器的使用:
-
方法iterator() 返回的是一个Iterator接口的实现类对象,可以使用的就是Iterator接口中的方法:
-
hasNext():判断集合中是否还有下一个元素
-
next():获取集合中的下一个元素
-
remove():删除迭代器对象正在迭代的那个对象
-
示例代码
-
-
执行方式
-
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* 集合遍历的第二种方式:迭代器
*/
public class Simple04 {
public static void main(String[] args) {
// test1();
// test2();
// test3();
test4()
}
public static void test1() {
Collection c1 = new ArrayList();
c1.add(123);
c1.add(456);
c1.add(789);
Iterator iterator = c1.iterator();
System.out.println(iterator.hasNext());
System.out.println(iterator.next());
System.out.println(iterator.hasNext());
System.out.println(iterator.next());
System.out.println(iterator.hasNext());
System.out.println(iterator.next());
System.out.println(iterator.hasNext());
System.out.println(iterator.next());
}
public static void test2() {
Collection c2 = new ArrayList();
c2.add(123);
c2.add(456);
c2.add(789);
Iterator iterator = c2.iterator();
while (iterator.hasNext()) {
Integer integer = (Integer) iterator.next();
System.out.println(integer);
}
}
public static void test3() {
Collection c3 = new ArrayList();
c3.add(new Person("zs"));
c3.add(new Person("ls"));
c3.add(new Person("ww"));
Iterator iterator = c3.iterator();
while (iterator.hasNext()) {
Person p = (Person) iterator.next();
System.out.println(p.getName());
}
}
static void test4 () {
Collection c =new ArrayList();
for (int i = 0; i < 50; i++) {
c.add(i);
}
// for (Object o : c) {
// if (o.equals(10) ) {
c.remove(o); // 触发异常
// }
// System.out.println(o);
// }
Iterator<Integer> iterator = c.iterator();
while (iterator.hasNext()) {
int i = iterator.next();
if (i == 10) {
iterator.remove();
System.out.println("ok");
}
System.out.println(i);
