




转载请注明出处:https://thinkgamer.blog.youkuaiyun.com/article/details/100996744
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
引言
神经网络中的网络优化和正则化问题介绍主要分为一,二,三,四篇进行介绍。
- 第一篇包括
- 网络优化和正则化概述
- 优化算法介绍
- 第二篇包括
- 参数初始化
- 数据预处理
- 逐层归一化
- 第三篇包括
- 超参数优化
- 第四篇包括
- 网络正则化
概述
虽然神经网络有比较强的表达能力,但是应用神经网络到机器学习任务时仍存在一些问题,主要分为:
- 网络优化
神经网络模型是一个非凸函数,再加上神经网络中的梯度消失和梯度爆炸,很难进行优化,另外网络的参数比较多,且数据量比较大导致训练效率比较低。
- 正则化
神经网络拟合能力强,容易在训练集上产生过拟合,需要一些正则化的方法来提高网络的泛化能力。
从大量的实践经验看主要是从网络优化和正则化两个方面提高学习效率并得到一个好的网络模型。
在低维空间的非凸优化问题中主要是存在一些局部最优点,基于梯度下降优化算法会陷入局部最优点,因此低维空间的非凸优化的难点在于如何选择合适的参数和逃离局部最优点。
深层神经网络中参数较多,其是在高维空间的非凸优化问题中,和低维空间的非凸优化有些不同,其主要难点在于如何逃离鞍点(Saddle Point),鞍点的梯度为0,但是在一些维度上是最高点,在另一些维度上是最低点,如下图所示(图1-1):
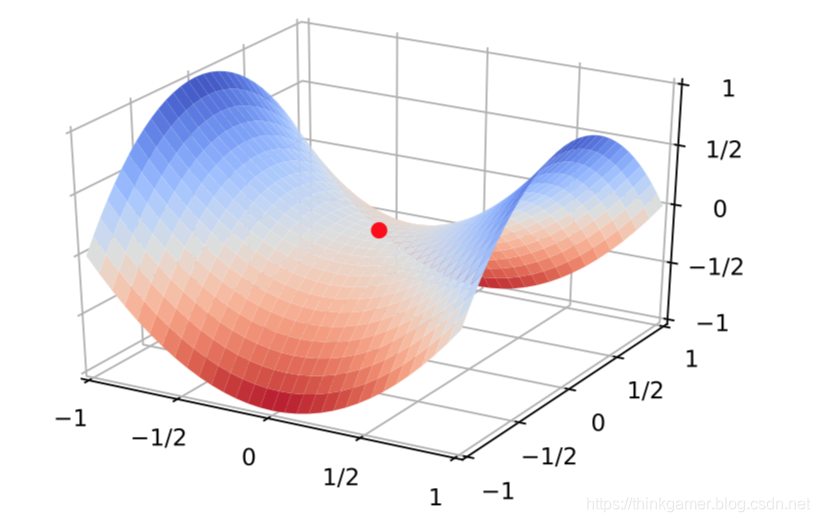
在高维空间中,局部最优点要求在每一维度上都是最低点,这种概率很低,假设网络有1000
个参数,每一维上取得局部最优点的最小概率为p,则在整个参数空间中取得局部最优点的最小概率为
p
1000
p^{1000}
p1000,这种概率很小,也就是说在整个参数空间中,大部分梯度为0的点都是鞍点。
优化算法介绍
深层神经网络的参数学习主要是通过梯度下降算法寻找一组最小结构的风险参数,梯度下降分为:
- 批量梯度下降
- 随机梯度下降
- 小批量梯度下降
根据不同的数据量和参数量,可以选择一种合适的梯度下降优化算法,除了在收敛效果和效率上的区别,这三种梯度下降优化算法还存在一些共同问题(具体会在下一篇进行详细介绍):
- 如何初始化参数
- 预处理数据
- 如何选择合适的学习率,避免陷入局部最优
在训练深层神经网络时,通常采用小批量梯度下降算法。令
f
(
x
,
θ
)
f(x,\theta)
f(x,θ)为一个深层神经网络,
θ
\theta
θ为网络参数,使用小批量梯度优化算法时,每次选择K个训练样本
I
t
=
{
(
x
t
,
y
t
)
}
,
t
∈
(
1
,
T
)