}
System.out.println(c);
}
}3.List
3.1概述
-
是Collection的一个子接口
-
特点:
-
有序:每个元素都有自己的位置(存储的顺序与取出的顺序是一致的)
-
有索引
-
可以重复
-
-
特有方法:
-
add(int index, Object obj):在指定索引上,添加指定的元素
-
remove(int index):删除指定索引上的值
-
set(int index, Object obj):将指定索引上的值,修改为指定的值
-
get(int index):根据给定的索引,获取对应位置的值
-
-
代码示例
-
import java.util.ArrayList; import java.util.List; public class Simple05 { public static void main(String[] args) { List list = new ArrayList(); list.add(0, "abc"); list.add(1, "def"); list.add(2, "ghi"); System.out.println(list); list.remove(0); System.out.println(list); list.set(0, "abc"); System.out.println(list); System.out.println(list.get(1)); } }
3.2 第三种遍历方式
-
可以通过集合的size方法获取list集合索引的范围,根据索引通过get方法可以获取指定索引的值。
-
代码示例
-
import java.util.ArrayList; import java.util.List; public class Simple06 { public static void main(String[] args) { List list = new ArrayList(); list.add("a"); list.add("b"); list.add("c"); list.add("d"); list.add("e"); for (int i = 0; i < list.size(); i++) { // System.out.println(list.get(i)); String s = (String) list.get(i); System.out.println(s); } } }
3.3 List的实现类
-
概述
-
List只是一个接口,根据底层实现方式的不同,具有不同的实现类
-
ArrayList:数组实现,顺序存储
-
LinkedList:节点实现,链式存储
-
Vector:数组实现,顺序存储
-
在jdk1.0版本出现,现在这个类已经过时,在jdk1.2之后,被ArrayList取代
-
特点:
-
线程安全,效率较低
-
顺序存储,增删较慢
-
-
-
特有方法:
-
addElement(Object obj):添加元素
-
removeElement(Object obj):删除元素
-
elements():获取Vector集合的枚举对象,用于遍历集合
-
-
特有遍历方式:
-
使用elements方法获取Enumeration对象
-
使用Enumeration对象的hasMoreElements方法判断是否有下一个元素
-
如果有下一个元素,就使用nextElement方法来获取下一个元素
-
-
示例代码
-
import java.util.Vector; import java.util.Enumeration; /** * Vector */ public class VectorDemo { public static void main(String[] args) { Vector v1 = new Vector(); v1.addElement(123); v1.addElement(456); v1.addElement("abc"); v1.addElement("xyz"); //elements获取用于迭代的枚举对象 Enumeration en = v1.elements(); //使用循环,判断是否有下一个元素 while (en.hasMoreElements()) { System.out.println(en.nextElement()); } } }
-
3.4 ArrayList
ArrayList 的底层实现方式为数组。
-
也是List的一个实现类
-
没有什么特有方法,只是List的实现类
-
ArrayList 的底层实现方式为数组。
-
存储方式:
-
数组实现,顺序存储
-
-
特点:数据是互相挨着连续的
-
查询、修改较快, 可以根据索引查询和修改
-
插入、删除较慢
-
尾增尾删效率不低的
-
-
代码示例:见List-->概述-->代码示例
-
add(int index, Object obj):在指定索引上,添加指定的元素
-
remove(int index):删除指定索引上的值
-
set(int index, Object obj):将指定索引上的值,修改为指定的值
-
get(int index):根据给定的索引,获取对应位置的值
-
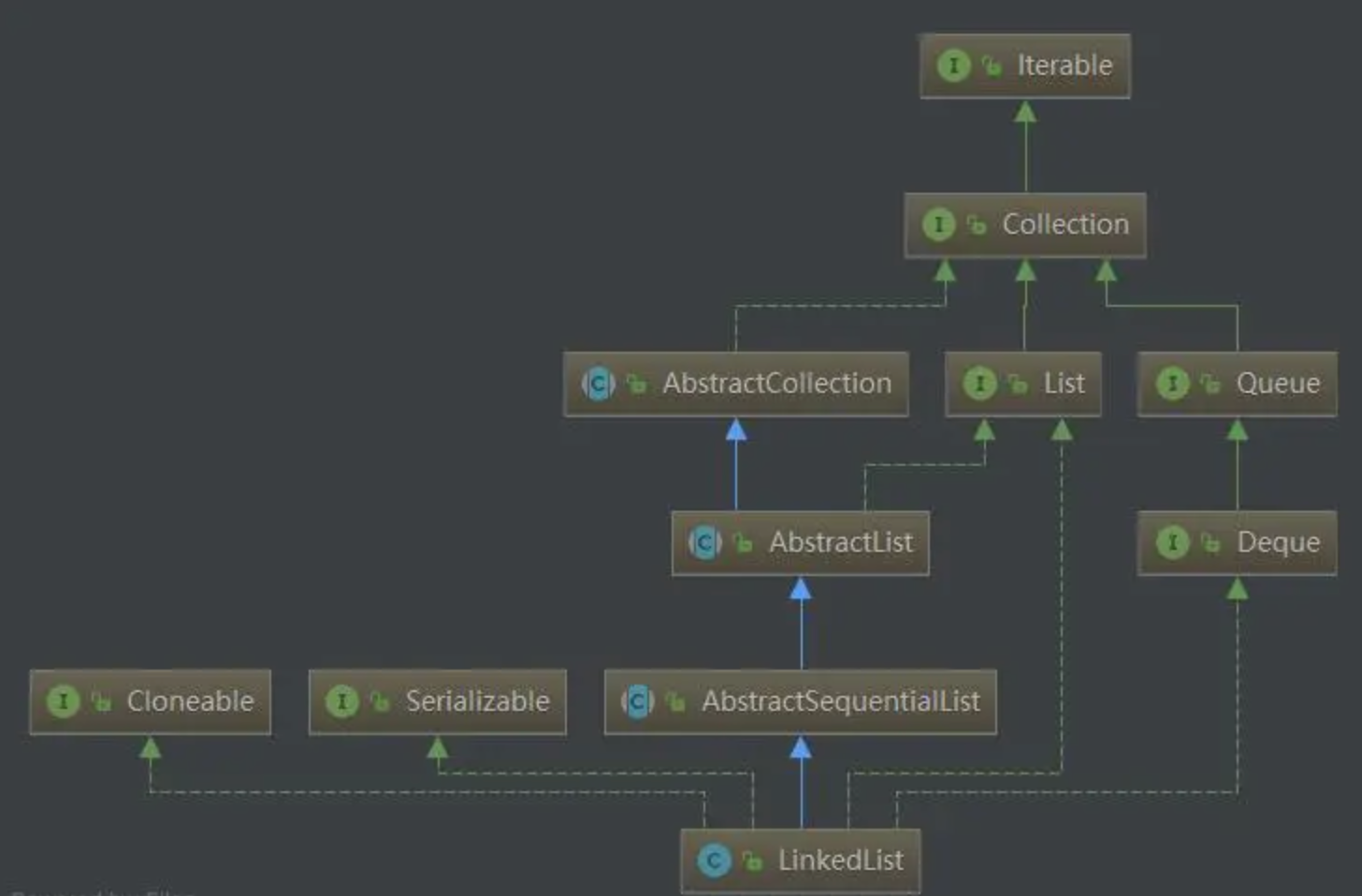
3.5 LinkedList
LinkedList 的底层实现方式为双向链表。
-
List的一个实现类
-
LinkedList 的底层实现方式为双向链表。
-
存储方式:
-
节点实现,链式存储
-
不通过物理内存位置的相邻,来表示逻辑顺序的相邻
-
每个元素都存储在一个节点中,节点除了元素数据本身以外,还需要存储下一个元素的内存地址
-
-
视图:
-
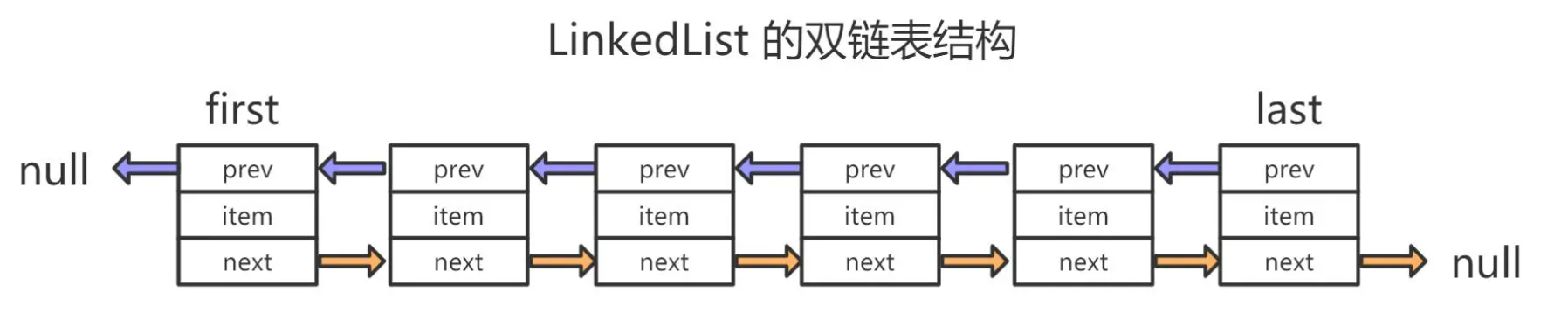
-
特点:
-
查询速度慢:要根据前面的节点来获取后一个节点的地址,前面所有节点都要访问一遍,节点数量越多,查询速度越慢
-
增删速度快:增删一个元素,只需要修改新增元素前后的两个节点的引用域即可,与集合本身的元素个数无关。
-
LinkedList的特有方法 (使用时请注意多态)
-
由于在LinkedList中,维护了链表的头和尾节点的对象地址,所以操作头部和尾部非常容易,提供了大量的操作头和尾的方法。
-
addFirst(Object obj):在头部添加元素
-
addLast(Object obj):在尾部添加元素
-
removeFirst():删除头部元素
-
removeLast():删除尾部元素
-
getFirst():获取头部元素
-
getLast():获取尾部元素
-
-
代码示例:
-
import java.util.LinkedList; public class Simple07 { public static void main(String[] args) { LinkedList lk = new LinkedList(); lk.addFirst("aaa"); lk.addFirst("bbb"); System.out.println(lk); lk.addLast("ccc"); lk.addLast("ddd"); System.out.println(lk); Object o = lk.removeFirst(); System.out.println(o); System.out.println(lk); Object o1 = lk.removeLast(); System.out.println(o1); System.out.println(lk); System.out.println(lk.getFirst()); System.out.println(lk.getLast()); } }