I_t =\left \{ (x^t,y^t) \right \} , t \in (1,T)
It={(xt,yt)},t∈(1,T),第t次迭代时损失函数关于
θ
\theta
θ的偏导数为(公式1-1):
g
t
(
θ
)
=
1
K
∑
(
x
t
,
y
t
)
∈
I
t
∂
L
(
y
t
,
f
(
x
t
,
θ
)
)
∂
θ
g_t(\theta ) = \frac{ 1 }{ K } \sum_{ (x^t,y^t) \in I_t} \frac{ \partial L(y^t,f(x^t, \theta)) }{ \partial \theta }
gt(θ)=K1(xt,yt)∈It∑∂θ∂L(yt,f(xt,θ))
第t次更新的梯度
g
t
′
g'_t
gt′定义为(公式1-2):
g
t
′
(
θ
)
=
g
t
(
θ
t
−
1
)
g_t'(\theta)= g_t(\theta_{t-1})
gt′(θ)=gt(θt−1)
使用梯度下降来更新参数(公式1-3):
θ
t
=
θ
t
−
1
−
α
g
′
(
θ
)
\theta_t = \theta_{t-1} - \alpha g'(\theta)
θt=θt−1−αg′(θ)
一般批量较小时,需要选择较小的学习率,否则模型不会收敛。下图(图1-2)给出了在Mnist数据集上批量大小对梯度的影响。从图1-2(a)可以看出,批量大小设置的越大,下降的越明显,并且下降的比较平滑,当选择批量的大小为1时,整体损失呈下降趋势,但是局部比较震荡。从图1-2(b)可以看出,如果按整个数据集上的迭代次数(Epoch)来看损失变化情况,则是批量样本数越小,下降效果越明显。
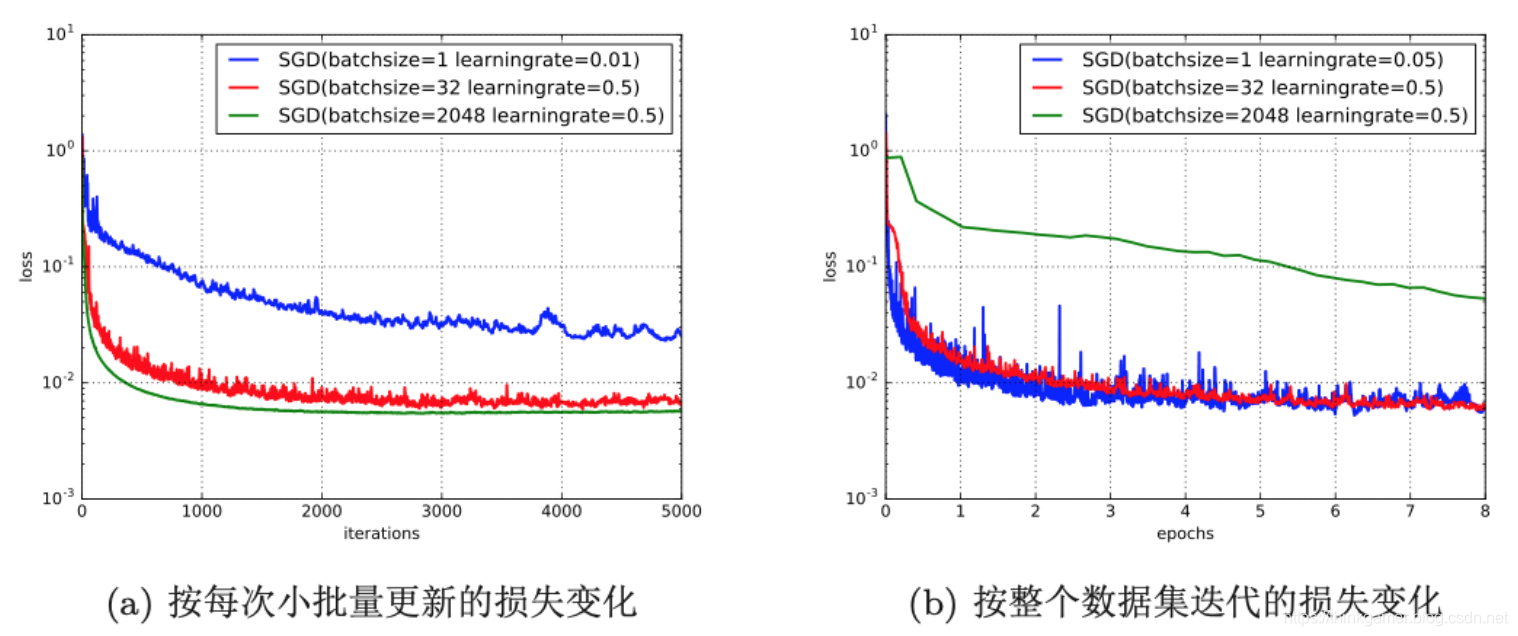
为了更加有效的训练深层神经网络,在标准的小批量梯度下降算法中,经常使用一些改进方法加快优化速度,常见的改进方法有两种:
- 学习率衰减
- 梯度方向优化
这些改进的优化方法也同样可以应用在批量梯度下降算法和随机梯度下降算法。
学习率衰减
在梯度下降中,学习率的设置很重要,设置过大,则不会收敛,设置过小,则收敛太慢。从经验上看,学习率在一开始要设置的大些来保证收敛速度,在收敛到局部最优点附近时要小些来避免震荡,因此比较简单的学习率调整可以通过学习率衰减(Learning Rate Decay)的方式来实现。假设初始学习率为 α 0 \alpha_0 α0,第t次迭代的学习率为 a t a_t at,常用的衰减方式为按照迭代次数进行衰减,例如
- 逆时衰减(公式1-4)
a t = a 0 1 1 + β t a_t = a_0 \frac{1 }{ 1 + \beta t} at=a01+βt1
- 指数衰减(公式1-5)
a t = a 0 β t a_t = a_0\beta^t at=a0βt
- 自然指数衰减(公式1-6)
a
t
=
a
0
e
x
p
(
−
β
∗
t
)
a_t = a_0 exp(-\beta * t)
at=a0exp(−β∗t)
其中
β
\beta
β为衰减率,一般为0.96
AdaGrad
AdaGrad(Adaptive Gradient)算法是借鉴L2正则化的思想,每次迭代时自适应的调整每个参数的学习率。AdaGrad的参数更新公式为(公式1-7):
G
t
=
∑
t
=
1
T
g
t
⊙
g
t
△
θ
t
=
−
α
G
t
+
ϵ
⊙
g
t
g
t
′
(
θ
)
=
g
t
(
θ
t
−
1
)
+
△
θ
t
G_t = \sum_{t=1}^{T} g_t \odot g_t \\ \bigtriangleup \theta_t = - \frac{\alpha }{ \sqrt{G_t + \epsilon } } \odot g_t \\ g'_t(\theta) = g_t(\theta_{t-1}) + \bigtriangleup \theta_t
Gt=t=1∑Tgt⊙gt△θt=−Gt+ϵα⊙gtgt′(θ)=gt(θt−1)+△θt
其中
α
\alpha
α为学习率,
ϵ
\epsilon
ϵ是为了保证数据稳定性而设置的非常小的常数,一般取值是
e
−
7
e^{-7}
e−7到
e
−
10
e^{-10}
e−10,这里的开平方,加,除运算都是按照元素进行的操作。
在AdaGrad算法中,如果某个参数的偏导数累积比较大,其学习率相对较小,相反,如果其偏导数累积比较大,其学习率相对较大。但是整体上随着迭代次数的增加,学习率逐渐减小。
AdaGrad算法的缺点是在经过一定次数的迭代后依然没有找到最优点,由于这时候的学习率已经很小了,就很难找到最优点。
RMSProp
RMSProp是Geoff Hinton提出的一种自适应学习率的方法,可以在有些情况下避免AdaGrad的学习率单调递减以至于过早衰减的缺点。
RMSProp算法首先计算的是每次迭代速度
g
t
g_t
gt平方的指数衰减移动平均,如下所示(公式1-8):
G
t
=
β
G
t
−
1
+
(
1
−
β
)
g
t
⊙
g
t
=
(
1
−
β
)
∑
t
=
1
T
β
T
−
t
g
t
⊙
g
t
G_t = \beta G_{t-1} + (1-\beta) g_t \odot g_t = (1- \beta) \sum_{t=1}^{T} \beta ^{T-t} g_t \odot g_t
Gt=βGt−1+(1−β)gt⊙gt=(1−β)t=1∑TβT−tgt⊙gt
其中
β
\beta
β为衰减率,一般取值为0.9,RMSProp算法参数更新公式为(公式1-9):
△
θ
t
=
−
α
G
t
+
ϵ
⊙
g
t
g
t
′
(
θ
)
=
g
t
(
θ
t
−
1
)
+
△
θ
t