-
4.泛型
4.1泛型的概述和使用【熟练掌握】
-
泛型:广泛的类型,在定义一个类的时候,类型中有些方法参数、返回值类型不确定,就使用一个符号来表示那些尚未确定的类型,这个符号,就称为泛型。
-
Java 泛型有三种使用方式:泛型类、泛型方法、泛型接口。
-
使用:对于有泛型的类型,在这些类型后面跟上尖括号,尖括号里面写上泛型的确定类型
(在使用某个类创建对象时,已经可以确定这个具体的类型了,那么就直接写出具体类型)
-
例如:ArrayList<Integer> al = new ArrayList<>();
-
泛型的好处:
-
提高了数据的安全性,将运行时的问题,提前暴露在编译时期
-
避免了强转的麻烦
-
-
注意事项:
-
前后一致:在创建对象时,赋值符号前面和后面的类型的泛型,必须一致
-
泛型推断:如果前面的引用所属的类型已经写好了泛型,后面创建对象的类型就可以只写一个尖括号,尖括号中可以不写任何内容。<>特别像菱形,称为“菱形泛型”,jdk1.7特性
-
代码示例
-
import java.util.ArrayList; import java.util.List; /** * 泛型的概述和使用 */ public class Simple08 { public static void main(String[] args) { // test1(); // 不使用泛型 // test2(); // 使用泛型 Animal<Integer> animal = new Animal(); animal.setName("zs"); animal.setAge(20); } public static void test2() { // 使用泛型 List<Integer> list = new ArrayList(); list.add(111); list.add(222); // list.add("aaa"); for (int i = 0; i < list.size(); i++) { Integer integer = (Integer) list.get(i); System.out.println(integer); } } public static void test1() { // 不使用泛型 List list = new ArrayList(); list.add(111); list.add(222); list.add("aaa"); for (int i = 0; i < list.size(); i++) { Integer integer = (Integer) list.get(i); System.out.println(integer); } } } class Animal<T> { private String name; private T age; public String getName() { return name; } public void setName(String name) { this.name = name; } public T getAge() { return age; } public void setAge(T age) { this.age = age; } } public class Simple { public static void main(String[] args) { Simple simple = new Simple(); simple.test1(12,"zs"); } public <T extends CharSequence,K> T test1 (K k,T t) { System.out.println(k); System.out.println(t); return t; } }
-
5.Set
5.1 Set的概述
-
Set是Collection的另一个子接口
-
特点:
-
无序:没有任何前后的分别,所有的元素没有位置的概念,所有的元素都在集合中
-
没有索引:集合中没有任何位置,元素也就没有位置的属性
-
不能重复:没有位置的区分,相同值的元素没有任何分别,所以不能重复,数据唯一
-
-
Set的实现类:
-
HashSet:使用哈希表(查询的速度非常快)的存储方式存储元素的Set集合
-
哈希表存储原理(数组+链表/红黑树)
-
-
存储特点:
-
相同的元素无法存储进Set集合
-
集合本身不保证顺序:存储的顺序和取出的顺序不保证一致
-
-
示例代码
-
/** * Set的概述 */ public class Simple09 { public static void main(String[] args) { Set<String> set = new HashSet(); set.add("aaa"); set.add("bbb"); set.add("cccc"); set.add("ddd"); set.add("aaa"); System.out.println(set); // Set 无法使用get(索引) 需要转成List并从List获取指定索引 ArrayList<String> strings = new ArrayList<>(set); System.out.println(strings.get(2)); } }
5.2 Set集合的遍历
-
没有自己特有的方法,只能使用Collection接口中定义的方法,只能使用Collection的遍历方式
-
第一种:转成数组,toArray(),不带泛型的转数组,得到的是Object类型的数组。
-
第二种:迭代器
-
第三种:增强for循环
-
本质:
-
底层还是迭代器,只不过使用这种格式更加简洁
-
注意事项:
-
使用增强for,没有拿到元素的索引,无法修改集合或者数组中的元素值
-
-
-
-
示例代码1:
-
import java.util.Arrays; import java.util.HashSet; import java.util.Set; /** * Set集合的遍历转数组 代码示例1 */ import java.util.HashSet; import java.util.Set; public class Simple10 { public static void main(String[] args) { Set<String> set = new HashSet(); set.add("aaa"); set.add("bbb"); set.add("ccc"); set.add("ddd"); Object[] objects = set.toArray(); for (int i = 0; i < objects.length; i++) { System.out.println(objects[i]); } } } -
代码示例2:
-
import java.util.HashSet; import java.util.Iterator; import java.util.Set; /** * Set集合的遍历 代码示例2 */ public class Simple11 { public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("abc"); set.add("aa"); set.add("bb"); set.add("cc"); set.add("qq"); set.add("xyz"); Iterator<String> it = set.iterator(); while(it.hasNext()) { String str = it.next(); System.out.print(str + " "); } } } -
代码示例3:
-