\bigtriangleup \theta_t = - \frac{\alpha }{ \sqrt{G_t + \epsilon } } \odot g_t \\ g'_t(\theta) = g_t(\theta_{t-1}) + \bigtriangleup \theta_t
△θt=−Gt+ϵα⊙gtgt′(θ)=gt(θt−1)+△θt
其中
α
\alpha
α为学习率,通常为0.001。
从公式1-8 可以看出,RMSProp和AdaGrad的区别在于 G t G_t Gt的计算由累积方式变成了指数衰减移动平均,在迭代过程中,每个参数的学习率并不是呈衰减趋势,即可以变大,也可以变小。
AdaDelta
AdaDelta算法也是AdaGrad算法的一个改进,和RMSProp算法类似,AdaDelta算法通过梯度平方的指数衰减移动平均来调整学习率,除此之外,AdaDelta算法还引入了每次参数更新差 △ θ \bigtriangleup \theta △θ的平方的指数衰减移动平均。
第t次迭代时,每次参数更新差
△
θ
t
,
1
<
t
<
T
−
1
\bigtriangleup \theta_t , 1<t<T-1
△θt,1<t<T−1的指数衰减移动平均为(公式1-10):
△
X
t
−
1
2
=
β
1
△
X
t
−
2
2
+
(
1
−
β
)
△
θ
t
−
1
⊙
△
θ
t
−
1
\bigtriangleup X^2_{t-1} =\beta _1 \bigtriangleup X^2_{t-2} + (1 - \beta) \bigtriangleup \theta_{t-1} \odot \bigtriangleup \theta_{t-1}
△Xt−12=β1△Xt−22+(1−β)△θt−1⊙△θt−1
其中
β
1
\beta_1
β1为衰减率,AdaDelta算法的参数更新差值为(公式1-11):
△
θ
t
=
−
△
X
t
−
1
2
+
ϵ
G
t
+
ϵ
g
t
\bigtriangleup \theta_t = - \frac{\sqrt {\bigtriangleup X^2_{t-1} + \epsilon }}{ \sqrt {G_t + \epsilon}} g_t
△θt=−Gt+ϵ△Xt−12+ϵgt
其中 G t G_t Gt的计算方式和RMSProp算法一样。从公式1-11可以看出,AdaDelta算法将RMSProp算法中的初始学习率 α \alpha α改为动态计算的 △ X t − 1 2 + ϵ \sqrt {\bigtriangleup X^2_{t-1} + \epsilon } △Xt−12+ϵ,在一定程度上减缓了学习旅率的波动。
梯度方向优化
除了调整学习率外,还可以使用最近一段时间内的平均梯度来代替当前时刻的梯度来作为参数的更新方向,从图1-2中可以看出,在小批量梯度下降中,如果每次选取样本数量比较小,损失就会呈现震荡的方式下降,有效的缓解梯度下降中的震荡的方式是通过用梯度的移动平均来代替每次的实际梯度。并提高优化速度,这就是动量法。
动量法
动量法(Momentum Method)是用之前积累的动量来替代真正的梯度,每次替代的梯度可以看作是加速度。
在第t次迭代时,计算负梯度的“加权移动平均”作为参数的更新方向,如下所示(公式1-12):
△
θ
t
=
ρ
△
θ
t
−
1
−
α
g
t
\bigtriangleup \theta_t = \rho \bigtriangleup \theta_{t-1}-\alpha g_t
△θt=ρ△θt−1−αgt
其中
ρ
\rho
ρ为动量因子,通常设置为0.9,
α
\alpha
α为学习率。
参数的实际更新值取决于最近一段时间内梯度的加权平均值。当某个参数在最近一段时间内梯度方向不一致时,参数更新的幅度变小,相反,参数更新的幅度变大,起到加速的作用。
一般而言,在迭代初期,梯度的更新方向比较一致,动量法会起到加速作用,可以更快的起到加速的作用,可以更快的到达最优点,在迭代后期,梯度的更新方向不一致,在收敛时比较动荡,动量法会起到减速作用,增加稳定性。从某种程度来讲,当前梯度叠加上部分的上次梯度,一定程度上可以看作二次梯度。
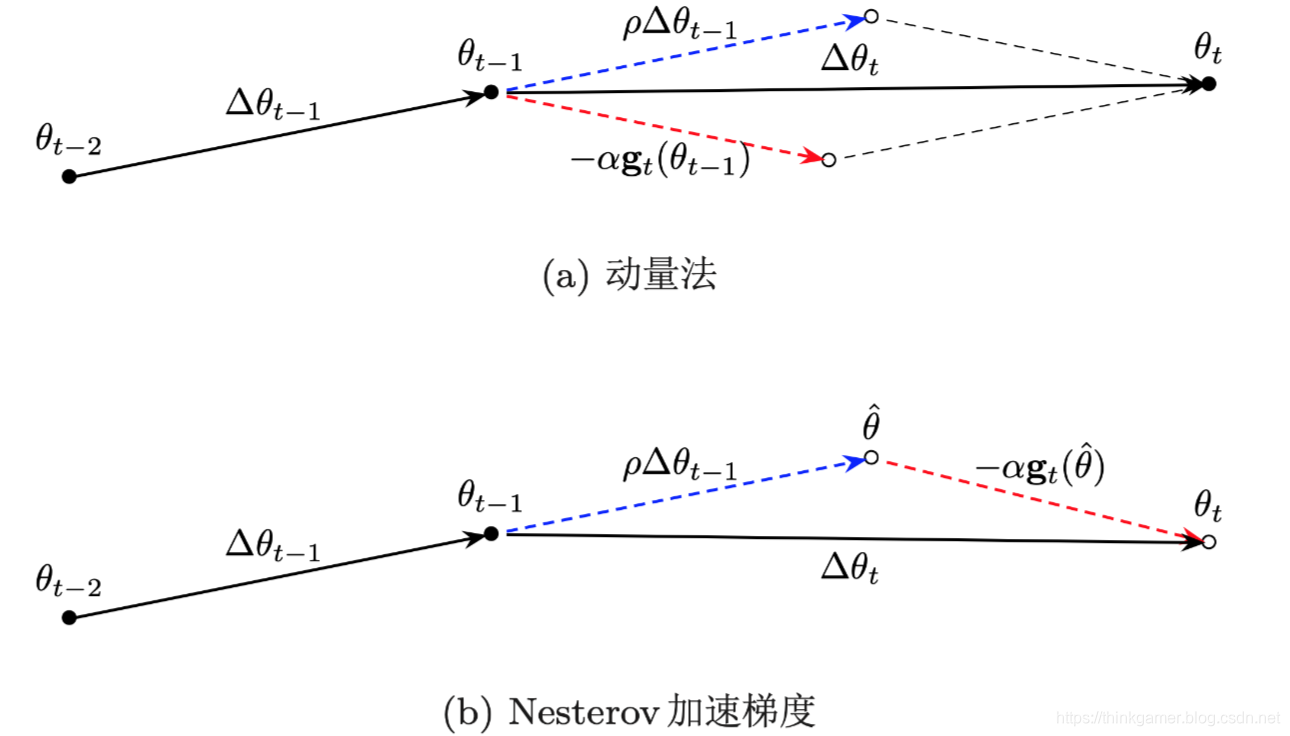
Nesterov加速梯度
Nesterov加速梯度(Nesterov Accelerated Gradient, NAG)也叫Nesterov动量法(Nesterov Momentum),是一种对动量法的改进。
在动量法中,实际的参数更新方向
△
θ
t
\bigtriangleup \theta_t
△θt为上一步的参数更新方向
△
θ
t
−
1
\bigtriangleup \theta_{t-1}
△θt−1和当前的梯度
−
g
t
-g_t
−gt的叠加,这样,
△
θ
t
\bigtriangleup \theta_t
△θt可以拆分为两步进行,先根据
△
θ
t
−
1
\bigtriangleup \theta_{t-1}
△θt−1更新一次得到参数
θ
~
\tilde{\theta }
θ~,再用
g
t
g_t
gt进行更新,如下所示(公式1-13):
θ
~
=
θ
t
−
1
+
ρ
△
θ
t
−
1
θ
t
=
θ
~
−
α
g
t
\tilde{\theta } = \theta_{t-1} + \rho \bigtriangleup \theta_{t-1} \\ \theta_t = \tilde{\theta } - \alpha g_t
θ~=θt−1+ρ△θt−1θt=θ~−αgt
其中
g
t
g_t
gt为点
θ
t
−
1
\theta_{t-1}
θt−1上的梯度,所以第二步不太合理,更合理的更新方向为