import java.util.HashSet; import java.util.Iterator; import java.util.Set; /** * Set集合的遍历 代码示例3 */ public class Simple12 { public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("abc"); set.add("aa"); set.add("bb"); set.add("cc"); set.add("qq"); set.add("xyz"); for (String str : set) { System.out.print(str + " "); } System.out.println(); } } -
HashSet 的底层实现方式为哈希表。
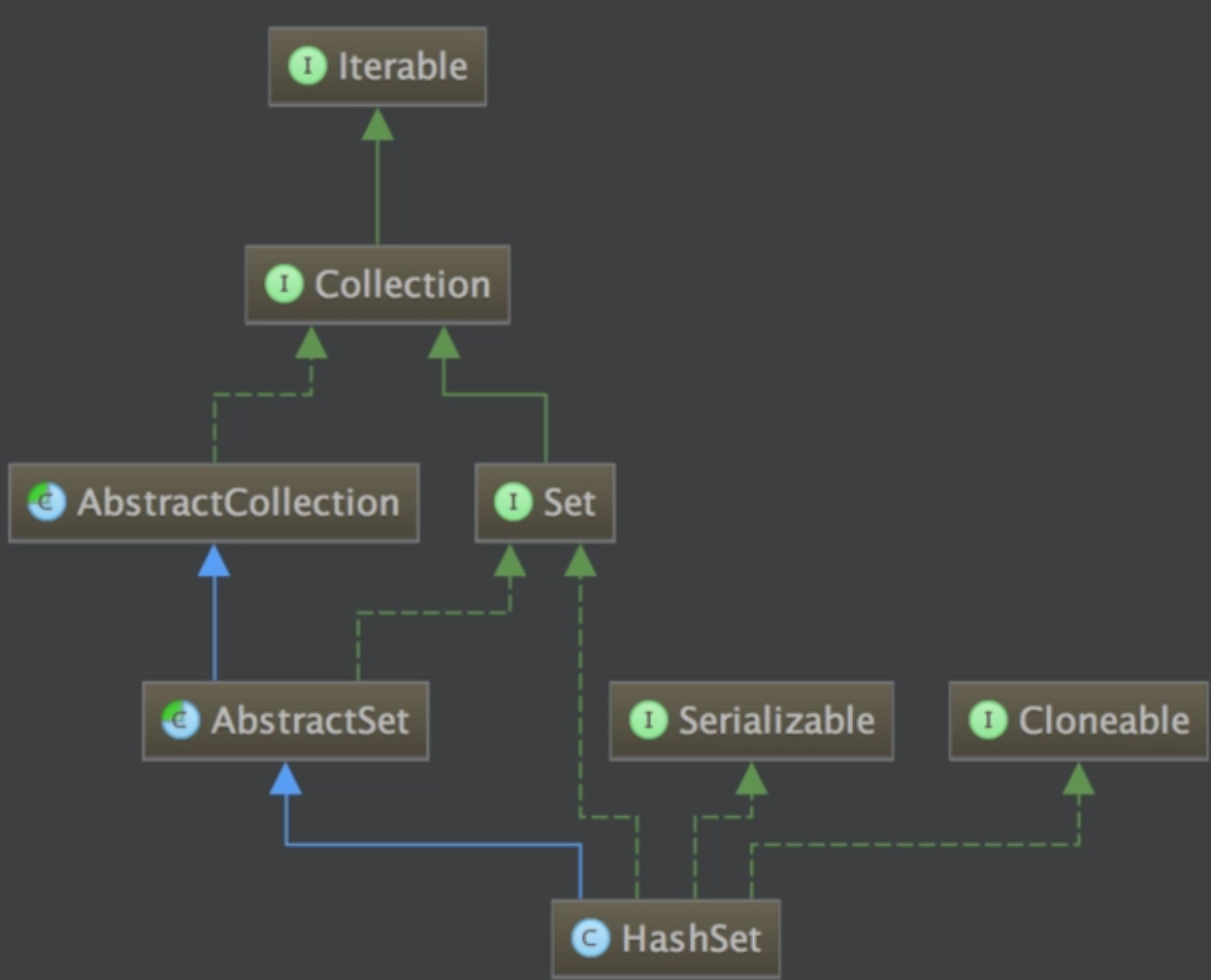
-
HashSet是如何使用哈希表存储数据的?
-
Jdk1.8以前哈希表=数组+链表
-
Jdk1.8以后哈希表=(数组+链表/红黑树)
-
HashSet原理
-
我们使用Set集合都是需要去掉重复元素的,如果在存储的时候逐个equals()比较,效率比较低,哈希算法提高了去重复的效率,降低了使用equals()方法的次数。
-
当HashSet调用add()方法存储对象的时候,先调用对象的hashCode()方法得到一个哈希值,然后在集合中查找是否有哈希值相同的的对象,如果没有哈希值相同的对象就直接存入集合;如果有哈希值相同的对象,就和哈希值相同的对象逐个进行equals()方法比较,比较结果为false就存入集合,true就不存入集合。
-
-
import java.util.HashSet; /** * @author Petrel */ public class HashSetDemo { public static void main(String[] args) { public static void main(String[] args) { Set<String> set = new HashSet<>(); String s1 = new String("abc"); String s2 = "abc"; set.add(s1); set.add(s2); System.out.println(s1.hashCode()); System.out.println(s2.hashCode()); // 96354 System.out.println(set); set.add("重地"); set.add("通话"); System.out.println("重地".hashCode()); System.out.println("通话".hashCode()); //1179395 System.out.println(set); } } }
5.3 HashSet存储自定义类型的元素
-
实验过程: HashSet存储自定义类型的元素,发现《没有保证》元素的唯一性
-
代码示例:
-
/** * HashSet存储自定义类型的元素 */ import java.util.HashSet; import java.util.Set; public class Simple13 { public static void main(String[] args) { HashSet<Person1> set = new HashSet<>(); Person1 p1 = new Person1("zhangsan", 13); 0 Person1 p2 = new Person1("zhangsan", 13); 0 Person1 p3 = new Person1("zhangsan", 18); 0 Person1 p4 = new Person1("lisi", 18); set.add(p1); set.add(p2); set.add(p3); set.add(p4); for (Person1 person1 : set) { System.out.println(person1); } } } class Person1 { private String name; private int age; public Person1(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } -
保证元素唯一性的操作原理
-
重写hashCode (hashCode返回对象的哈希码值,确定对象的地址)
-
相同的对象,一定要有相同的哈希值
-
不同的对象,尽量有不同的哈希值
-
结论:相同hash值 无法确定是相同对象
-
-
-
重写equals方法:
-
比较的就是各个对象的属性值,是否全都相同
-
-
代码示例:
-
import java.util.HashSet; import java.util.Objects; /** * @author Petrel */ public class Simple13 { public static void main(String[] args) { HashSet<Person1> set = new HashSet<>(); Person1 p1 = new Person1("zhangsan", 13); Person1 p2 = new Person1("zhangsan", 13); Person1 p3 = new Person1("zhangsan", 18); Person1 p4 = new Person1("lisi", 18); set.add(p1); set.add(p2); set.add(p3); set.add(p4); for (Person1 person1 : set) { System.out.println(person1); } // System.out.println(p1.hashCode()); // System.out.println(p2.hashCode()); // System.out.println(p3.hashCode()); // System.out.println(p4.hashCode()); } } class Person1 { private String name; private int age; public Person1(String name, int age) { this.name = name; this.age = age; } public Person1() { } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person1{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person1 person1 = (Person1) o; return age == person1.age && Objects.equals(name, person1.name); } @Override public int hashCode() { return Objects.hash(name, age); } }
-
自定义对象存储HashSet去重的步骤
-
类中必须重写hashCode()和equals()方法
-
hashCode():属性相同的对象返回值必须相同,属性不同的返回值尽量不同(提高效率)
-
equals():属性相同返回true,属性不同返回false,返回false的时候存储到集合
-
可使用编译器直接重写以上2个方法。
-
5.4 LinkedHashSet
-
是HashSet的一个子类,继承了HashSet,与HashSet保证元素唯一的原理相同。
-
底层实现是哈希表(数组+链表/红黑树)+链表。比HashSet多一个链表,负责记录元素的存储顺序,保证元素有序。
-
将每个元素在存储的时候,都记录了前后元素的地址,就是存储在哈希表之外的链表中
-
效果:
-
可以根据存储元素的顺序,将元素取出
-
-
应用:
-
既需要保证元素的唯一,又需要保证原来的顺序,就可以考虑LinkedHashSet类型
-
-
示例代码
-
import java.util.LinkedHashSet; /** * LinkedHashSet */ public class Simple14 { public static void main(String[] args) { LinkedHashSet<String> lhs = new LinkedHashSet<>(); lhs.add("abc"); lhs.add("abc"); lhs.add("abc"); lhs.add("xyz"); lhs.add("xyz"); lhs.add("qq"); lhs.add("123"); lhs.add("123"); lhs.add("123"); System.out.println(lhs); [abc, xyz qq 123] } }
5.5 TreeSet
-
TreeSet 的底层实现方式为红黑树。
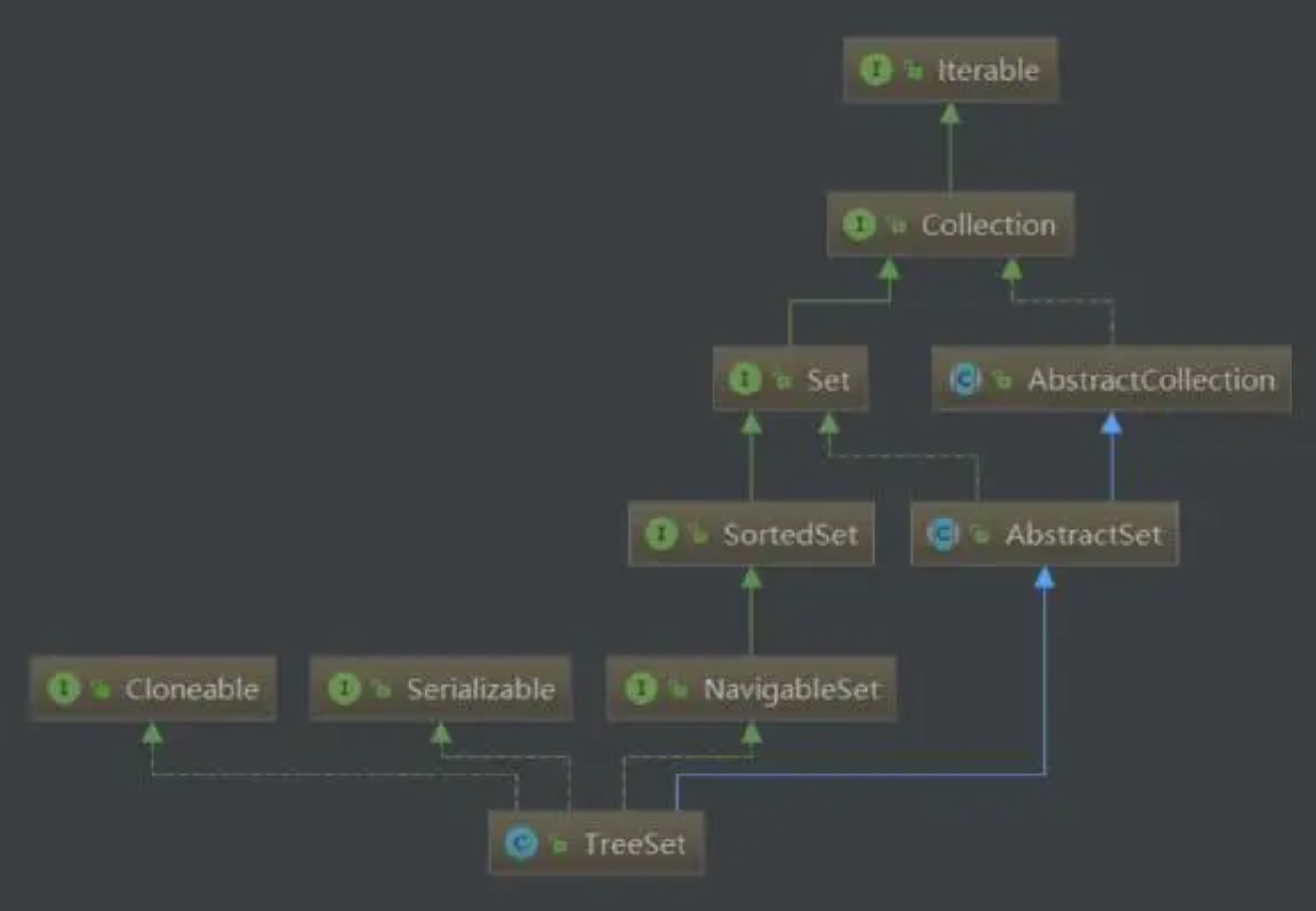
-
使用 TreeSet,需要元素类型实现 Comparable 接口并重写 compareTo 方法,或者提供 Comparator。
-
TreeSet 会自动排序(自然顺序),因为红黑树本身就是一颗二叉查找树,但也是无序的(存与取的顺序不同)。
-
package com.collection; import java.util.TreeSet; /** * @author Petrel */ public class Simple15 { public static void main(String[] args) { // TreeSet<Integer> set = new TreeSet<>(); // set.add(123); // set.add(789); // set.add(456); // set.add(123); // System.out.println(set); TreeSet<Person2> person = new TreeSet<>(); person.add(new Person2("zhangsan", 16)); person.add(new Person2("zhangsan", 18)); person.add(new Person2("lisi", 23)); person.add(new Person2("wangwu", 35)); System.out.println(person); } } class Person2 implements Comparable<Person2> { private String name; private int age; public Person2(String name, int age) { this.name = name; this.age = age; } public Person2() { } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person2{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public int compareTo(Person2 o) { return this.name.compareTo(o.name); } }
-


















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