θ
~
\tilde{\theta }
θ~上的梯度,这样合并后的更新方向为(公式1-14):
△
θ
t
=
ρ
△
θ
t
−
1
−
α
g
t
(
θ
t
−
1
+
ρ
△
θ
t
−
1
)
\bigtriangleup \theta_t = \rho \bigtriangleup \theta_{t-1} -\alpha g_t(\theta_{t-1} + \rho \bigtriangleup \theta_{t-1} )
△θt=ρ△θt−1−αgt(θt−1+ρ△θt−1)
其中
g
t
(
θ
t
−
1
+
ρ
△
θ
t
−
1
)
g_t(\theta_{t-1} + \rho \bigtriangleup \theta_{t-1} )
gt(θt−1+ρ△θt−1)表示损失函数在
θ
~
=
θ
t
−
1
+
ρ
△
θ
t
−
1
\tilde{\theta } = \theta_{t-1} + \rho \bigtriangleup \theta_{t-1}
θ~=θt−1+ρ△θt−1上的偏导数。
下图(图1-3)给出了动量法和 Nesterov 加速梯度在参数更新时的比较:
AdaM算法
自适应动量估计算法(Adaptive Moment Estimation,Adam)可以看作是动量法和RMSprop的结合,不但使用动量作为参数更新,而且可以自适应调整学习率(公式1-15)。
M
t
=
β
1
M
t
−
1
+
(
1
−
β
1
)
g
t
G
t
=
β
2
G
t
−
1
+
(
1
−
β
2
)
g
t
⊙
g
t
M_t = \beta _1M_{t-1} + (1-\beta _1)g_t \\ G_t = \beta _2 G_{t-1} + (1-\beta _2)g_t \odot g_t
Mt=β1Mt−1+(1−β1)gtGt=β2Gt−1+(1−β2)gt⊙gt
其中
β
1
,
β
2
\beta_1 ,\beta_2
β1,β2分别为两个移动平均的衰减率,通常取值:
β
1
=
0.9
,
β
2
=
0.99
\beta_1=0.9,\beta_2=0.99
β1=0.9,β2=0.99。
M t M_t Mt可以看作是梯度的均值(一阶矩), G t G_t Gt可以看作是梯度的未减去均值的方差(二阶矩)。
假设
M
t
=
0
,
G
t
=
0
M_t =0,G_t=0
Mt=0,Gt=0,那么在迭代初期,
M
t
,
G
t
M_t,G_t
Mt,Gt的值会比真实的均值和方差要小,特别是当
β
1
,
β
2
\beta_1 ,\beta_2
β1,β2都接近1时,偏差会很大,因此需要对偏差进行修正,如下所示(公式1-16):
M
t
~
=
M
t
1
−
β
1
t
G
t
~
=
G
t
1
−
β
2
t
\tilde{M_t} = \frac{M_t}{ 1 - \beta^t _1} \\ \tilde{G_t} = \frac{G_t}{ 1 - \beta^t _2}
Mt~=1−β1tMtGt~=1−β2tGt
Adam算法的更新差值为(公式1-17):
△
θ
t
=
−
α
G
t
~
+
ε
M
t
~
\bigtriangleup \theta_t = - \frac{\alpha }{\sqrt{ \tilde{G_t} + \varepsilon }} \tilde{M_t}
△θt=−Gt~+εαMt~
其中学习率
α
\alpha
α通常设置为0.001,并且也可以进行衰减,比如
a
t
=
a
0
t
a_t = \frac{a_0} { \sqrt{t}}
at=ta0。
Adam算法是RMSprop与动量法的结合,因此一种自然的Adam改进方法是引入Nesterov加速梯度,称为Nadam算法。
梯度截断
在深层神经网络或者循环网络中,除了梯度消失之外,梯度爆炸是影响学习效率的主要隐私,在基于梯度下降的优化过程中,如果梯度突然增大,用较大的梯度更新参数,反而会使结果远离最优点,为了避免这种情况,当梯度达到一定值的时候,要进行梯度截断(gradient clipping)。
梯度截断是一种比较简单的启发式方法,把梯度的模限定在一个范围内,当梯度的模大于或者小于某个区间时,就进行截断,一般截断的方式有以下几种:
- 按值截断
在第t次迭代时,梯度为 g t g_t gt,给的一个区间[a,b],如果梯度小于a时,令其为a,大于b时,令其为b。
- 按模截断
将梯度的模截断到一个给定的截断阈值b。如果 ∣ ∣ g t ∣ ∣ 2 ≤ b ||g_t||^2 \leq b ∣∣gt∣∣2≤b保持梯度不变,如果 ∣ ∣ g t ∣ ∣ 2 > b ||g_t||^2 > b ∣∣gt∣∣2>b,则 g t = b ∣ ∣ g t ∣ ∣ g t g_t= \frac{ b}{||g_t||} g_t gt=∣∣gt∣∣bgt。
截断阈值 b 是一个超参数,也可以根据一段时间内的平均梯度来自动调整。实验中发现,训练过程对阈值 b 并不十分敏感,通常一个小的阈值就可以得到很好的结果。
在训练循环神经网络时,按模截断是避免梯度爆炸的有效方法。
优化算法总结
本文介绍了神经网络中的网络优化和正则化概述,以及网络优化中的加快网络优化的两种方法,这些方法大体分为两类:
- 调整学习率,使得优化更稳定
比如:AdaGrad,RMSprop,AdaDelta
- 调整梯度方向,优化训练速度
比如:动量法,Nesterov加速梯度,梯度截断
Adam则是RMSprop 和 动量法的结合。



















 2794
2794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









